# JAVA 概述
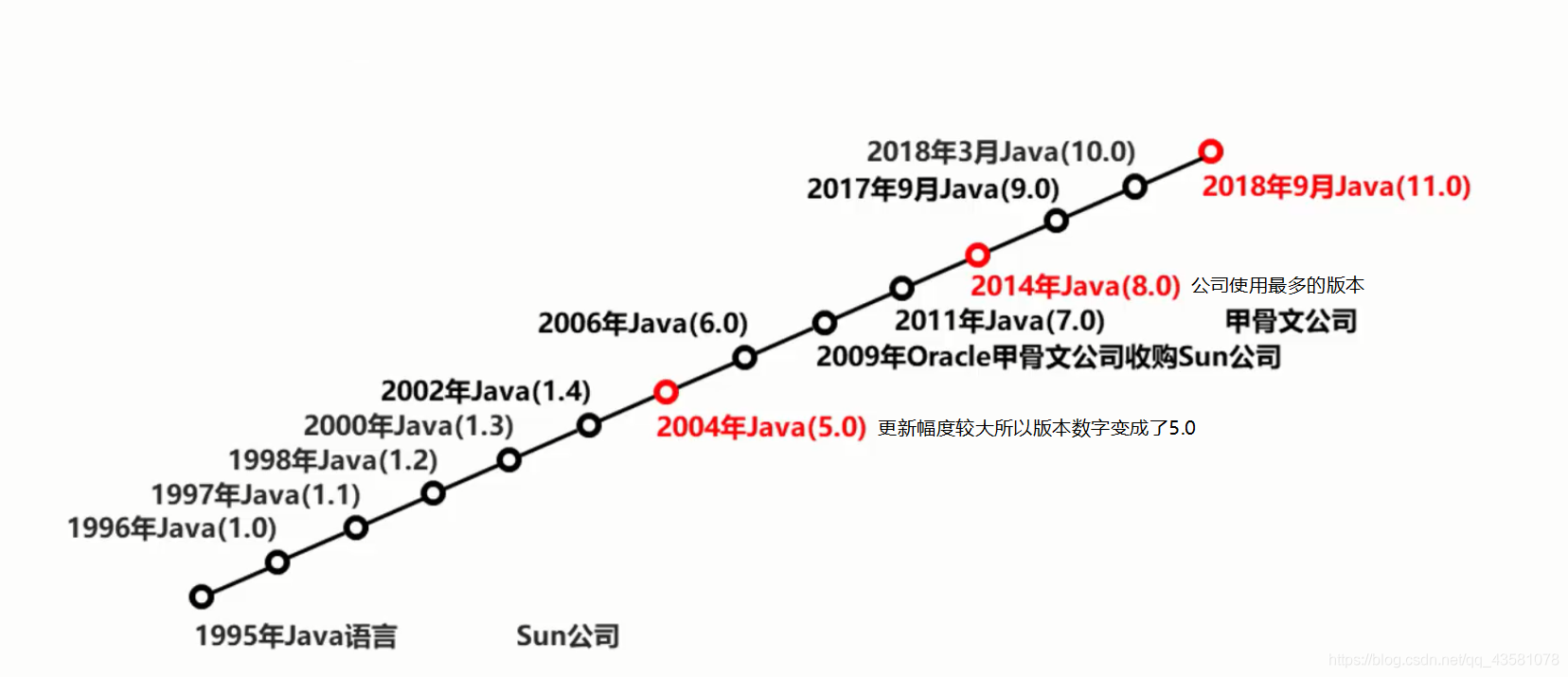
# 发展史
- JDK1.8和JDK8是同一个版本 ,最开始命名为 JDK1.1、JDK1.2....后来就 命名为 JDK7、JDK8....
- SE(J2SE),standard edition,标准版,是我们通常用的一个版本,从JDK 5.0开始,改名为Java SE
- EE(J2EE),enterprise edition,企业版,主要用于开发企业应用程序,从JDK 5.0开始,改名为Java EE
- ME(J2ME),micro edition,主要用于移动设备、嵌入式设备上的程序,从JDK 5.0开始,改名为Java ME
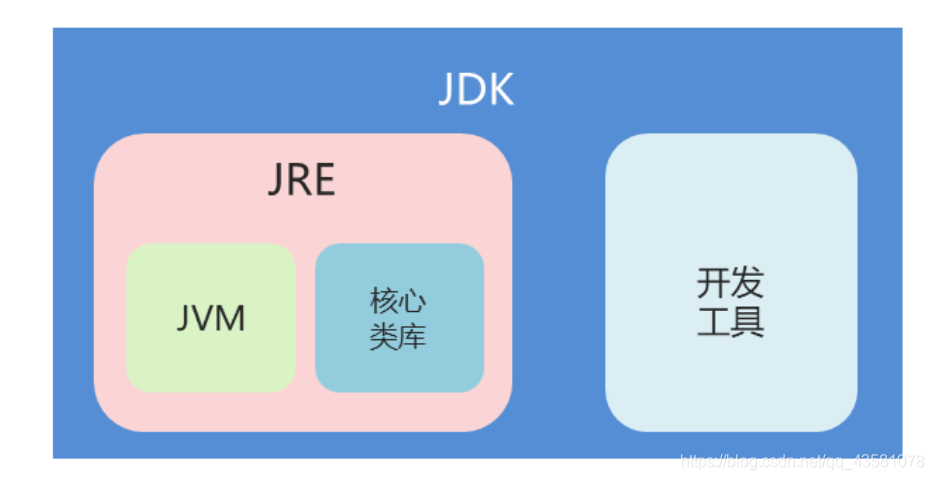
# JVM、JRE和JDK
- JVM(Java Virtual Machine):Java虚拟机,它是由软件技术模拟出计算机运行的一个虚拟的计算机。JVM是跨平台的语言,充当着一个翻译官的角色
- JRE(Java Runtime Environment):是Java程序的运行时环境,包含JVM和运行时所需要的核心类库,我们想要运行一个已有的Java程序,那么只需要安装JRE即可
- JDK(Java Development Kit):是Java程序的开发工具包,包含JRE和开发人员使用的工具。其中的工具包括:编译工具Javac.exe(Javac HlloWorld.java生成HelloWorld.class字节码文件)和运行工具Java.exe(Java HlloWorld),我们想要开发一个全新的Java程序,那么必须要安装JDK。
# 安装配置
- 首先要去官网 (opens new window)下载需要的JDK,然后安装
- 配置环境变量,并查看是否配置成功,键入java-version,javac-version
# 系统变量
JAVA_HOME:C:\Program Files\Java\jdk1.8.0_271 # jdk的安装路径
# 环境变量
classpath:.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\tools.jar
Path:%JAVA_HOME%\bin # 最后一行新增
- Linux系统配置
vim /etc/profile
# 环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_401
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
# 刷新配置文件
source /etc/profile
# 验证安装
java -version
# Java中的包
# package和import
- 包其实就是文件夹,其作用是对类进行分类管理
- 格式:package 包名(多级包用 . 分开),例:package com.demo =>C# namespace
- 使用不同包下的类时,需要导包:import 包名,例:import com.demo =>C# using
# 在idea中手动编译带包的文件
- 在com/demo文件夹下创建类:Hello.java(会自动引用包 com.demo)
- 在idea的项目结构中右键该Hello.java文件,在菜单栏选中Open in Terminal,打开idea自带的命令行工具,路径默认为该文件所在路径
- 编译Java文件:javac Hello.java,生成可执行文件.class文件(字节码文件)
- 在idea的项目结构中右键该java文件的包所在的文件夹,即src文件夹,在菜单栏选中Open in Terminal,路径默认为该文件夹所在路径
- 带包执行:java com.demo.Hello
# javac -d参数
-d是为了指定输出目录
例如:javac -d ./classes HelloWorld.java 就意味着把HelloWorld.java编译后的字节码文件放在当前目录下classes子目录中
不带包的文件在当前目录下生成class文件,一般情况下有两种方法:
- 方法一: javac Hello.java
- 方法二: javac -d . Hello.java
带包的文件
- javac的 -d参数用于指定生成class文件的位置,.(点号)表示当前目录
- "-d ."应该这样理解更准确:在当前目录上编译生成java包
//当前目录是d:\temp,d:\temp下有个中类hello.java如下
package org.Hello;
public class hello{
static public void main(String[] args){
System.out.println("hello world");
}
}
//方法一,运行 javac hello.java,生成hello.class文件在d:\temp目录下
//方法二,运行 javac -d . hello.java,生成hello.class文件在d:\temp\org\Hello
# java反编译
- 通过javac命令生成字节码文件 hello.class
- 使用javap hello.class就可以看到反编译的代码
# main函数
java运行时,是通过main函数作为主入口开始运行的,args这个参数是Java命令行参数
当你使用Java命令行来运行程序时,如果在后面带上参数,Java的虚拟机就直接把这些参数存放到args数组中了,完成了命令行传参
//使用java命令运行程序,并使用参数传参:java test this is test
public class test {
public static void main(String[] args) {
for(int i=0;i<args.length;i++){
System.out.println("args["+i+"]="+args[i]);
}
}
}
//输出:args[0]=this args[1]=is args[2]=test
# 运行jar包
- 本地安装 nohup 下载地址 (opens new window)
# 解压源码
tar -zxvf coreutils-x.x.tar.xz
cd coreutils-x.x
# 配置编译环境(需已安装 gcc, make 等工具)
# GNU软件通常不建议以root用户运行configure和make,因为这样可能会覆盖系统文件,存在安全风险
export FORCE_UNSAFE_CONFIGURE=1 # 设置环境变量绕过检查
./configure
# 编译
make
# 安装(需要 root 权限)
sudo make install
# 查看安装路径
which nohup
# 确认版本
nohup --version
- 后台运行 jar 包
nohup java -jar your-application.jar > output.log 2>&1 &
nohup # 即"No Hang Up",即不挂断地运行命令
java -jar your-application.jar # 运行jar文件
> output.log # 将标准输出重定向到output.log文件
2>&1 # 将标准错误(2)重定向到标准输出(1)
jps -l # 会显示完整的包名和端口号
ps -ef | grep java # 查看系统当前所有Java进程
lsof nohup.out # 检查 nohup.out 文件关联的进程
ps -p <PID> # 检查进程
kill <PID> # 终止进程
# 数据类型
# 基本数据类型
Java的8种基本数据类型
- 整数类型:long、int、short、byte
- 浮点类型:float、double
- 字符类型:char
- 布尔类型:boolean

# 引用数据类型
引用数据类型非常多,大致包括:类、接口、数组、枚举、注解、字符串
String类型就是引用类型,简单来说,所有的非基本数据类型都是引用数据类型
# 二者区别
# 存储位置
- 基本变量类型:变量的具体内容是存储在栈中的
- 引用变量类型:变量的具体内容都是存放在堆中的,而栈中存放的是其具体内容所在内存的地址
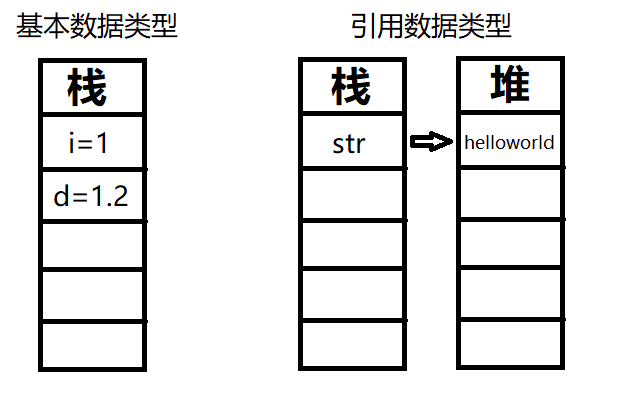
# 传递方式
- 基本变量类型:对于基本数据类型的参数,形式参数的改变,不影响实际参数的值
//基本数据类型作为方法参数被调用
public class Main{
public static void main(String[] args){
int msg = 100;
System.out.println("调用方法前msg的值:\n"+ msg); //100
fun(msg);
System.out.println("调用方法后msg的值:\n"+ msg); //100
}
public static void fun(int temp){
temp = 0;
}
}
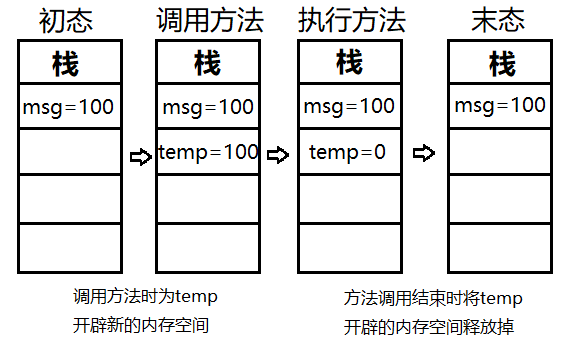
- 引用变量类型:
//引用数据类型作为方法参数被调用
class Book{
String name;
double price;
public Book(String name,double price){
this.name = name;
this.price = price;
}
public void getInfo(){
System.out.println("图书名称:"+ name + ",价格:" + price);
}
public void setPrice(double price){
this.price = price;
}
}
public class Main{
public static void main(String[] args){
Book book = new Book("Java开发指南",66.6);
book.getInfo(); //图书名称:Java开发指南,价格:66.6
fun(book);
book.getInfo(); //图书名称:Java开发指南,价格:99.9
}
public static void fun(Book temp){
temp.setPrice(99.9);
}
}
调用时为temp在栈中开辟新空间,并指向book的具体内容,方法执行完毕后temp在栈中的内存被释放掉

# 基本类型包装类
将基本类型封装成对象的好处在于可以在对象中定义更多的功能来操作该数据
除了char和int,剩下的包装类都是基本数据类型首字母大写

# 基本类型和包装类型的区别
- 声明方式不同
- 基本类型直接声明,而包装类型需使用new关键字来在堆中分配内存空间
- 存储方式及位置不同
- 基本类型存储在栈中,而包装类型存储在堆中通过引用
- 初始值不同
- 基本类型初始值,int为0,boolean为false,包装类型初始值为null
- 使用方式不同
- 基本类型直接赋值使用,包装类型在集合、泛型时会使用
# 自动装箱和拆箱
- 装箱:把基本数据类型转换为对应的包装类类型。自动装箱:Integer i = 100
- 拆箱:把包装类类型转换为对应的基本数据类型。自动拆箱:i+200
注意
只要是对象,在使用前就必须进行不为null的判断
# 枚举类型
//简单枚举类型
public enum Color
{
RED, GREEN, BLUE;
}
//复杂枚举类型
public enum Action {
//枚举的定义需要在类中的第一行代码
ADD("0", "新增"),
UPDATE("1", "更新"),
DELETE("2", "取消/删除"),
ZERO("0", "零"),
ONE("1", "壹");
private String value;
private String label;
//如果枚举值中还有数据则必须要创建一个构造函数
Action(String value, String label) {
this.value = value;
this.label = label;
}
public String value() {
return value;
}
public String label() {
return label;
}
}
注意
如果枚举值中含有值则必须要创建构造函数,以便枚举类创建的时候调用构造函数赋值。
构造函数必须是私有的private,private修饰符对于构造器是可以省略的,但这不代表构造器的权限是默认权限。
//方法演示
public static void main(String[] args) {
Action update = Action.UPDATE;
//得到此枚举常量的名称
System.out.println(update.name()); //UPDATE
//得到此枚举常量的声明次序,从0开始
System.out.println(update.ordinal()); //1
//优先使用toString方法
System.out.println(update.toString());//UPDATE
}
# 变量使用
- 整数类型默认为int,浮点类型默认为double
- long类型的变量定义的时候,为了防止整数过大,后面要加L。long a = 1000000000L
- float类型的变量定义的时候,为了防止类型不兼容,后面要加F。 float f = 13.14F
- 变量名称是区分大小写的。Class可以,class不可以
- 小驼峰:方法和变量;大驼峰:类
# 自动类型转换
把一个数据范围小的变量赋值给另一个数据范围大的变量,例:double d = 10

# 强制类型转换
把一个数据范围大的变量赋值给另一个数据范围小的变量,例:int i = (int)88.88
# 运算符
- 字符char的"+"操作是拿字符在计算机底层对应的数值来计算的。10+'a' = 107 a是97
- 字符串连续进行"+"操作时,从左到右逐个执行。1+99+"abc" = 100abc
- 扩展的赋值运算:+=(加后赋值) -=(减后赋值) *=(乘后赋值) /=(除后赋值) %=(取余后赋值)扩展的赋值运算符底层隐含了强制类型转换
int i=10;
i+=20; //输出30
i=i+20; //正常
short i=10;
i+=20; //输出30
i=i+20; //报错 需要类型转换 i=(short)(i+20)
//注意 自增和自减
int i = 10;
int j = i++; //i=11 j=10 先把i赋值给j 再++
int j = ++i; //i=11 j=11 先把i++ 再赋值给j
- 逻辑运算符
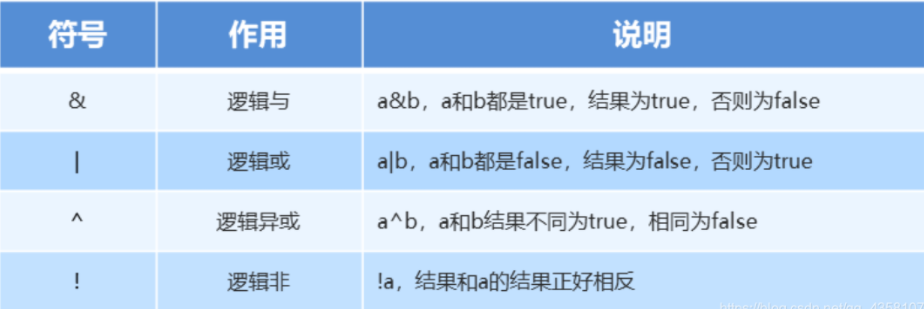
- 短路逻辑运算符:&&和||,和逻辑运算符&和|的区别是:有可能只执行左边不执行右边
int i = 10;int j = 20;
i++ > 100 && j++ >100; //此时i=11 j=20,左边为false时不执行右边
i++ < 100 || j++ <100; //此时i=11 j=20,左边为true时不执行右边
使用 == 作比较时
- 基本类型:比较的是数据值是否相同
- 引用类型:比较的是地址值是否相同,比较值必须使用a.equals(b)或Objects.equals(a,b)
# 数组使用
数组必须先初始化才能使用,即给数组中的元素分配内存空间,并为每个元素赋值
# 动态初始化
只指定数组长度,由系统为数组分配初始值
int[] da = new int[3];
da[0] = 1; da[1] = 3; da[2] = 5;
# 静态初始化
可以不声明其大小,但由于所有元素已经确定
int[] sa = {1, 3, 5};
注意
数组作为参数进行传递时,必须要先使用大括号初始化
String[] str= {"aaa"}
不能直接写hello.test({"aaa"})
hello.test(str)
# 判断一个数组中是否含有某个字符串
String[] bArray = new String[]{"1","90","91","92","4","5","93","102","96","103","2"};
List aList = Arrays.asList(aArray);
System.out.println(aList.contains("111")
# spit的使用
str.split("\\|");
# 循环的使用
- do{ }while() 至少执行一次
- continue跳出当次循环,继续下一次的执行,break跳出整个循环
# 数据集合
- 使用长度固定的数组格式不一定满足我们的需求,集合类存储的数据容量可以随时发生改变
- 集合中存储的是任意一种引用数据类型,泛型。ArrayList< String >、ArrayList< Student >

集合存储数据的方式有单列和双列
- 单列:Collection
List # 有序的,可以存储重复的数据
ArrayList # List的实现类,查询效率高,增删效率低
LinkedList # List的实现类,查询效率低,增删效率高
Set # 无序的,可以存储不重复的数据
HashSet # Set的实现类,无序的
LinkedHashSet # Set的实现类,有序的
TreeSet # Set的实现类,顺序可配置的
- 双列:Map
# 数据结构
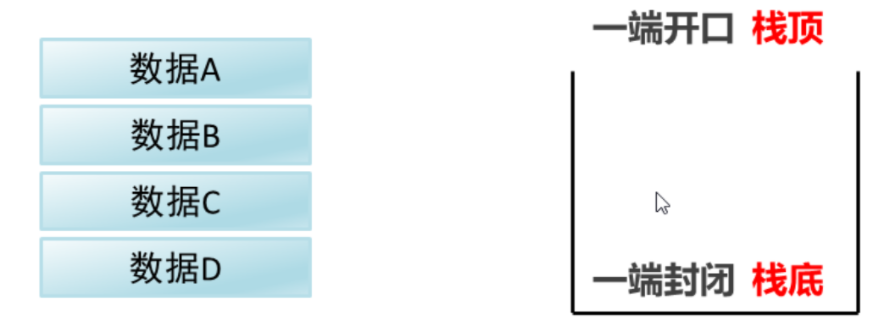
数据结构是计算机存储、组织数据时相互之间存在的一种或多种特定关系。常见的数据结构:
- 栈:先进后出。数据进栈时从A到D,数据出栈是从D到A
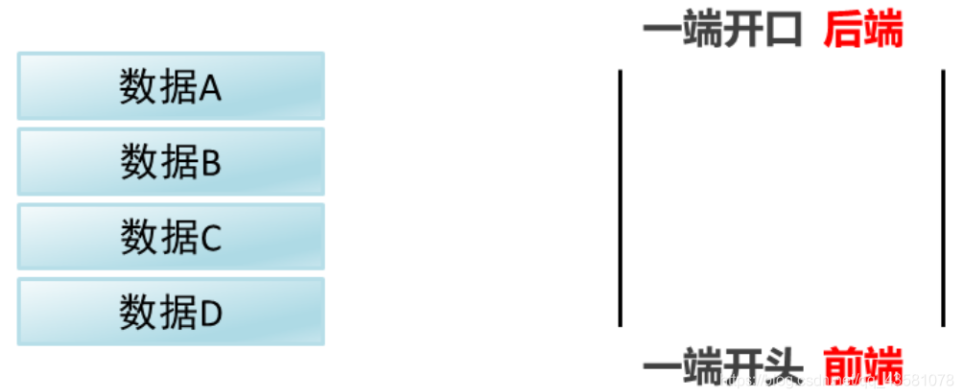
- 队列:先进先出。数据进队列时从A到D,也是数据出队列是从A到D
- 数组:是一种增删慢,查询快的模型(ArrayList)
# 查询效率高:通过索引定位
# 删除效率低:删除原始数据,同时后面每个元素需要前移
# 添加效率极低:添加位置后的每个元素后移,再添加元素
# 在内存中是连续存储的
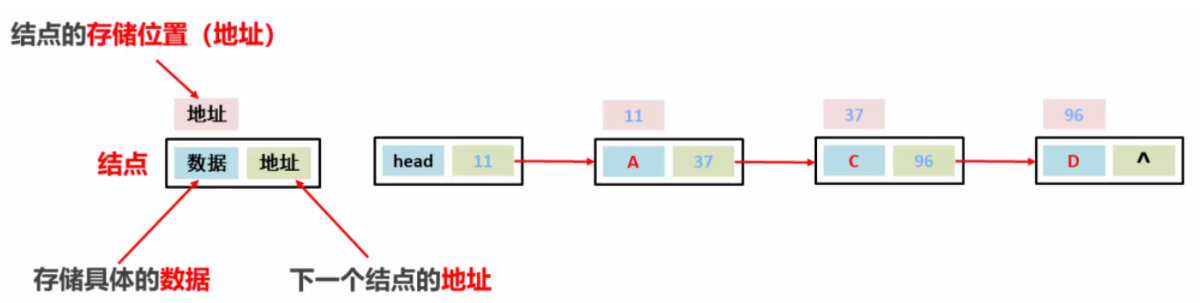
- 链表:是一种增删快,查询慢的模型(LinkedList)
# 查询慢:查询数据必须从头开始查询
# 增删效率快:直接操作当前节点
# 链表中的每个数据都叫节点,每个节点中都包含数据和下一个节点的地址
# 在内存中是离散存储的,不连续的
class Person{
String name;
}
Person person = new Person("张三");
person.next = new Person("李四");
person.next.next = new Person("王五");
// 删除
person.next = person.next.next;
// 添加
Person temPerson = new Person("赵六");
temPerson.next = person.next;
person.next = temPerson;
# Collection 单列
- 是单例集合的顶层接口,它表示一组对象,这些对象也称为Collection的元素
- JDK不提供此接口的任何直接实现,可以使用多态的方式通过具体类(ArrayList、LinkedList)来实现
public class CollectionDemo{
public static void main(String[] args){
Collection<String> c = new ArrayList<String>();
c.add("hello");
c.add("world");
//重写了toString()方法,可以直接输出值,而不是输出地址
System.out.println(c);
}
}
//常用方法
boolean add(E e) //添加元素
boolean remove(Object o) //从集合中移除指定的元素
void clear() //清空集合中的元素
boolean contains(Object o) //判断集合中是否存在指定的元素
boolean isEmpty() //判断集合是否为空
int size() //获取集合的长度,也就是元素的个数
# Iterator 迭代器
- Iterator()方法返回此集合的迭代器,可以用于遍历集合
public class CollectionDemo{
public static void main(String[] args){
Collection<String> c = new ArrayList<String>();
c.add("hello");
c.add("world");
//重写了toString()方法,可以直接输出值,而不是输出地址
System.out.println(c);
//iterator()方法返回此集合的迭代器
Iterator<String> it = c.iterator();
//hasNext() 是否还有元素
while(it.hasNext()){
//next() 返回迭代器中的下一个元素
System.out.println(it.next());
}
}
}
- 要使数组可迭代,需要分别使用 Arrays.asList()或Arrays.stream() 方法将其转换为流或作为列表。才可以使用iterator()方法获取这些对象的迭代器
public class JavaArrayToIterableExample {
public static void main(String[] args) {
String[] names = new String[]{"john", "Amal", "Paul"};
List<String> namesList = Arrays.asList(names);
Iterator<String> it = namesList.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
public class JavaArrayToIterableExampleJava8 {
public static void main(String[] args) {
String[] names = new String[] {"john", "Amal", "Paul"};
Stream<String> namesList = Arrays.stream(names);
Iterator<String> it = namesList.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
}
}
- 并发修改异常:ArrayList在迭代的时候如果同时对其进行修改就会抛出异常
- 产生的原因:迭代器在遍历的过程中,修改了集合中元素的长度,造成了迭代器获取元素中判断预期修改值和实际修改值不一致
- 解决方案:用for循环便利,然后用集合对象做对应的操作
import java.util.ArrayList;
import java.util.Iterator;
public class Test {
public static void main(String[] args) {
ArrayList<String> array = new ArrayList<String>();
// 创建并添加元素
array.add("hello");
array.add("world");
array.add("java");
Iterator it = array.iterator();
while (it.hasNext()) {
String s = (String) it.next();
if ("world".equals(s)) {
//Iterator遍历过程中不能修改集合的长度
array.add("javaee");
}
}
}
}
# Iterable 增强for循环:简化集合的遍历
- 实现Iterable接口的类允许其对象成为增强for语句的目标
- Collection继承Iterable接口。所以Collection体系的集合都可以称为增强目目标
- 它是JDK5之后出现的,其内部原理是一个Iterator迭代器
//示例一
int[] arr = {1,2,3,4,5};
for(int i:arr){
System.out.println(i);
}
//示例二
List<String> list = new ArrayList<String>();
list.add("hello");
list.add("world");
list.add("java");
for(String s:list){
//错误,增强for循环内部原理是一个Iterator迭代器,会产生修改并发错误
list.add(".net");
System.out.println(s);
}
//示例三
public void testForeach() {
Collection<String> collection = new ArrayList<>();
collection.add("i");
collection.add("love");
collection.add("china");
// foreach遍历
collection.forEach(e-> System.out.println(e));
// 可以使用方法引用简写
collection.forEach(System.out::println);
// 或者迭代器的forEachRemaining方法
collection.iterator().forEachRemaining(System.out::println);
}
//示例四
//使用java8的predicate操作集合
public void testPredicate() {
Collection<Integer> collection = new ArrayList<>();
// 添加0-49
for (int i = 0; i < 50; i++) {
collection.add(i);
}
// 移除10-49的数字
collection.removeIf(e -> (e > 9 && e < 50));
System.out.println(collection);// 输出[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
}
# iterable与iterator
- iterable接口中第一个方法用来返回iterator对象,二者的名字很像
- 从英语语法的角度分析iterable是一个形容词代表实现了该接口的对象有可迭代的能力,iterator是一个名词是具体迭代的执行者又称迭代器
- 实现了iterable接口的集合对象通过返回的iterator实现了对该集合的迭代
# List集合
List特有的方法Collection是没有的,但是List的实现类是有的
void add(int index,E elment) //在此集合中的指定位置插入指定的元素
E remove(int index) //删除指定索引处的元素,返回被删除的元素
E set(int index,E element) //修改指定索引处的元素,返回被修改的元素
E get(int index) //返回指定索引处的元素
# ListIterator 迭代器
- 通过List集合的listIterator()方法得到,所以说它是List集合特有的迭代器
- 允许程序员沿任何一个方向遍历,在迭代期间可以修改列表,不会产生并发修改异常
//常用方法
E next() //返回下一个元素
boolean hasNext() //是否还有更多元素
E previous() //返回上一个元素
boolean hasPrevious() //向上是否还有更多元素
void add(E e) //插入指定的元素
//示例
public class ListIteratorDemo{
public static void main(String[] args){
//ArrayList
List<String> list = new ArrayList<String>();
//LinkedList
List<String> list = new LinkedList<String>();
list.add("hello");
list.add("world");
list.add("java");
//通过list集合的listiterator()方法得到
ListIterator<String> it = list.listIterator();
while(it.hasNext()){
//使用ListLIterator的add添加元素
//在迭代的过程中,不会报并发修改异常
it.add(".net");
System.out.println(it.next());
}
while(it.hasPrevious()){
System.out.println(it.previous());
}
}
}
# ArrayList 集合
//常用方法,没有自己特殊的方法,都是List+Collection的方法
boolean add(E e) //将指定的元素添加到次集合的末尾
void add(int index,E element) //在集合的指定位置插入指定的元素
booleam remove(Object o) //删除指定的元素,返回是否成功
E remove(int index) //删除指定索引处的元素,返回被删除的数组
E set(int index,E element) //修改指定索引处的元素,返回被修改的数组
E get(int index) //返回指定索引处的数组
int size() //数组的个数
# LinkedList集合
//特有的功能
public void addFirst<E e> //在该列表开头插入指定的元素
public void addLast<E e> //在该列表结尾插入指定的元素
public E getFirst() //返回此列表的第一个元素
public E getLast() //返回此列表的最后一个元素
public E removeFirst() //从此列表中删除并返回第一个元素
public E removeLast() //从此列表中删除并返回最后一个元素
# Set集合
- 没有特殊的功能,完全继承于Collection
- 不包含重复的元素,对集合的迭代顺序不做任何保证
- 没有带索引的方法,不能使用普通for循环遍历
public class SetDemo{
public static void main(String[] args){
Set<String> set = new HashSet<String>();
set.add("hello");
set.add("world");
set.add("java");
for(String s:set){
//对集合的迭代顺序不做任何保证
System.out.println(s);// 输出world java hello
}
}
}
# 哈希值
根据对象的地址计算出来的int类型的数值
- 可以通过Object类中的
public int hashCode()方法返回对象的哈希值 - 同一个对象的多次调用hashCode()方法返回的哈希值是相同的
- 默认情况下,不同对象的哈希值是不相同的,通过方法重写,可以实现不同对象的哈希值是相同的
public class HashDemo{
public static void main(String[] args){
Stident s1 = new Stident(name:"张三",age:20);
//同一个对象的多次调用hashCode()方法返回的哈希值是相同的
System.out.println(s1.hashCode());
System.out.println(s1.hashCode());
//默认情况下,不同对象的哈希值是不相同的
Stident s2 = new Stident(name:"张三",age:20);
System.out.println(s1.hashCode());
}
}
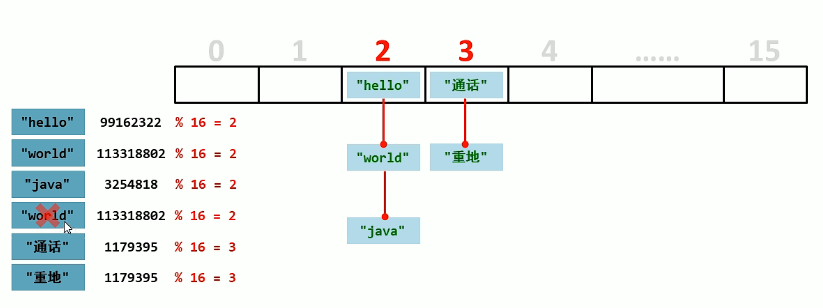
# 哈希表
底层采用数组+链表来实现的,其实是一个元素为链表的数组
存入方式:先判断对16取余后的值,再判断hashCode的值是否相同,再判断内容是否相同
# HashSet集合
- 底层数据结构是哈希表,默认初始长度是16
- 对集合的迭代顺序不做任何保证,不保证存储和取出的元素顺序一致
- 由于是Set集合,所以不包含重复的元素
- 没有带索引的方法,不能使用普通for循环遍历
public class SetDemo{
public static void main(String[] args){
HashSet<Student> hs = new HashSet<Student>();
Student s1 = new Student(name:"张三",age:20);
Student s2 = new Student(name:"李四",age:20);
Student s3 = new Student(name:"王五",age:20);
hs.add(s1);
hs.add(s2);
hs.add(s3);
for(Student s:hs){
System.out.println(s.name+","+s.age);
}
}
}
# LinkedHashSet集合
- 是由哈希表和链表实现的Set接口,具有可预测的迭代次序
- 由链表保证元素有序,也就是元素的存储和去除顺序是一致的
- 由哈希表保证元素的唯一,也就是说没有重复的元素
- 没有带索引的方法,不能使用普通for循环遍历
public class SetDemo{
public static void main(String[] args){
LingedHashSet<String> lhs = new HashSet<String>();
lhs.add("hello");
lhs.add("world");
lhs.add("java");
for(String s:set){
//对集合的迭代顺序有保证
System.out.println(s);
}
}
}
# TreeSet
- 元素可以按照一定的规则进行排序,具体排序方式取决于构造方法
- TreeSet():自然排序,即让元素所属的类实现Comparable接口,重写compareTo()方法
- TreeSet(Comparator comparator):根据指定的比较器排序,就是让集合构造方法接收Comaparator的实现类对象,重写compareTo()方法
- 由于是Set集合,所以不包含重复的元素
- 没有带索引的方法,不能使用普通for循环遍历
public class SetDemo{
public static void main(String[] args){
TreeSet<Integer> lhs = new TreeSet<Integer>();
lhs.add(10);
lhs.add(30);
lhs.add(20);
for(Integer i:set){
//自然排序
System.out.println(i); //10 20 30
}
}
}
# Comparator 自然排序
Student类是不可以进行比较的,想让Student类可以进行比较就必须实现自然排序Comparable接口,重写它的compareTo方法
public class Student implements Comparable<Student>{
private String name;
private int age;
public Student(String name,int age){
this.name = name;
this.age = age;
}
//需要重写compareTo方法
@Override
public int compareTo(Student s){
//认为比较的重复元素,会不添加
return 0; //只输出输出 张三
//正序排列
return 1;
//倒序排列
return -1;
//按照年龄从小到大排序
//如果年龄相同只取一个值 —— 王五
return this.age - s.age;
//年龄相同的时候按照姓名排序
int num = this.age - s.age;
return num==0?this.name.compareTo(s.name):num
}
}
public class SetDemo{
public static void main(String[] args){
TreeSet<Student> ts = new TreeSet<Student>();
Student s1 = new Student(name:"张三",age:20);
Student s2 = new Student(name:"李四",age:20);
Student s3 = new Student(name:"王五",age:20);
Student s3 = new Student(name:"赵六",age:20);
ts.add(s1);
ts.add(s2);
ts.add(s3);
for(Student s:ts){
System.out.println(s.name+","+s.age);
}
}
}
# Comparator 比较器排序
public class SetDemo{
public static void main(String[] args){
TreeSet<Student> ts = new TreeSet<Student>(new Comparator<Student>(){
@Override
public int compareTo(Student s1,Student s2){
return s1.age - s2.age;
}
});
Student s1 = new Student(name:"张三",age:20);
Student s2 = new Student(name:"李四",age:20);
Student s3 = new Student(name:"王五",age:20);
Student s3 = new Student(name:"赵六",age:20);
ts.add(s1);
ts.add(s2);
ts.add(s3);
for(Student s:ts){
System.out.println(s.name+","+s.age);
}
}
}
# Map 双列
- Map< K,V >:K 键的类型,V 值得类型
- 创建Map集合需要使用多态的方式,具体的实现类HashMap
- 添加相同的Key会将已有的Key的值给覆盖,也就是修改了Key的值
- HashMap是无序的,LinkedHashMap和TreeMap是有序的
//常用方法
V put(K key,V value) //添加元素,返回元素的值
V remove(Object key) //根据键删除键值对元素
void clear() //移除所有元素
boolean containsKey(Object key) //是否包含指定的键
boolean containsValue(Object value) //是否包含指定的值
boolean isEmpty() //判断是否为空
int size() //集合的长度,也就是元素的个数
//示例代码
public class Map {
public static void main(String[] args) {
// 创建Map集合的对象,多态的方式,具体的实现类HashMap。
java.util.Map<String, String> map = new HashMap<String, String>();
// V put (K key, V value) 将指定的值与该映射中的指定键相关联
map.put("001", "张三");
map.put("002", "李四");
map.put("003", "王五");
map.put("003", "赵六");//添加相同的键Key类型的元素
// 输出集合对象,可以直接输出
System.out.println(map);
}
}
// 输出{001=张三,002=李四,003=赵六}
//Map集合的获取功能
V get(Object key) //根据键获取值
Set<K> keySet() //获取所有键的集合
Collection<V> values() //获取所有值的集合
Set<Map.Entry<K,V>> entrySet() //获取所有键值对的集合
//合并多个map
Map<String, String> combineResultMap = new LinkedHashMap<String, String>();
combineResultMap.putAll(machinFrameMap1);
combineResultMap.putAll(machinFrameMap2);
//示例代码
public class StudentTest {
public static void main(String[] args) {
// 创建HashMap对象,将Student放入值的位置
HashMap<String, Student> hashMap = new HashMap<String, Student>();
// 创建学生对象
Student s1 = new Student("小明", 13);
Student s2 = new Student("小红", 15);
Student s3 = new Student("小蓝", 11);
// 将学生对象添加到HashMap集合
hashMap.put("001", s1);
hashMap.put("002", s2);
hashMap.put("003", s3);
// 方法一:键值对对象找键和值
Set<String> keySet = hashMap.keySet();
for (String key : keySet) {
Student student = hashMap.get(key);
System.out.println(student.getName() + "," + student.getAge());
}
// 方法二:
Set<Entry<String, Student>> entrySet = hashMap.entrySet();
for (Entry<String, Student> entry : entrySet) {
//根据键值对获取键和值
String key = entry.getKey();
Student value = entry.getValue();
System.out.println(key + "," + value.getName() + "," + value.getAge());
}
}
}
- MultiValueMap 是 Spring 框架中的一个接口,它继承了 Java 中的 Map 接口,但与普通的 Map 不同的是,它的 value 可以是多个值的集合,而不是单个值。这使得 MultiValueMap 在处理一些需要存储多个值的场景中非常有用,比如 HTTP 请求参数。
import org.springframework.util.MultiValueMap;
import org.springframework.util.LinkedMultiValueMap;
public class MultiValueMapExample {
public static void main(String[] args) {
MultiValueMap<String, String> params = new LinkedMultiValueMap<>();
// 存储单个值
params.add("name", "John");
// 存储多个值
params.add("hobby", "reading");
params.add("hobby", "swimming");
// 获取单个值
String name = params.getFirst("name");
System.out.println("Name: " + name);
// 获取所有值
System.out.println("Hobbies: " + params.get("hobby"));
}
}
# Collections
对集合操作的工具类
//常用方法
public static<T extends Comparable<? super T>> void sort(List<T> list) //将列表按升序排列
public static void reverse(List<?> list) //反转列表中元素的顺序
public static void shuffle(List<?> list) //随机排列列表中元素的顺序
//示例
public class StudentDemo {
public static void main(String[] args) {
// 创建ArrayList对象
ArrayList<Student> arrayList = new ArrayList<Student>();
// 创建学生对象并添加元素
Student student1 = new Student("linqingxia", 30);
Student student2 = new Student("zhangmanyu", 35);
Student student3 = new Student("wangzuxian", 33);
Student student4 = new Student("liuyan", 33);
// 把学生添加到集合
arrayList.add(student1);
arrayList.add(student2);
arrayList.add(student3);
arrayList.add(student4);
// 使用Collections的sort方法对ArrayList集合排序,
// 这里使用的是指定的比较器(Comparator)排序,实现它的内部隐藏类
//这里也可以使用Comparable比较器
Collections.sort(arrayList, new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
// 按照年龄从小到大排序,年龄相同时,按照妊名的字母顺序排序
int num1 = o1.getAge() - o2.getAge();
int num2 = num1 == 0 ? o1.getName().compareTo(o2.getName()) : num1;
return num2;
}
});
// 遍历集合并输出
for (Student student : arrayList) {
System.out.println(student.getName() + "," + student.getAge());
}
}
}
# 类和对象
# 变量
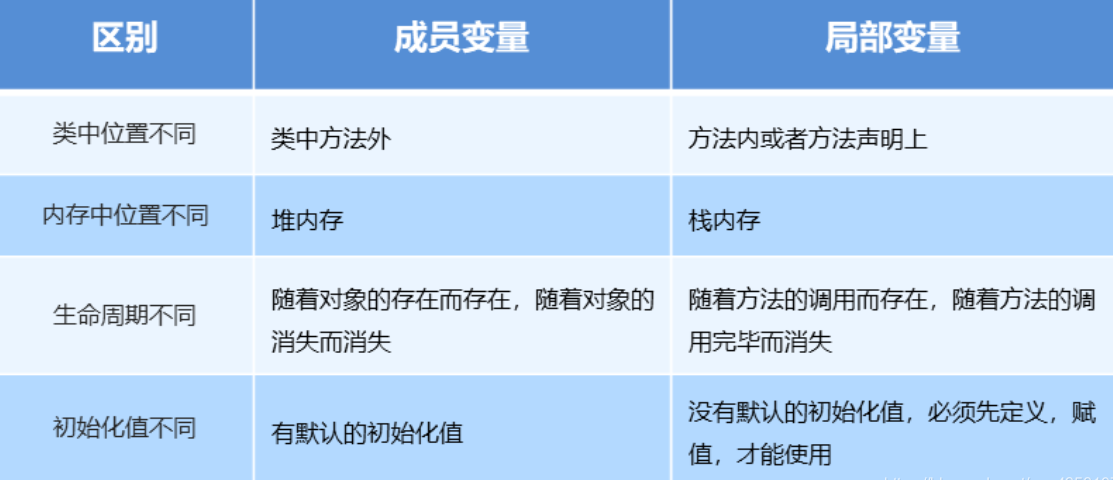
成员变量和局部变量的区别
 成员变量的定义方式
成员变量的定义方式
//成员变量的类型最好是包装类,方便后期使用JDBCTemplate绑定数据
public class student {
private String name;
private Integer age;
//注意Boolean类型的
private Boolean man;
//注意Date类型的
private Date birthday;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
//注意Boolean类型的
public Boolean isMan() {
return man;
}
public void setMan(Boolean man) {
this.man = man;
}
public student(){
this.name = "张三";
this.age = 18;
//注意Date类型的
this.birthday =new Date("2000/10/01");
this.man = false;
}
}
一个完整的类包含:
- 属性要私有化
- 要有setXxx()和getXxx()去设置属性和获取属性值
- 要有无参和有参构造方法
- 要重写toString()、equals()和hashcode()
- 要序列化,实现Serializable接口
# 修饰符
# 权限修饰符

# 状态修饰符
final
- 修饰成员变量:表示该变量是常量,不能被再次赋值
- 修饰成员方法:表示该方法不能被重写
- 修饰类:表示该类是最终类,不能被继承
- 修饰局部变量(基本类型):表示基本类型的值不能再改变
- 修饰局部变量(引用类型):表示引用类型的地址不能再改变
final Student s =new Student();
a.age = 100; //正确
s = new Student(); //错误
static
- 如果一个类、成员方法、成员变量需要被共享,可以定义为静态的类、成员方法、成员变量
- 静态成员方法只能访问静态成员
- static{}中的代码表示是在类装载的时候执行一次,且仅执行一次
abstract
- 抽象类和抽象方法必须用abstract关键字来修饰
- 抽象方法:一个没有方法体的方法应定义为抽象方法
- 抽象类:
- 如果类中有抽象方法,该类必须定义为抽象类
- 抽象类中可以没有抽象方法,只有一般方法,但是没什么意义
- 抽象类的子类要么实现父类中的所有的抽象方法,要么也是抽象类
- 抽象类可以有构造方法,但是不能实例化,构造方法的作用是用于子类访问父类数据的初始化
//抽象类
public abstact class Animal
{
public Animal(){
}
//抽象方法
public abstact void Eat();
//可以包含非抽象方法,且可以只包含非抽象方法
public void Play()
{
System.out.println("Animal Play Game");
}
}
public class Cat extends Animal
{
//子类实现父类的抽象方法
@Override
public void Eat()
{
System.out.println("Cat Eat Something");
}
}
//没有实现父类的抽象方法,该类必须定义为抽象类
public abstact class Dog extends Animal
{
}
public static void Main(string[] args)
{
//子类访问父类数据的初始化,抽象类要有构造方法
Animal cat = new Cat();
cat.Eat();//Cat Eat Something 执行子类的成员方法
cat.Play();//Animal Play Game 父类的方法会被子类继承
}
# 类的继承
- 格式:public class 子类名 extends 父类名 {}
- 父类:也被称为基类、超类,子类:也成为派生类
注意
- Java中的类只支持单继承,不支持多继承,即一个子类只能有一个父类
- Java中的类支持多层继承
# 子类中变量的访问特点
在子类型方法中访问一个变量时的查找顺序
- 子类局部范围找
- 子类成员范围找
- 父类成员范围找
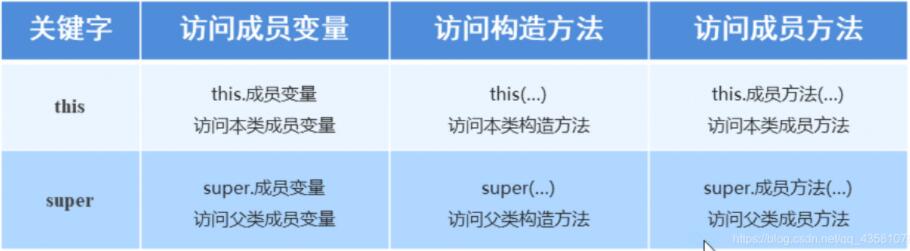
# super和this的用法
- this代表被本类对象的引用
- super代表被父类对象的引用
# 继承中构造方法的访问特点
子类中的构造方法默认都会访问父类中的无参构造方法,原因如下:
- 子类继承父类中的数据,可能还会使用父类的数据,所以子类初始化之前,一定要先完成父类的初始化
- 每个子类的构造方法第一句默认都是super()
# 方法的重写
子类需要父类的功能,而子类又有自己特有的内容时,可以重写父类中的方法 @Override(O大写)
- 私有方法不能被重写(父类的私有成员,子类是无法继承的)
- 子类方法的访问权限不能比父类小(public > 默认 > private)
# 接口
# 接口的特点:
- 用关键字interface修饰:
public interface 接口名{} - 类实现接口用implements表示:
public class 类名 implements 接口名{} - 接口不能实例化,可以通过实现类对象实例化,这叫接口多态
# 成员的特点:
- 成员变量只能是常量。默认修饰符:
public static final - 构造方法:接口没有构造方法,因为接口主要是对行为进行抽象,没有具体存在的一个类
- 成员方法:只能是抽象方法。默认修饰符:
public abstact
# 类和接口的关系:
- 类和类的关系:继承关系,只能单继承,但是可以多层继承
- 类和接口的关系:实现关系,可以单实现,也可以多实现,还可以在继承一个类的同时实现多个接口
- 接口和接口的关系:继承关系,可以单继承,也可以多继承
# 抽象类和接口的区别:
- 抽象类:成员变量可以是变量也可以是常量,有构造方法,成员方法有抽象方法,也有非抽象方法
- 接口:成员变量只能是常量,无构造方法,成员方法只能是抽象方法
- 抽象类的子类通过extends继承父类,接口的实现通过implements
public interface Alarm{
void alarm();
}
public abstract class Door{
public abstract void open();
public abstract void close();
}
public class AlarmDoor extends Door implements Alarm{
public void void open(){
}
public void void close(){
}
public void void alarm(){
}
}
# 作为形参和返回值
- 类名作为形参和返回值
- 方法的形参是抽象类名时,其实需要的是该抽象类的子类对象
- 方法的返回值是抽象类名时,其实返回的是该抽象类的子类对象
- 接口名作为形参和返回值
- 方法名的形参是接口名,其实需要的是该接口的实现类对象
- 方法的返回值是接口名,其实返回的是该接口的实现类对象
public calss AnimalOperator{
public void useAnimal(Animal a)}{
a.eat();
}
public Animal getAnimal(){
Animal a = new Cat();
return a;
}
}
public class AnimalDemo{
public static void main(string[] args){
AnimalOperator ao = new AnimalOperator();
Animal a1 = new Cat();
//方法的形参是抽象类名时,其实需要的是该抽象类的子类对象
ao.useAnimal(a1);
//方法的返回值是抽象类名时,其实返回的是该抽象类的子类对象
Animal a2 = ao.getAnimal();
a2.eat();
}
}
# 接口中的默认方法(Java8)
定义格式:
- 格式:public default 返回值类型 方法名(参数列表){ }
- 示例:public default void show(int x){ }
注意事项:
- 默认方法不是抽象方法,所以不强制被重写,但是可以被重写,重写的时候去掉default关键字
- public可以省略。default不能省略
//1:定义一个接口MyInterface,里面有两个抽象方法:
public interface MyInterface {
void show1();
void show2();
//default默认方法,可以使实现类不用实现该方法。
//还可以直接定义方法内容
default void show3() {
System.out.println("One show3");
}
}
//2:定义接口的实现类:
public class MyInterfaceImpl implements MyInterface {
@Override
public void show1() {
System.out.println("One show1");
}
@Override
public void show2() {
System.out.println("One show2");
}
//实现类中并没有实现show3方法,但是也没有报错。
}
//3:定义测试类:
public class MyInterfaceDemo {
public static void main(String[] args) {
MyInterface my = new MyInterfaceImpl();
my.show1();
my.show2();
// 如果想要添加一个新的接口方法,但是别的实现类又不要实现它,怎么办?
// 在接口中使用default
my.show3();
}
}
# 接口中的静态方法(Java8)
定义格式:
- 格式:public static 返回值类型 方法名(参数列表){ }
- 示例:public static void show(int x){ }
注意事项:
- 静态方法只能通过接口名调用,不能通过实现类或者对象名调用
- public可以省略,static不能省略
//1:定义一个接口Inter,里面有三个方法:一个是抽象方法,一个是默认方法,一个是静态方法
public interface Inter {
void show();
default void method() {
System.out.println("Inter 中的默认方法执行了");
}
static void test() {
System.out.println("Inter 中的静态方法执行了");
}
}
//2:定义接口的一一个实现类:
public class InterImpl implements Inter {
@Override
public void show() {
System.out.println("show方法执行了");
}
}
//3:定义测试类:
public class InterDemo {
public static void main(String[] args) {
Inter i = new InterImpl();
i.show();
i.method();
// 接口中的静态方法只能由类名调用
// 这样的为了防止一个实现类实现两个接口,但是两个接口中又有同名称的静态方法。
// i.test();
Inter.test();
}
}
# 关于多接口中重名默认方法的处理:在实现类中对默认方法进行重写
//当一个类需要实现多个接口时
public class SmartWatch implements INet, IPhoto {
public static final int TEMP = 30;
public void call(){
System.out.println("智能手表可以打电话");
}
public void message(){
System.out.println("智能手表可以发短信");
}
// public void network(){
// System.out.println("智能手表可以上网");
// }
@Override
public void network() {
// TODO Auto-generated method stub
}
@Override
public void photo() {
// TODO Auto-generated method stub
}
}
若两个接口中都有默认方法connection,当调用默认方法connection时就不知道该调用哪个接口的方法,解决方法是在实现类中对默认方法进行重写:
@Override
public void connection() {
System.out.println("SmartWatch中的默认连接");
}
//测试
INet net2 = new SmartWatch();
net2.connection(); //输出:SmartWatch中的默认连接
IPhoto ip2 = new SmartWatch();
ip2.connection(); //输出:SmartWatch中的默认连接
若一个子类继承父类又同时实现两个接口,且父类中也有同名的默认方法connection时,当调用该默认方法时又会实现哪一个的默认方法?
//父类
public class ThirdPhone extends SecondPhone{
public void vedio(){
System.out.println("手机可以看视频");
}
public void music(){
System.out.println("手机可以听音乐");
}
public void connection(){
System.out.println("ThirdPhone中的connection方法");
}
}
//子类
public class FourPhone extends ThirdPhone implements IPhoto, INet{
@Override
public void photo(){
System.out.println("手机可以拍照");
}
public void network(){
System.out.println("手机可以上网");
}
public void game(){
System.out.println("手机可以玩游戏");
}
}
//测试
INet net3 = new FourPhone();
net3.connection(); //输出:ThirdPhone中的connection方法
IPhoto ip3 = new FourPhone();
ip3.connection(); //输出:ThirdPhone中的connection方法
可看到,当父类和两个接口中都有connection方法时,默认实现父类中的connection方法。
当在子类中重写connection方法后,就会实现子类的connection方法:
@Override
public void connection() {
System.out.println("FourPhone中的connection方法");
}
//测试
INet net3 = new FourPhone();
net3.connection(); //输出:FourPhone中的connection方法
IPhoto ip3 = new FourPhone();
ip3.connection(); //输出:FourPhone中的connection方法
注意
public static List< Double > list = new ArrayList< >();
静态常量属于强引用不会被GC回收,最终结果就是导致内存一直被占用,即内存泄漏。
# 接口中的私有方法(Java9)
Java9中新增了带方法体的私有方法,这其实在java8中就埋下了伏笔,java8中允许在接口中定义带方法体的默认方法和静态方法,这样可能会产生一个问题:当两个默认方法或者静态方法中包含一段相同的代码实现时,就需要将这段代码抽取为一个共性方法,而这个共性方法不需要被别人使用,因此私有隐藏起来
定义格式:
- 格式1:private 返回值类型 方法名(参数列表){ }
- 范例1:private void show(){ }
- 格式1:private static 返回值类型 方法名(参数列表){ }
- 范例1:private static void show(){ }
# 类的多态
- 具体类多态
- 抽象类多态
- 接口多态
# 多态的前提和体现
- 有继承/实现关系:extends/implements
- 有方法重写:@Override
- 有父类(类/接口)引用指向(子/实现)类对象,即基类使用派生类的方法:Animal cat = new Cat()
# 具体类多态中成员访问的特点
成员变量和成员方法的执行结果都看父类,除非成员方法有重写
- 成员变量:编译时看左边,执行结果看左边(父类)
- 成员方法:编译时看左边,执行结果看右边(子类)
成员变量和成员方法的执行不一样的原因:成员方法有重写,而成员变量没有
public class Animal
{
public int age = 40;
public void Eat()
{
System.out.println("Eat something");
}
}
public class Cat extends Animal
{
public int age = 20;
public int weight = 10;
@Override
public void Eat()
{
System.out.println("Cat Eat something");
}
public void Play()
{
System.out.println("Cat Play something");
}
}
public static void Main(string[] args)
{
Animal cat = new Cat();
System.out.println(cat.age); //40 执行父类的成员变量
System.out.println(cat.weight); //报错
cat.Eat();//Cat Eat something 执行子类的成员方法
cat.Play();//报错 不能使用
}
# 多态的优点和缺点
- 优点:提高了程序的扩展性。定义方法时,使用父类型作为参数,使用时,使用具体的子类参与操作
- 缺点:不能使用子类特有的功能
# 多态中的转型
向下转型可以解决多态中不能访问子类特有功能的问题
- 向上转型:父类引用子类的对象
Animal a = new Cat() - 向下转型:父类引用转为子类对象
Cat c = (Cat)a
# 内部类
在一个类A中定义一个类B,类B就成为内部类
# 内部类的访问特点
- 内部类可以直接访问外部类的成员。包括私有
- 外类要访问内部类的成员,必须要创建内部类对象
public class Outer{
private int num = 10;
public class Inner{
public void show(){
//可以直接访问外部类的私有成员
System.out.pintln(num);
}
}
public void method(){
//外部类不可以直接使用内部类的方法
show();//错误,
//必须创建实例对象
Inner i = new Inner();
i.show();
}
}
# 成员内部类
在类的成员位置定义的类成为成员内部类
- 创建使用成员内部类的方式:
Outer.Inner oi = new Outer.Inner(); - 我们将成员内部类定义到的那个位置,一般来说就是不想让外界去访问它,所以上面的写法是不常见的, 一般都使用这样的写法,将public改为private,变为私有的,这样外界就访问不到它了
public class Outer{
private int num = 10;
private class Inner{
public void show(){
System.out.pintln(num);
}
}
public void method(){
Inner i = new Inner();
//但是在类中还是能访问到的
i.show();
}
}
# 局部内部类
在类的方法内定义的类成为局部内部类
- 在外界是无法直接使用的,需要在方法内部创建对象并使用
- 该类可以直接访问外类的成员,也可以访问方法内的局部变量
- 不需要权限修饰符
public class Outer{
private int num1 = 10;
public void method(){
private int num2 = 10;
//不需要权限修饰符
class Inner{
public void show(){
//可以直接访问外类的成员
System.out.pintln(num1);
//也可以访问方法内的局部变量
System.out.pintln(num2);
}
}
//需要在方法内部创建对象并使用
Inner i = new Inner();
i.show();
}
}
# 匿名内部类
- 本质:是一个继承了该类或者实现了该接口的子类对象
- 格式:new 类名或者接口名() { 重写方法; }
//创建一个接口让匿名内部类实现
public interface Inter{
void show();
}
//在Outer类中写一个Inter接口的匿名内部类
public class Outer{
public void method(){
new Inter(){
@Override
public void show(){
System.out.println("匿名内部类");
}
};//因为匿名内部类的本质就是一个没有名字的对象。所以要和创建对象一样加个分号
}
}
//怎么调用show方法那?
//方法一:既然它是一个对象,那么是对象就能调用方法,直接在匿名子类对象的末尾点对象即可
public class Outer{
public void method(){
new Inter(){
@Override
public void show(){
System.out.println("匿名内部类");
}
}.show();
}
}
//方法二:因为匿名内部类的本质就是一个没有名字的实现类或子类
//所以它也可以通过多态赋值给它的父类或接口类
public class Outer{
public void method(){
Inter i = new Inter(){
@Override
public void show(){
System.out.println("匿名内部类");
}
};
//方便多次调用
i.show();
i.show();
}
}
- 如果一个类在整个操作中,只使用一次的话,就可以将其定义成匿名内部类。
public interface Jumpping{
void jump();
}
public class Cat implements Jumpping{
@Override
public void jump(){
System.out.println("猫可以跳高了");
}
}
public class JumppingOperator{
public void method(Jumpping j){
j.jump();
}
}
public class JumppingDemo{
public static void main(String[] args){
JumppingOperator jo = new JumppingOperator();
//method方法需要Jumpping类型的实参
//但是Jumpping是一个接口,所以其实要的是Jumpping的实现类
Jumpping j = new Cat();
jo.method(j);
}
}
//假如还有好多动物它们都是只用jump方法一次,那么就要创建好多个类和创建好多个对象
//如果采用匿名内部类会是什么样的那?
//method其实要的是Jumpping的实现类,而匿名内部类就是一个没有名字的实现类或子类
//完全可以在jo.method(),中直接放入一个匿名内部类,然后实现接口的方法
public class JumppingDemo{
public static void main(String[] args){
JumppingOperator jo = new JumppingOperator();
jo.method(new Jumpping(){
@Override
public void jump(){
System.out.println("猫可以跳高了");
}
});
}
}
# 泛型
- 允许在定义类、接口、方法时使用,并且实参的类型只能是引用类型
- 可以指定一种类型也可以指定多种类型,多种类型之间用逗号间隔
- 添加泛型后,如果添加的类型和泛型不符合,就会在编译期间报错,不会等到运行的时候再报错
- 如果定义了泛型,不指定具体类型,泛型默认指定为Ojbect类型
public class FanXing {
public static void main(String[] args) {
//添加String类型的泛型
List<String> list = new ArrayList<String>();
// 添加元素
list.add("hello");
list.add("world");
list.add("java");
// 遍历集合
//迭代器也添加String类型的泛型
Iterator<String> it = list.iterator();
while (it.hasNext()) {
//添加泛型后,就不用类型转换了,直接将值赋值给String类型的参数,然后输出。
String s = it.next();
System.out.println(s);
}
}
}
# 泛型定义
//泛型类
public class Generic<T> {
private T t;
public T getT() {
return t;
}
public void setT(T t) {
this.t = t;
}
}
//泛型接口
public interface Generic<T>{
void show(T t);
}
public class GenericImp<T> implements Generic<T>{
@Override
public void show(T t){
System.out.println(t);
}
}
public class GenericDemo{
public static void main(String[] args){
Generic<String> g1 = new GenericImpl<String>();
g1.show("张三");
Generic<Integer> g2 = new GenericImpl<Integer>();
g2.show(30);
}
}
//泛型方法
public class Generic {
//按照泛型方法格式创建
public <T> void show(T t) {
System.out.println(t);
}
}
public class GenericDemo {
public static void main(String[] args) {
// 创建类对象
Generic g1 = new Generic();
// 调用泛型类
g1.show("林青霞");
g1.show(30);
g1.show(true);
}
}
# 类型通配符
- 任何类型:< ? >
List<?>表示元素类型未知的List - 类型通配符上限:< ? extends 类型 >
List<? extends Number>表示的类型是Number或者其子类型 - 类型通配符下限:< ? super 类型 >
List<? super Number>表示的类型是Number或其父类型
E、T、K、V等标记符没有本质上的区别,只不过是一个约定好的代码
- E - Element (在集合中使用,因为集合中存放的是元素) Collection
- T - Type(Java 类) public T Test1(T t){}
- K - Key(键) Map<K,V>
- V - Value(值)
- N - Number(数值类型)List
public class Demo1 {
public void test(List<?> list){
for (int i=0;i<list.size();i++){
System.out.println(list.get(i));
}
}
public static void main(String[] args) {
Demo1 demo1=new Demo1();
//创建一个list集合
List<String>list=new ArrayList<>();
demo1.test(list);//编译错误
List<Integer>list1=new ArrayList<>();
list1.add(1);
list1.add(2);
list1.add(3);
demo1.test(list1);
}
}
//但这种带有通配符的List不能把元素放入其中.例如,下面代码进会引起编译错误.
List<?> c=new ArrayList<>();
c.add(new Object());//出现编译错误
//原因是程序无法确定c集合中元素的类型,所以不能向其中添加对象.
# 泛型擦除
# Java 5引入泛型特性时,为了兼容之前没有泛型的版本,采用了类型擦除的实现方式
# 就是在编译时检查泛型类型的合法性,而在运行时擦除所有泛型信息,将泛型类型替换为其原始类型
# 例如,泛型类public class Box< T extends Number >
# 擦除后为public class Box,其中的泛型参数T被替换为上限类型Number
- 无界类型参数(如 < T >)被擦除为 Object
- 有界类型参数(如 < T extends Number >)被擦除为边界类型(Number)
- 泛型数组被擦除为 Object[]
JSON反序列化工具
import com.fasterxml.jackson.databind.ObjectMapper;
import java.lang.reflect.Type;
public class JsonUtil {
private static final ObjectMapper mapper = new ObjectMapper();
@SuppressWarnings("unchecked")
public static <T> T fromJson(String json, TypeReference<T> typeReference) {
try {
return mapper.readValue(json, mapper.getTypeFactory().constructType(typeReference.getType()));
} catch (Exception e) {
throw new RuntimeException("JSON反序列化失败", e);
}
}
public static <T> T fromJson(String json, Class<T> clazz) {
try {
return mapper.readValue(json, clazz);
} catch (Exception e) {
throw new RuntimeException("JSON反序列化失败", e);
}
}
}
// 使用
String json = "{\"name\":\"John\", \"age\":30}";
User user = JsonUtil.fromJson(json, User.class);
String listJson = "[{\"name\":\"John\"}, {\"name\":\"Alice\"}]";
List<User> users = JsonUtil.fromJson(listJson, new TypeReference<List<User>>() {});
# 可变参数
- 这里的变量其实是个数组
- 如果一个方法有多个参数,包含可变参数,可变参数要放在最后
public class Args {
//按照可变参数格式创建方法
public static int sum(int... is) {
//创建一个变量接受元素之和
int num = 0;
for (int i : is) {
num += i;
}
return num;
}
public static void main(String[] args) {
System.out.println(sum(10, 20, 30));
System.out.println(sum(10, 20, 30, 40));
System.out.println(sum(10, 20, 30, 40, 50));
System.out.println(sum(10, 20, 30, 40, 50, 60));
}
}
# 异常处理
所有的异常都是从Throwable继承而来的,是所有异常的共同祖先
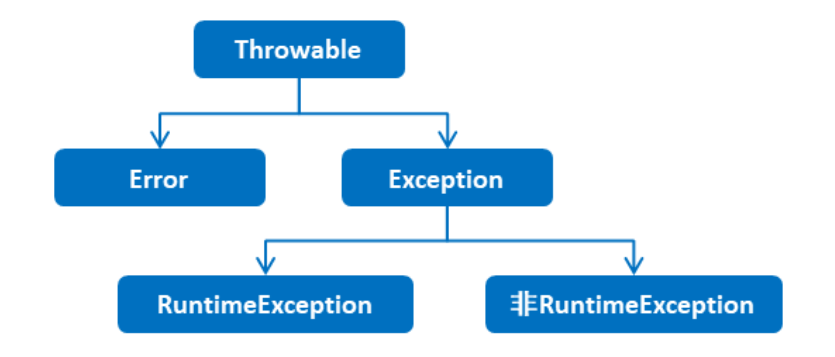
- Error:严重问题,不需要处理,一般指硬件、Java虚拟机上的问题,修改代码是解决不了的
- Exception:异常类,它表示程序本身可以处理的问题
- RuntimeException:在编译期是不检查的,出问题后,需要我们来修改代码
- 非RuntimeException:编译时就必须处理的,否则程序不能编译通过,更不能正常运行
Java中的异常被分为两大类:编译时异常和运行时异常,所有RuntimeException类及其子类被称为运行时异常,其他的异常都是编译时异常
# 异常处理方案一:try/catch
格式:try { } catch(异常类名 变量名) { 异常处理的代码 }
public class ExceptionDemo{
public static void main(String[] args){
System.out.println("开始");
method();
System.out.println("结束");
}
public static void method(){
try{
int[] arr = {1,2,3};
System.out.println(arr[3]);
} catch(ArrayIndexOutOfBoundsException e){
//只输出输出了错误的原因
e.getMessage();
//输出了程序错误的位置和原因
e.toString();
//输出了程序错误的位置和原因,还有异常信息,输出的错误信息是最全的
e.printStackTrace();
}
}
}
finally 关键字用来创建在 try 代码块后面执行的代码块。无论是否发生异常,finally 代码块中的代码总会被执行。在 finally 代码块中,可以运行清理类型等收尾善后性质的语句。
try{
// 程序代码
}catch(异常类型1 异常的变量名1){
// 程序代码
}catch(异常类型2 异常的变量名2){
// 程序代码
}finally{
// 程序代码
}
# 异常处理方案二:throws
- 格式:方法名() throws 异常类名{ }
- throws的作用只不过是抛出异常信息,并没有实际的解决问题
public class ExceptionDemo{
public static void main(String[] args){
System.out.println("开始");
try{
method();
} catch(ArrayIndexOutOfBoundsException e){
//只输出输出了错误的原因
e.getMessage();
//输出了程序错误的位置和原因
e.toString();
//输出了程序错误的位置和原因,还有异常信息,输出的错误信息是最全的
e.printStackTrace();
}
System.out.println("结束");
}
public static void method() throws ArrayIndexOutOfBoundsException {
int[] arr = {1,2,3};
System.out.println(arr[3]);
}
}
# 自定义异常
- 定义异常类,继承Exception
- 构造方法传递异常信息给父类
- 输出异常信息:throw new ScoreException("分数有误")
- 方法名后面:throws ScoreException
public class ScoreException extends Exception{
public ScoreException(){}
public ScoreException(String message){
//此处的形参是要传给父类,作为异常信息输出的
super(message);
}
}
public class Teacher{
public void checkScore(int score) throws ScoreException{
if(score<0 || score>100){
//new一个自定义异常类
//使用无参的构造方法,只会报出异常,没有异常信息
throw new ScoreException();
//使用有参的构造方法,会报出异常信息
throw new ScoreException("分数有误");
}else{
Sysyem.out.println("分数正常");
}
}
}
public class TeacherTest{
public static void main(String[] args){
Scanner sc = new Scanner(System.in);
Sysyem.out.println("请输入分数");
int score = sc.nextInt();
Teacher t = new Teacher();
//处理异常
try{
t.checkScore(score);
} catch(ScoreException e){
e.printStackTrace();
}
}
}
注意
throw需要配合throws一起使用
# 输入输出流
IO流的分类:
- 按照数据流程
- 输入流:读数据
- 输出流:写数据
- 按照数据类型
- 字节流:字节输入流、字节输出流
- 字符流:字符输入流、字符输出流
备注
通常我们是按照数据类型来分的,如果能通过记事本打开的且能看懂里面的内容就用字符流,否则使用字节流。如果不知道该使用哪种类型的流,就是用字节流

# File类
它是文件和目录路径名的抽象表示
- 文件和目录是可以通过File封装成对象的
- 会与File而言,其封装的并不是一个真正存在的文件,而是一个路径名,也可以是不存在的
//构造方法
File(String pathname) //通过给定的路径名转换为抽象路径名来创建File实例
File(String parentPathname,String childPathname) //通过父路径名和子路径名创建File实例
File(File parent,String childPathname) //从父抽象路径名和子路径名创建File实例
//示例
public class File1 {
public static void main(String[] args) {
File f1 = new File("D:\\Hello\\Java.text");
System.out.println(f1); //输出D:\Hello\Java.text
File f2 = new File("D:\\Hello", "Java.text");
System.out.println(f2);//输出D:\Hello\Java.text
File f3 = new File("D:\\Hello");
File f4 = new File(f3, "java.text");
System.out.println(f4);//输出D:\Hello\Java.text
}
}
//常用方法
//注意:这三种方法创建文件或目录时,如果该文件或目录已经存在,则不会创建
public boolean createNewFile() //创建文件
public boolean mkdir() //创建文件夹
public boolean mkdirs() //创建文件夹及子文件夹
//注意:如果该目录下有内容,不能直接删除,应先删除目录中的内容
public boolean delete() //删除由该抽象路径名表示的文件或目录
public boolean isDirectory() //该抽象路径名是否为目录
public boolean isFile() //该抽象路径名是否为文件
public boolean exists() //该抽象路径名是否存在
public String getAbsolutePath() //返回该抽象路径名的绝对路径
public String getPath() //返回该抽象路径名的路径
public String getName() //返回该抽象路径名表示的文件或目录的名称
public String[] list() //返回该抽象路径名中所有的文件和目录名称
public File[] listFiles() //返回该抽象路径名中所有的文件和目录的File对象
//示例
public class File3 {
public static void main(String[] args) {
File file = new File("D:\\www\\Java.text");
System.out.println(file.isDirectory());
System.out.println(file.isFile());
System.out.println(file.exists());
System.out.println(file.getAbsolutePath());
System.out.println(file.getPath());
System.out.println(file.getName());
File file2 = new File("D:\\www");
String[] list = file2.list();////此方法返回的是一个字符串的数组
for (String s1 : list) {
System.out.println(s1);
} //输出 Java.text JavaSE JavaWEB
File[] listFiles = file2.listFiles();////此方法返回的是一个File对象的数组
for (File f1 : listFiles) {
//使用次方法的好处是可以进行File的操作,因为此数组是一个File对象
//如果此处想查询的只是目录下的文件和文件名就可是使用getName()方法
//还可以加判断,判断查询的对象是目录还是文件
System.out.println(f1);
//输出 D:\\wwwJava.text D:\\wwwJavaSE D:\\wwwJavaWEB
}
}
}
# file.separator用法
在Windows下的路径分隔符和Linux下的路径分隔符是不一样的,当直接使用绝对路径时,跨平台会爆出"No such file or diretory"的异常
//比如说要在temp目录下建立一个test.txt文件,在Windows下应该这么写:
File file1 = new File ("C:\tmp\test.txt");
//在Linux下则是这样的:
File file2 = new File ("/tmp/test.txt");
//如果要考虑跨平台,则最好是这么写:
File myFile = new File("C:" + File.separator + "tmp" + File.separator, "test.txt");
# 递归
是指方法定义中调用方法本身的现象,一定要找到递归出口,否则出现内存溢出
public class File4 {
public static void main(String[] args) {
System.out.println(f(20));
}
public static int f(int n) {
//当n=1或2是结束递归
if (n == 1 || n == 2) {
return 1;
} else {
return f(n - 1) + f(n - 2);
}
}
}
//遍历目录
public class File5 {
public static void main(String[] args) {
// 根据给定的路径创建一个File对象
File srcFile = new File("D:\\www");
// 调用方法
getAllFilePath(srcFile);
}
// 定义一个方法,用于获取给定目录下的所有内容,参数为第1步创建的File对象
public static void getAllFilePath(File srcFile) {
// 获取给定的File目录下所有的文件或者目录的File数组
File[] listFiles = srcFile.listFiles();
// 遍历该File数组,得到每一个File对象
// 为了增强代码的健壮性,建议加一个是否为null的判断
if (listFiles != null) {
for (File file : listFiles) {
// 判断该File对象是否是目录
if (file.isDirectory()) {
// 是,调用递归
getAllFilePath(file);
} else {
// 不是:获取绝对路径输出在控制台
System.out.println(file.getAbsolutePath());
}
}
}
}
}
# 字节流
字节流抽象基类:
- InputStream:字节输入流所有类的超类
- OutputStream:字节输出流所有类的超类
# 字节流写数据
FileOutputStream:文件输出流用于将数据写入File
- 创建字节输出流对象
- 调用字节输出流的写方法
- 释放资源。此步骤很重要,必须释放资源
//字节流写数据的方式
void write(int b) //将指定的字节写入文件输出流
void write(byte[] b) //将指定长度的字节组写入文件输出流
void write(byte[] b,int off,int len) //从字节数组的指定位置截取固定长度写入文件输出流
public class File6 {
public static void main(String[] args) throws IOException {
// 创建字节输出流对象
// FileOutputStream (String name): 创建文件输出流以指定的名称写入文件
FileOutputStream outputStream = new FileOutputStream("D:\\www\\java.text");
//void write (int b):将指定的字节写入此文件输出流
//写入数字97,此数输入57和55是因为在数据的底层9和7就是57和55
outputStream.write(57);
outputStream.write(55);
//最后都要释放资源
//void close (): 关闭此文件输出流并释放与此流相关联的任何系统资源。
outputStream.close();
}
}
public class File7 {
public static void main(String[] args) throws IOException {
// 创建文件输出流
FileOutputStream outputStream = new FileOutputStream("D:\\www\\java.text");
// void write (int b): 将指定的字节写入此文件输出流
byte[] bs = "a".getBytes();
outputStream.write(bs);
//释放资源
outputStream.close();
}
}
public class File8 {
public static void main(String[] args) throws IOException {
// 创建文件输出流
FileOutputStream outputStream = new FileOutputStream("D:\\www\\java.text");
//将len字节 从指定的字节数组开始,从偏移量off开始写入此文件输出流
byte[] bs = "abcd".getBytes();
//从bs数组中的索引1到3的字节
outputStream.write(bs, 1, 3);
//释放资源
outputStream.close();
}
}
# 字节流写入注意事项
- 换行:
- windows:\r\n
- linux:\n
- mac:\r
- 追加:
public FileOutPutStream(String name,boolean append) - 异常处理:这样写资源释放是最具有健壮性的,真正的项目建议写成这样
public class File8{
public static void main(String args[]){
FileOutPutStream fs = null;
try{
fs = new FileOutPutStream("D:\\www\\java.text");
fs.write("abc".getBytes());
} catch(IOException e){
e.printStackTrace();
} finally{
//判断FileOutPutStream是否为空
if(fs!=null){
try{
fs.close();
} catch(IOException e){
e.printStackTrace();
}
}
}
}
}
# 字节流读数据
FileInputStream:从File文件获取输入流
- 创建字节输入流对象
- 调用字节输入流的读数据方法
- 释放资源。此步骤很重要,必须释放资源
//字节流读数据的方式
void read() //一次读一个字节数据
void read(byte[] b) //一次读一个字节数组数据
void read(byte[] b,int off,int len) //从字节数组的指定位置截取固定长度读取
public class File9 {
public static void main(String[] args) throws IOException {
// 创建字节输入流
FileInputStream fis = new FileInputStream("D:\\www\\java.text");
// 第一次读取数据
int read = fis.read();
// 去掉ln,并将int类型转换为char类型输出
System.out.print((char) read);
// 第二次读取数据
read = fis.read();
System.out.print((char) read);
// 第三次读取数据
read = fis.read();
System.out.print((char) read);
fis.close();
}
}
//输出 abc
//最标准的字节流读数据格式
public class File9 {
public static void main(String[] args) throws IOException {
// 创建字节输入流
FileInputStream fis = new FileInputStream("D:\\www\\java.text");
// 如果输入流读取到了文件的末尾那么就会返回-1
int by;
while ((by = fis.read()) != -1) {
System.out.print((char) by);
}
fis.close();
}
}
//复制文本文件
public class File10 {
public static void main(String[] args) throws IOException {
// 1、根据数据源创建字节输入流对象
FileInputStream fis = new FileInputStream("D:\\www\\java.text");
// 2、根据目的地创建字节输出流对象
//再ide中直接写文件名就会创建在类所在的项目中
FileOutputStream fos = new FileOutputStream("java.tetxt");
// 3、读写数据,复制文本文件(一次读取一个字节,一次写入一个字节)
int by;
//判断和读写
while ((by = fis.read()) != -1) {
//复制
fos.write(by);
}
// 4、释放资源
fis.close();
fos.close();
}
}
//一次读一个字节数组数据
public class File1 {
public static void main(String[] args) throws IOException {
// 创建字节流输入对象
FileInputStream fis = new FileInputStream("D:\\www\\java.text");
// 调用字节输入流对象的读数据方法
byte[] bys = new byte[5];
// 第一次读取数据
fis.read(bys);
// String (byte[] bytes ),将字节数组转换为一个String类型
System.out.println(new String(bys));
// 第二次读取数据
fis.read(bys);
// String (byte[] bytes ),将字节数组转换为一个String类型
System.out.println(new String(bys));
// 释放资源
fis.close();
}
}
//从指定位置开始读取数据
public class File1 {
public static void main(String[] args) throws IOException {
// 创建字节流输入对象
FileInputStream fis = new FileInputStream("D:\\www\\java.text");
// 调用字节输入流对象的读数据方法
// int read (byte[] b): 从该输入流读取最多b.length个字节的数据到一个字节数组
byte[] bys = new byte[1024];// 1024及其整数倍,这是读取数据时给的标准的数组元素个数
// 如果输入流读取到了文件的末尾那么就会返回-1
int len;
while ((len = fis.read(bys)) != -1) {
//读取bys数组中的索引0到len的元素,并转化为String类型
System.out.println(new String(bys, 0, len));
}
// 释放资源
fis.close();
}
}
# 字节缓冲流
- 字节缓冲输入流:BufferedInputStream(InputSream in)
- 字节缓冲输出流:BufferedOutputStream(OutputStream out)
- 字节缓冲流仅仅提供缓冲区,具体的读写数据还得依靠基本的字节流对象进行操作
- 字节缓冲输入流和字节缓冲输出流默认数组长度8192
- 只需要关闭字节缓冲流
public class Main {
public static void main(String[] args) throws IOException {
long startTime = System.currentTimeMillis();
method();
long endTime = System.currentTimeMillis();
System.out.println("共耗时"+(endTime-startTime)+"毫秒");
}
public static void method() throws IOException {
FileOutputStream f1 = new FileOutputStream("F:\\证件\\新时空\\jinan1.mp4");
BufferedOutputStream bs1 = new BufferedOutputStream(f1);
FileInputStream f2 = new FileInputStream("F:\\证件\\新时空\\jinan.mp4");
BufferedInputStream bs2 = new BufferedInputStream(f2);
byte[] bt =new byte[1024];
int len = 0;
while ((len = bs2.read(bt)) != -1){
bs1.write(bt);
}
//只需要关闭字节缓冲流
bs1.close();
bs2.close();
}
}
# 字符流
- 由于字节流操作中文不方便。字符流 = 字节流 + 编码表
- 汉字存储时无论以哪种编码存储,第一个字节都是负数,所以即使一个一个字节的读取也能拼成汉字
- 字符流的抽象基类
- Reader:字符输入流的抽象基类
- Writer:字符输出流的抽象基类
# 编码表
- ASCII字符集:基本的ASCII字符集,使用7位表示一个字符,共128字符,ASCII的扩展字符集用8位表示一个字符,共256个字符。支持的所有字符的集合,包括各国的文字、标点、符号、数字等
- GBXXX字符集
- GB2312:简体中文码表,一个效于127的字符意义同ASCII码表,大于127的字符连在一起就表示一个汉字,大约包含7000多个汉字
- GBK:最常用的中文码表,在GB2312的基础商扩展,使用了双字节编码,共收录了21003个汉字,完全兼容GB2312,同时支持繁体字及日韩文字
- GB18030:最新的中文码表,收录汉字70244,采用多字节编码,每个字可以由1个字节、2个字节、4个字节组成,支持少数民族文字,繁体字及日韩文字
- Unicode字符集:为表达任意语言的任意字符设计,是业界的一种标准,也称统一码、标准万国码。最多使用4个字节组成,常见的有UTF-8、UTF-16、UTF32
# 字符串和字节数据组转换
byte[] getBytes() //使用默认的字符集将字符串转为字节数组
byte[] getBytes(String charsetName) //使用指定的字符集将字符串转为字节数组
String(byte[] bytes) //使用默认的字符集将字节数组转为字符串
String(byte[] bytes,String charsetName) //使用指定的字符集将字节数组转为字符串
# 读写字符文件
- FileWriter(String fileName):写入字符文件的便捷类
void write(int c) //写一个字符
void write(char[] char) //写一个字符数组
void write(char[] char,int off,int len) //写入字符数组的一部分
void write(String str) //写一个字符串
void write(String str,int off,int len) //写一个字符串的一部分
- FileReader(String fileName):读取字符文件的便捷类
int read() //一次读取一个字符
int read(char[] char) //一次读取一个字符数组
//复制文件
public class FIle1 {
public static void main(String[] args) throws IOException {
// 根据数据源创建字符输入流对象
FileReader fr = new FileReader("java.text");
// 根据目的地创建字符输出流对象
FileWriter fw = new FileWriter("Copy.text");
// 读写数据,复制文件
char[] chs = new char[1024];
int len;
while ((len = fr.read(chs)) != -1) {
fw.write(chs, 0, len);
}
// 释放资源
fw.close();
fr.close();
}
}
# 刷新流和关闭流
字符流需要flush或者close
- flush():刷新流,还可以继续写数据,这样才能将字符写到文件中去
- close():关闭流,释放资源,不能再写数据,但是再关闭之前会先刷新流
# 字符缓冲流
- BufferedWriter(Writer out):将文本写入字符输出流,缓冲字符,以提供单个字符、数组的高效写入
- void newLine():分行分隔符,行分割符字符由系统定义,每个系统都不一样
- void write(String line):一次写一行字符
- BufferedReader(Reader in):从字符输入流读取文本,缓冲字符,以提供字符、数组和行的高效读取
- String readLine():读一行字符,如果流的结尾已经道道,则为null
public class File{
public static void main(String[] args) throws IOException{
//根据数据源创建字符缓存流输入对象
BufferedReader br = new BufferedReader(new FileReader("java.txt"));
//根据目的地创建字符缓存输出流对象
BufferedWriter bw = new BufferedWriter(new FileWriter("copy.txt"));
char[] chs = new char[1024];
int len;
while((len = br.read(chs)) != -1){
bw.write(chs,0,len);
}
//使用newLine()和readLine()
String line;
while((line = br.readLine()) !=null){
bw.write(line);
bw.newLine();
}
bw.close();
br.close();
}
}
# 字符转换流
OutputStreamWriter:字符转换输出流
- OutputStreamWriter(OutputStream out):使用默认的字符集创建一个OutputStreamwriter
- OutputStreamWriter(OutputStream out, String charset):使用指定字的符集创建outputStreamWriter
InputStreamReader:字符转换输入流
- InputStreamReader(InputStream in):使用默认的字符集创建一个InputStreamReader
- InputStreamReader(InputStream in, String charset):使用指定字的符集创建一个InputStreamReader
public class FIle9 {
public static void main(String[] args) throws IOException {
// OutputStream是一个抽象类,所以应该创建它的实现类FileOutputStream
FileOutputStream fos = new FileOutputStream("java.text");
OutputStreamWriter osw = new OutputStreamWriter(fos, "GBK");
//输出和输入的编码要一致
FileInputStream fis = new FileInputStream("java.text");
InputStreamReader isr = new InputStreamReader(fis, "GBK");
// 写数据
osw.write("中国");
// 释放资源,这里要先关闭fos再关闭osw,由下向上关闭
osw.close();
fos.close();
// 读数据,这里使用一次读取一个字节的方法,也可以使用一次读取一个字节数组的方法
int ch;
while ((ch = isr.read()) != -1) {
System.out.print((char) ch);
}
// 释放资源,这里要先关闭isr再关闭fis,由下向上关闭
isr.close();
fis.close();
//写入一个字符数组
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("java.text"));
char[] chs = { 'a', 'b', 'c' };
osw.write(chs);
osw.close();
//写入字符数组的一部分|
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("java.text"));
char[] chs = { 'a', 'b', 'c', 'd' };
osw.write(chs, 1, 2);
osw.close();
}
}
# 标准输入输出流
System中有2个静态的成员变量:
- public static final InputStream in:标注输入流,通常该流对应于键盘输入
- public static final PrintStream out:标准输出流,通常该流对应于示输出
//标准输入流
public static void main(String[] args) throws IOException {
// public static final InputStream in:标准输入流。
// 因为它的static修饰的,所以可以直接用类名访问
InputStream is = System.in;
// 自己实现键盘录入
// BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(is));
// 自己实现键盘录入数据太麻烦了,所以Java就提供了-一个类供我们使用
Scanner sc = new Scanner(is);
}
//标准输出流
public static void main(String[] args) {
// public static final PrintStream out:标准输出流
// 因为是static修饰的方法,所以可以直接用类名调用
PrintStream out = System.out;
// 能够方便的打印各种数据值
System.out.println("Hello");
System.out.println(100);
//加ln可换行
System.out.println();
// 不加ln,如果不输入数据是会报错的
// System.out.print();
}
# 打印流
只负责输出数据,不负责读取数据
- 字节打印流:PrintStream
- 字符打印流:PrintWriter
# 字节打印流
- 构造方法:PrintStream(Stream fileName) PrintStream(OutputStream out) 使用指定的文件创建打印流
- 方法:使用父类的方法(write)写数据会转码,使用自己特有的方法(print或println)写数据原样输出
public static void main(String[] args) throws IOException {
// PrintStream (String fileName): 使用指定的文件名创建新的打印流
PrintStream ps = new PrintStream("ps.text");
// 字节输出流有的方法
ps.write(97);//会将97转成a
// 使用PrintStream特有的方法写数据
// 如果加ln会自行换行
ps.println(97); //输出97
// 释放资源
ps.close();
}
# 字符打印流
- PrintWriter(String fileName)使用指定的文件创建打印流
- PrintWriter(Writer out, boolean autoFlush) autoFlush是true不需要flush
public static void main(String[] args) throws IOException {
PrintWriter pw = new PrintWriter("pw.text");
pw.write("Hello");
// 换行符
pw.write("\r\n");
// 字符流不加flush会输出失败
pw.flush();
pw.println("Hello");
// pw.println("Hello");做的是这两个步骤
// pw.write("Hello");
// pw.write("\r\n");
pw.flush();
// 释放资源
pw.close();
PrintWriter pw=new PrintWriter(new FileWriter("pw.text"), true);
pw.println("Hello");
// pw.println("Hello");做的是这三个步骤
// pw.write("Hello");
// pw.write("\r\n");
// pw.flush();
pw.println("Java");
// 释放资源
pw.close();
}
//复制文件
public static void main(String[] args) throws IOException {
// 1 :根据数据源创建字符输入流对象
BufferedReader br = new BufferedReader(new FileReader("D:\\www\\java.text"));
// 2:根据目的地创建字符输出流对象
// 使用字符打印流
PrintWriter pw = new PrintWriter(new FileWriter("java.text"));
// 3:读写数据,复制文件
String line;
while ((line = br.readLine()) != null) {
//这里的一步代表了以前的三步
pw.print(line);
}
// 4:释放资源
pw.close();
br.close();
}
# 对象序列化流
就是将对象保存到磁盘中,或者在网络中传输对象,反之,该字节序列还可以从文件中读取出来,重构对象,对他进行反序列化
# 对象序列化流
ObjectOutputStream 继承自OutputStream,是一个字节输出流
- 构造方法:ObjectOutputStream(OutputStream out)
- 方法:void writeObject(Object obj):将指定的对象写入ObjectOutputStream
//实现Serializable接口,才能实现序列化
public class Student implements Serializable{
private String name;
private int age;
//有参构造和无参构造省略。。。
//get和set方法省略。。。
}
public static void main(String[] args) throws IOException {
//创建一个写入指定的0utputStream的objectOutputStream
ObjectOutputStream oos=new ObjectOutputStream(new FileOutputStream("java.text"));
//创建对象
Student student =new Student("林青霞", 26);
//void writeObject (Object obj): 将指定的对象写入objectOutputStream
oos.writeObject(student);
//释放资源
oos.close();
}
注意
- 一个对象想被序列化,该对象所属的类必须实现Serializable接口
- Serializable是一个标记接口,实现该接口,不需要重写任何方法
- 对象序列化后在文件中保存的是乱码,只有通过反序列化才能正常读取数据
# 对象反序列化流
ObjectInputStream 继承自InputStream,是一个字节输入流
- 构造方法:ObjectInputStream(InputStream in)
- 方法:readObject():从ObjectInputStream读取一个对象
public static void main(String[] args) throws IOException, ClassNotFoundException {
//创建从指定的InputStream读取的objectInputStream
ObjectInputStream ojs=new ObjectInputStream(new FileInputStream("java.text"));
//Object readobject(): 从objectInputStream读取一 个对象
Object obj = ojs.readObject();
//向下转型将Object赋值给Student
Student s=(Student) obj;
System.out.println(s.getName()+","+s.getAge());
//释放资源
ojs.close();
}
# 对象序列化流的几个问题
- 对象序列化后修改对象的内容会抛出InvalidClassException异常
- 添加一个UID,这个值是可以随意设置的
- 如果一个对象中的某个成员变量的值不想被序列化,又该如何实现呢?
- 添加一个transient关键字
public class Student implements Serializable{
//设置UID必须在序列化之前就设置好,如果在序列化后再设置就不会成功
private static final long serialVersionUID = 2700828625496571094L;
private String name;
//添加一个transient关键字,就可以不被序列化
private transient int age;
}
# Properties
- 继承自Hashtable,是一个Map集合类
- Properties可以保存到流中或从流中加载
Properties作为集合的特有方法
- Object setProperty(String key,String value):设置集合的键值
- String getProperty(String key):根据键获取值
- Set< String > stringPropertyNames():获取所有建的集合
public static void main(String[] args) {
// 创建Properties集合对象
Properties prop = new Properties();
// Object setProperty(String key, String value):设置集合的键和值
// 都是String类型,底层调用Hashtable方法put
prop.setProperty("1", "张曼玉");
prop.setProperty("2", "林青霞");
prop.setProperty("3", "刘岩");
System.out.println(prop);
System.out.println("-----------------------");
// String getProperty(String key): 使用此属性列表中指定的键搜索属性
System.out.println(prop.getProperty("1"));
System.out.println("-----------------------");
Set<String> names = prop.stringPropertyNames();
for (String key : names) {
System.out.println(key);
}
}
# Properties和IO流结合的方法
- 字符流操作
- void store(Writer writer,String comments):将propertites集合写入到writer中
- void load(Reader reader):读取字符流到propertites集合
- 字节流操作
- void store(OutputStream out,String comments):将propertites集合写入到字节输出流中
- void load(InputStream in):读取字节流到propertites集合
private static void myStore() throws IOException {
Properties prop = new Properties();
prop.put("1", "林青霞");
prop.put("2", "王祖贤");
prop.put("3", "张曼玉");
// 要传入Writer类型的对象,所以先创建一个,指定要创建的文件路径。
FileWriter fw = new FileWriter("java.text");
// 将FileWriter放入writer,而comments 可写可不写
prop.store(fw, null);
fw.close();
}
private static void myLoad() throws IOException {
Properties prop = new Properties();
// void load(Reader reader):
FileReader fr = new FileReader("java.text");
prop.load(fr);
fr.close();
System.out.println(prop);
}
# 多线程
- 进程:正在运行的程序
- 线程:进程中的单个顺序控制流,是一条执行路径。分为单线程、多线程
- 在java中,每次程序运行至少启动2个线程。一个是main线程,一个是垃圾收集线程
# 实现方式一:继承Thread类
- 定义一个类继承Thread类
- 在定义类中重写run()方法:用来封装被线程执行的代码
- 创建定义类的对象
- 启动线程 start()
public class MyThread extends Thread{
@override
public void run(){
for(int i = 0; i<100;i++){
System.out.println(i);
}
}
}
public class MyThreadDemo{
public static void main(String[] arg){
MyThread my1 = new MyThread();
MyThread my2 = new MyThread();
my1.start();
my2.start();
}
}
# 实现方式二:实现Runable接口
- 定义一个类实现Runable接口
- 在定义的类中重写run()方法
- 创建定义类的对象
- 创建Tread类的对象,把定义的类的对象作为构造方法的参数
- 启动线程
public class MyRunable implements Runnable{
@override
public void run{
for(int i=0;i<100;i++){
//不能使用getName(),因为实现的时Runable接口,不是Thread类
Sysyem.out.println(Thread.currentThread().getName()+":"+i);
}
}
}
pub class MyRunableDemo{
public static void mian(String[] args){
MyRunable my = new MyRunable();
//把MyRunable对象作为构造方法的参数
Thread t1 = new Thread(my,"飞机");
Thread t2 = new Thread(my,"高铁");
t1.start();
t2.start();
}
}
# 相比继承Thread类,实现Runnable接口的好处
- 避免了Java单继承的局限性,使用实现Runnable接口还可以继承其他的类
- 相比于继承thread更能描述数据共享的概念
# 设置和获取线程名称
- 在Thread类中有默认的线程名Thread-0、Thread-1……
- void setName(String name):设置线程名称
- String getName():返回此线程的名称
- 通过构造方法也可以设置线程的名称
- 获取当前运行的线程或者主线程的方法:Thread currentThread()
//setName和getName
public class MyThread extends Thread{
@override
public void run(){
for(int i = 0; i<100;i++){
//this.getName()
System.out.println(getName()+":"+i);
}
}
}
public class MyThreadDemo{
public static void main(String[] arg){
MyThread my1 = new MyThread();
MyThread my2 = new MyThread();
my1.setName("飞机");
my2.setName("高铁");
my1.start();
my2.start();
}
}
//构造方法
public class MyThread extends Thread{
public MyThread(){
super();
}
public MyThread(String name){
//调用Thread类的构造方法,将参数传递过去
super(name);
}
@override
public void run(){
for(int i = 0; i<100;i++){
System.out.println(getName()+":"+i);
}
}
}
public class MyThreadDemo{
public static void main(String[] args){
MyThread my1 = new MyThread("飞机");
MyThread my2 = new MyThread("高铁");
my1.start();
my2.start();
}
}
//获取main()方法所在的线程名
public class MyThreadDemo{
public static void(String[] args){
//main方法的线程名是main
System.out.println(Thread.currendThread().getName());
}
}
# 线程调度
Thread类中设置和获取线程优先级的方法:
- public final int getPriority():返回此线程的优先级
- public final void setPriority(int newPriority):设置线程优先级
- 线程默认优先级是5,线程优先级的范围是:1-10
- MIN_PRIORITY:最小线程优先级1 MAX_PRIORITY:最大线程优先级10 NORM_PRIORITY:默认优先级5
# 线程控制
- static void sleep(long millis):使当前线程暂停指定的毫秒数
- void join():其他线程都会等待这个线程结束,才会执行。注意:需要写start()后面
- void setDaemon(boolean on):将线程设置为守护线程。当运行的都是守护线程时,JAVA虚拟机退出
public class MyThread extends Thread{
@override
public void run(){
for(int i = 0; i<100;i++){
System.out.println(getName()+":"+i);
try{
Thread.sleep(1000);
}catch(InterruptedException e){
e.printStackTrace();
}
}
}
}
public clas ThreadDemo{
public static void main(String[] args){
Thread t1 = new Thread();
Thread t2 = new Thread();
Thread t3 = new Thread();
t1.setName("康熙");
t2.setName("四阿哥");
t3.setName("八阿哥");
t1.start();
try{
t1.join();//需要写start()后面
} catch (InterruptedException e){
e.printStackTrace();
}
t2.start();
t3.start();
}
}
public clas ThreadDemo{
public static void main(String[] args){
Thread t1 = new Thread();
Thread t2 = new Thread();
t1.setName("张飞");
t2.setName("关羽");
//设置主线程
Thread.currentThread.setName("刘备");
//主线程运行结束后,其他运行的线程都是守护线程时,程序停止运行
t1.setDaemon(true);
t2.setDaemon(true);
t1.start();
t2.start();
t3.start();
}
}
# 线程的生命周期
- 正常情况,抢到CPU执行权就运行
- 在运行的时候其他线程抢走了CPU的执行权的话,它就会回到就绪状态,然后再抢CPU的执行权,如果抢到了就继续执行
- 在运行的时候执行了sleep()方法,执行后线程就会进入到阻塞状态,等到了设定的时间之后,它就会回到就绪状态,继续和其他的线程抢CPU的执行权
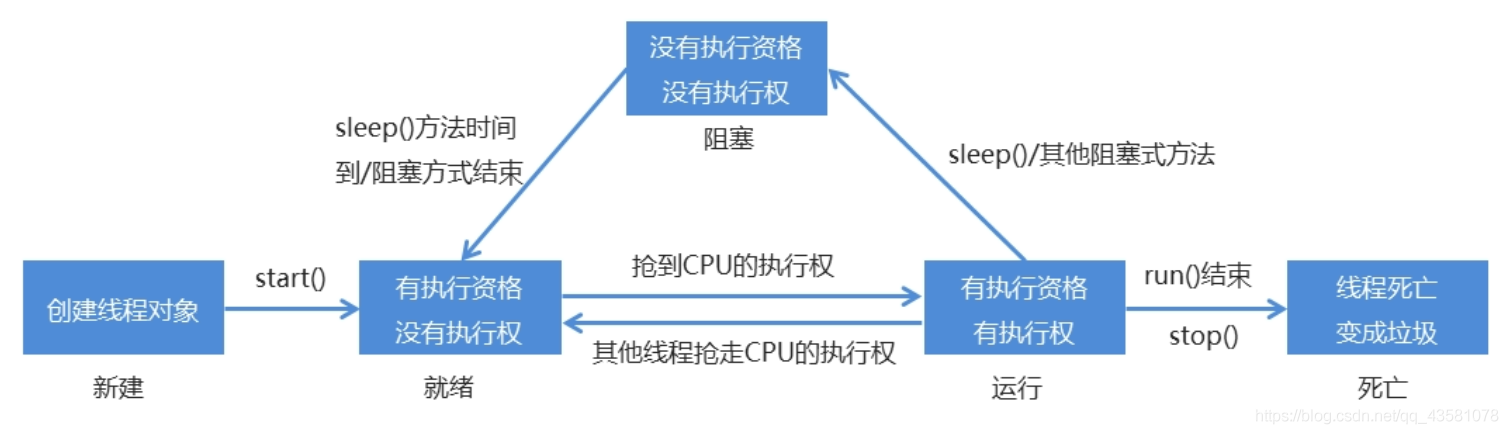
注意
- start()方法的调用后并不是立即执行多线程代码,而是使得该线程变为可运行态(Runnable),什么时候运行是由操作系统决定的
- start不能重复调用,否则会出现java.lang.IllegalThreadStateException异常
# 线程同步
把操作共享数据的代码给锁起来,让任意时刻只能有有一个线程执行
# 线程安全问题
线程安全问题都是由全局变量及静态变量引起的,若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个这个全局变量是线程安全的
# 同步代码块
synchronized(任意对象){ }:就相当于给代码枷锁了,任意对象可以看成是一把锁,加锁后,线程进入synchronized内部后就上了锁,其他的线程就进不去了,即使是内部的线程休眠了,内部只能有一个线程
- 好处:解决了多线程的数据安全问题
- 弊端:当线程很多时,每个线程都会去判断同步上的锁,耗费资源,降低程序的运行效率
public class SellTicket implements Runnable{
private int tickets = 100;
private Object obj = new Object();
@Override
public void run(){
while(true){
//上锁,锁必须是同一把
synchronized(obj){
if(tickets > 0){
try{
Thread.sleep(100);
} catch (InterruptedException(e)){
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()
+"正在出售第"+tickets+"张票")
tickets--;
}
}
}
}
}
public class SellTickDemo{
public static void main(String[] args){
SellTicket sellTicket = new SellTicket();
Thread t1 = new Thread(sellTicket,"窗口1");
Thread t2 = new Thread(sellTicket,"窗口2");
Thread t3 = new Thread(sellTicket,"窗口3");
t1.start();
t2.start();
t3.start();
}
}
# 同步方法
就是把synchronized关键字加上方法上,同步方法的锁对象是this
public class SellTicket implements Runnable{
private int tickets = 100;
private int x = 0;
@Override
public void run(){
while(true){
if(x % 2 ==0){
//锁对象是this
synchronized(this){
if(tickets > 0){
try{
Thread.sleep(100);
} catch (InterruptedException(e)){
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()
+"正在出售第"+tickets+"张票")
tickets--;
}
}
} else {
sellTicket();
}
x++;
}
}
//同步方法
private synchronized void sellTicket(){
if(tickets > 0){
try{
Thread.sleep(100);
} catch (InterruptedException(e)){
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"正在出售第"+tickets+"张票")
tickets--;
}
}
}
# 同步静态方法
就是把synchronized关键字加到静态方法上,同步静态方法锁的对象是:类名.class
public class SellTicket implements Runnable{
private static int tickets = 100;
private int x = 0;
@Override
public void run(){
while(true){
if(x % 2 ==0){
//锁对象是 类名.class,这里用到了反射
synchronized(SellTicket.class){
if(tickets > 0){
try{
Thread.sleep(100);
} catch (InterruptedException(e)){
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()
+"正在出售第"+tickets+"张票")
tickets--;
}
}
} else {
sellTicket();
}
x++;
}
}
//同步静态方法
private static synchronized void sellTicket(){
if(tickets > 0){
try{
Thread.sleep(100);
} catch (InterruptedException(e)){
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"正在出售第"+tickets+"张票")
tickets--;
}
}
}
# Lock锁
Lock是接口不能直接实例化,这里采用它的实现类ReentantLock来实例化
- ReentrantLock():创建一个ReentrantLock的实例
- void lock():上锁
- void unlock():解锁
public class SellTicket implements Runnable{
private int tickets = 100;
private Lock lock = new ReentrantLock();
@Override
public void run(){
while(true){
//加入try……finally的原因是,如果在运行中发生了错误,释放锁照样执行
try{
lock.lock();
if(tickets > 0){
try{
Thread.sleep(100);
} catch (InterruptedException(e)){
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"卖第"+tickets+"张")
tickets--;
}
} finally{
lock.unlock();
}
}
}
}
# synchronized和lock的区别
- lock是一个接口,而synchronized是一个关键字
- syncheronized在发生异常时会自动释放占有的锁,因此不会出现死锁,而lock发生异常时,不会主动释放占有的锁,必须手动释放,可能会引起死锁
# 线程安全的类
- StringBuffer:线程安全的可变的字符序列。StringBuilder:线程不安全的可变的字符序列
- Vector:线程安全,实现List接口。ArrayList:线程不安全,实现List接口
- Hashtable:线程安全,实现了Map接口。HashMap:线程不安全,实现了Map接口
Vector和Hashtable很少使用,因为collections(工具类)中有一个方法可以返回指定类型的线程安全
Collections.synchronizedCollection(Collection<T> c) //返回由指定集合支持的同步(线程安全)集合
Collections.synchronizedList(List<T> list) //返回由指定列表支持的同步(线程安全)列表
Collections.synchronizedSet(Set<T> s) //返回由指定集合支持的同步(线程安全)集合
Collections.synchronizedMap(Map<K,V> m) //返回由指定键值对支持的同步(线程安全)键值对
# 生产者和消费者
生产者和消费者模式是一个十分经典的多线程协作的模式,所谓的生产者消费者,主要包含两类线程:
- 生产者线程用于生产数据
- 消费者线程用于消费数据
为了解耦两者的关系,通常会采用共享的数据区域,就像是一个仓库
- 生产者生产数据之后直接放置在共享数据中,并不需要关心消费者的行为
- 消费者只需要从共享数据区获取数据,并不需要关心生产者的形为

- 等待:生产者生产好了数据,消费者没去消费,这个时候生产者就会提醒消费者去消费
- 唤醒:消费者去消费的时候,还想没有数据,这个时候消费者就会去提醒生产者生产数据
为了体现生产和消费过程中的等待和唤醒,Java提供了几个方法供我们使用,这几个方法在Object类中
- void wait():导致当前线程等待,直到另一个线程条用该对象的notify()方法或notifyAll()方法
- void notify():唤醒正在等待对象监视器的单个线程
- void notifyAll():唤醒正在等待对象监视器的所有线程
注意
这三个方法必须在线程同步的方法内使用 synchronized
//1:奶箱类(Box):定义一个成员变量,表示第x瓶奶,提供存储牛奶和获取牛奶的操作
public class Box {
// 奶的数量
private int milk;
// 定义一个成员变量,表示奶箱的状态
private boolean state = false;
// 存储牛奶,加入synchronized 防止线程安全问题
public synchronized void put(int milk) {
// 如果有奶等待消费
if (state) {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 如果没有奶就生产奶
this.milk = milk;
System.out.println("送奶工将第" + milk + "瓶奶放入奶箱");
// 生产完毕之后,修改奶箱状态
state = true;
// 唤醒其他等待的线程
notifyAll();
}
// 获取牛奶,加入synchronized 防止线程安全问题
public synchronized void get() {
// 如果没有牛奶等待生产
if (!state) {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 如果有牛奶就消费牛奶
System.out.println("用户拿到第" + milk + "瓶奶");
// 消费完毕之后,修改奶箱状态
state = false;
// 唤醒其他等待的线程
notifyAll();
}
}
//2:生产者类(Producer):实现Runnable接口,重写run()方法,调用存储牛奶的操作
public class Producer implements Runnable {
private Box b;
public Producer(Box b) {
this.b = b;
}
@Override
public void run() {
for (int i = 1; i <= 5; i++) {
b.put(i);
}
}
}
//3:消费者类(Customer):实现Runnable接口,重写run()方法,调用获取牛奶的操作
public class Customer implements Runnable {
private Box b;
public Customer(Box b) {
this.b = b;
}
@Override
public void run() {
while (true) {
b.get();
}
}
}
//4:测试类(BoxDemo):里面有main方法,main方法 中的代码步骤如下
public class BoxDemo {
public static void main(String[] args) {
// A:创建奶箱对象,这是共享数据区域
Box b = new Box();
// B:创建生产者对象,把奶箱对象作为构造方法参数传递,因为在这个类中要调用存储牛奶的操作
Producer p = new Producer(b);
// C:创建消费者对象,把奶箱对象作为构造方法参数传递,因为在这个类中要调用获取牛奶的操作
Customer c = new Customer(b);
// D:创建2个线程对象,分别把生产者对象和消费者对象作为构造方法参数传递
Thread t1 = new Thread(p);
Thread t2 = new Thread(c);
// E:启动线程
t1.start();
t2.start();
}
}
# 异步与多线程
# 异步编程
- 在异步模型中,允许同一时间发生(处理)多个事件。程序调用一个耗时较长的功能(方法)时,它并不会阻塞程序的执行流程,程序会继续往下执行。当功能执行完毕时,程序能够获得执行完毕的消息或能够访问到执行的结果(如果有返回值或需要返回值时)
- 在异步编程中,通常会针对比较耗时的功能提供一个函数,函数的参数中包含一个额外的参数,用于回调。而这个函数往往称作回调函数。当比较耗时的功能执行完毕时,通过回调函数将结果返回
# 多线程编程
- 同时并发或并行执行多个指令(线程)。一个简单的示例就是:开启两个浏览器窗口同时下载两个文件。每个窗口都使用一个新的线程去下载文件,它们之间并不需要谁等待谁完成,而是并行进行下载
# 异步与多线程的区别
- 多线程都是关于功能的并发执行。而异步编程是关于函数之间的非阻塞执行,我们可以将异步应用于单线程或多线程当中
- 多线程只是异步编程的一种实现形式,异步和多线程并不是一个同等关系,异步是最终目的,多线程只是实现异步的一种手段
# volatile关键字
volatile是一个非常重要的关键字,它主要用于多线程编程中,保证了共享变量的可见性和禁止指令重排序
# 当一个线程修改了volatile修饰的变量值,其他线程可以立即看到这个修改,保证了共享变量的可见性
# 编译器和处理器在编译和执行代码时,可能会对指令进行重排序,但是volatile关键字可以禁止这种重排序
# volatile和synchronized的区别
# volatile关键字保证了共享变量的可见性和禁止指令重排序,但是无法保证原子性
# 而synchronized关键字可以保证原子性、有序性和可见性
# volatile关键字适用于一些简单的操作,例如++操作,而synchronized关键字适用于复合操作
# volatile关键字不会造成线程阻塞,而synchronized关键字可能会造成线程阻塞
# 网络通信
# InetAddress的使用
InetAddress:方便我们对IP或主机的获取
static InetAddress getByName(String host) //获取主机的IP地址。主机可以是机器名也可以是IP地址
String getHostName() //获取主机名
String getHostAddress() //获取IP地址
public class Main {
public static void main(String[] args) throws UnknownHostException {
InetAddress address = InetAddress.getByName("WxW");
InetAddress address = InetAddress.getByName("192.168.0.105");
InetAddress host = InetAddress.getLocalHost();
System.out.println(host.getAddress());
System.out.println(host.getHostAddress());
System.out.println(host.getHostName());
System.out.println(host.getCanonicalHostName());
}
}
# UDP通信
UDP协议是一种不可靠的网络协议,它在通信的两端各建立一个Socket对象,但是这两个Socket只是发送和接收数据的对象,没有客户端和服务器的概念。Java提供了DatagramSocket类作为基于UDP协议的Socket
# UDP发送数据
- 创建发送的DatagramSocket对象:new DatagramSocket()
- 创建数据包DatagramPacket对象:new DatagramPacket(bytes,len,address,port)
- 调用DatagramSocket对象的方法发送数据: ds.send(dp)
- 关闭发送端: ds.close()
public static void main(String[] args) throws IOException {
// 1:创建发送端的Socket对象(DatagramSocket)
DatagramSocket ds = new DatagramSocket();
// 2:创建数据,并把数据打包
// 构造一个数据包,发送长度为length的数据 包到指定主机上的指定端口号。
byte[] bys = "hello,udp,我来了".getBytes();
int length = bys.length;
InetAddress address = InetAddress.getByName("192.168.0.105");
int port = 10086;
DatagramPacket dp = new DatagramPacket(bys, length, address, port);
// 3:调用DatagramSocket对象的方法发送数据
ds.send(dp);
// 4:关闭发送端
ds.close();
}
# UDP接受数据
- 创建接收端的DatagramSocket对象(端口号):new DatagramSocket(10086)
- 创建一个数据包,用于接收数据:new DatagramPacket(bytes,len)
- 调用DatagramSocket对象的方法接收数据:ds.receive(dp)
- 解析数据包中的数据 dp.getData()
- 关闭接收端: ds.close()
public class ReceiveDemo {
public static void main(String[] args) throws IOException {
// 1:创建接收端的Socket对象(DatagramSocket )
DatagramSocket ds = new DatagramSocket(10086);
// 2:创建一个数据包,用于接收数据
// 构造一个 DatagramPacket用于 接收长度为Length数据包
byte[] bys = new byte[1024];
DatagramPacket dp = new DatagramPacket(bys, bys.length);
// 3:调用DatagramSocket对象的方法接收数据
ds.receive(dp);
// 4:解析数据包,并把数据在控制台显示
// byte[] getData() 返回数据缓仲区
byte[] datas = dp.getData();
// int getLength () 返回要发送的数据的长度或接收到的数据的长度
int len = dp.getLength();
String dataString = new String(datas, 0, len); // 这样写是为了让输出的数据正好而不多余
System.out.println("数据是:" + dataString);
// 5:关闭接收端
ds.close();
}
}
# TCP通信
TCP通信协议是一种可靠的网络协议,它在通信的两端各建立一个Socket对象,并且区分客户端和服务器。Java为客户端提供了Socket类,为服务器端提供了ServerSocket类
# TCP发送数据
- 创建客户端的Socket对象:new Socket(add,port)
- 获取Socket输出流:s.getOutPutStream()
- 写数据:os.write(bytes)
- 释放资源:s.close()
public static void main(String[] args) throws IOException {
// 1:创建客户端的Socket对象(Socket)
// 创建流套接字并将其连接到指定主机上的指定端口号
Socket s = new Socket("192.168.0.105", 1000);
// 2:获取输出流,写数据
// OutputStream getOutputStream () 返回此套接字的输出流
OutputStream os = s.getOutputStream();
os.write("Hello,tcp,我来了".getBytes());
// 3:释放资源
s.close();
}
# TCP接收数据
- 创建服务器端的ServerSocket对象:new ServerSocket(10000)
- 监听客户端连接,返回一个Socket对象:ss.accept()
- 获取输入流,读取数据:s.getInputStream()
- 解析数据包中的数据:is.read(bytes)
- 释放资源:ss.close()
public static void main(String[] args) throws IOException {
// 1:创建服务器端的Socket对象(ServerSocket)
// ServerSocket (int port)创建绑定到指定端口的服务器套接字
ServerSocket ss = new ServerSocket(10000);
//2 Socket accept() 侦听要连接到此套接字并接受它
Socket s = ss.accept();
// 3:获取输入流,读数据,并把数据显示在控制台
InputStream is = s.getInputStream();
byte[] bys = new byte[1024];
int len;
while ((len = is.read(bys)) != -1) {
System.out.println("数据是:" + new String(bys, 0, len));
}
// 4:释放资源
ss.close();
}
# 通信练习
# 发送数据接收反馈,接收数据发送反馈
- 客户端:发送数据,接收服务器反馈
- 服务端:接收数据,给出反馈
# Lambda表达式
- 三要素:形式参数、箭头、代码块,形参就是抽象方法的参数
- Lambda表达式的使用前提是接口中有且仅有一个抽象方法
- Lambda表达式的作用就是重写该抽象方法
new Thread(new Runnable(){
@Override
public void run(){
System.out.printin("多线程启动了")
}
}).start();
//lambda
new Thread(()->{
System.out.printin("多线程启动了")
}).start();
# Lambda表达式的省略规则
- 参数类型可以省略,但是多个参数的情况下,不能只省略一个
- 如果参数只有一个,小括号可以省略
- 如果代码块只有一条语句,可以省略大括号和分号,甚至return
public interface Addable{
int add(int x,int y);
}
public class demo{
public static void main(String[] args){
UserAddable((x,y)->{
return x+y;
})
//省略写法
UserAddable((x,y)-> x + y );
}
public static int UserAddable(Addable a){
int i = a.add(10,20);
return i;
}
}
# Lambda表达式和匿名内部类的区别
- 所需类型不同
- 匿名内部类:可以是接口,也可以是抽象类,还可以是具体类
- Lambda表达式:只能是接口
- 使用限制不同
- 如果接口中有且仅有一个抽象方法,可以使用Lambda表达式,也可以使用匿名内部类
- 如果接口中多于一个抽象方法,只能使用匿名内部类
- 编译方式不同
- 匿名内部类:编译后会产生一个单独的class字节码文件
- Lambda表达式:编译后没有单独的class字节码文件
# 方法引用
在使用Lambda表达式的时候,我们实际上传递进去的代码就是一种解决方案:拿参数做操作
如果在Java方法或自定义方法中已经存在Lambda中所指定的操作方案,我们可以通过方法引用来的方式使用已经存在的方案
# 方法引用符
:: 该符号为方法引用符,而它所在的表达式被称为方法引用,该符号的前面是返回值类型
//1:定义一个接口(Printable):里面定义一个抽象方法
public interface Printable {
void printString(String s);
}
//2:定义一个测试类(PrintableDemo),在测试类中提供两个方法
//一个方法是: usePrintable(Printable p)
//一个方法是主方法,在主方法中调用usePrintable方法
public class PrintableDemo {
public static void main(String[] args) {
//Lambda表达式省略参数类型,是因为方法中有参数类型这样Lambda就可以推导出参数类型。
usePrintable(s -> System.out.println(s));
// 使用方法引用,方法引用符::
//方法引用和Lambda一样都是推导出了参数类型,然后将参数放入println中。
usePrintable(System.out::println);
}
private static void usePrintable(Printable p) {
p.printString("爱生活爱java");
}
}
# Lambda表达式支持的方法引用
- 静态方法引用
- 格式:类名::静态方法
- Lambda表达式被类的静态方法替代的时候,它的形式参数全部传递给静态方法作为参数
- 范例:Integer::parseInt
//1:定义一个接口(Converter),里面定义一个抽象方法
public interface Converter {
int convert(String s);
}
//2:定义一一个测试类(ConverterDemo),在测试类中提供两个方法
//一个方法是: useConverter(Converter c)
//一个方法是主方法,在主方法中调用useConverter方法
public class ConverterDemo {
private static void useConverter(Converter c) {
int number = c.convert("666");
System.out.println(number);
}
public static void main(String[] args) {
// Lambda表达式
// 带有返回值类型的也可以省略
useConverter(s -> Integer.parseInt(s));
// 引用类方法,采用引用类方法格式
//Lambda表达式被类方法替代的时候,它的形式参数全部传递给静态方法作为参数
useConverter(Integer::parseInt);
}
}
//函数式接口
public interface MyInterface {
//比较俩个数的大小
public Integer getMax(int a,int b);
}
//测试类:
public class Test {
public static void main(String[] args) {
//调用比较大小的方法,使用匿名内部类实现
MyInterface mi = new MyInterface() {
@Override
public Integer getMax(int a, int b) {
return Integer.max(a, b);
}
};
System.out.println(mi.getMax(10, 20));
//lambda表达式的简化
MyInterface mi = (a,b)->Integer.max(a, b);
System.out.println(mi.getMax(10, 20));
//静态方法引用
MyInterface mi = Integer::max;
System.out.println(mi.getMax(10, 20));
}
}
- 成员方法引用
- 格式:类名::成员方法
- Lambda表达式被类的成员方法替代时,第一个参数作为调用者,其他参数传递给该方法作为参数
- 范例:String::substring
//1:定义一个接口(MyString),里面定义一个抽象方法
public interface MyString {
String mySubString(String s, int x, int y);
}
//2:定义一个测试类(MyStringDemo),在测试类中提供两个方法
//一个方法是: useMyString(MyString my)
//一个方法是主方法,在主方法中调用useMyString方法
public class MyStringDemo {
private static void useMyString(MyString my) {
String s = my.mySubString("HelloWorld", 2, 5);
System.out.println(s);
}
public static void main(String[] args) {
// Lambda表达式,最简模式
useMyString((s, x, y) -> s.substring(x, y));
// 引用类的实例方法
// Lambda表达式被类的实例方法替代的时候
// 第一个参数作为调用者
// 后面的参数全部传递给该方法作为参数
useMyString(String::substring);
}
}
- 构造方法引用
- 格式:类名::new
- Lambda表达式被构造器替代的时候,它的形式参数全部传递给构造器作为参数
- 范例:Student::new
//1:定义一个类(Student),里面有两个成员变量(name, age)
//并提供无参构造方法和带参构造方法,以及成员变量对应的get和set方法
public class Student {
private String name;
private int age;
public Student() {
super();
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
//2:定义一个接口(StudentBuilder),里面定义一个抽象方法
public interface StudentBuilder {
Student build(String name, int age);
}
//3:定义一个测试类(StudentDemo),在测试类中提供两个方法
//一个方法是: useStudentBuilder(StudentBuilder s)
//一个方法是主方法,在主方法中调用useStudentBuilder方法
public class StudentDemo {
private static void useStudentBuilder(StudentBuilder sb) {
Student s = sb.build("林青霞", 20);
System.out.println(s.getName() + "," + s.getAge());
}
public static void main(String[] args) {
// Lambda表达式
useStudentBuilder((name, age) -> new Student(name, age));
// 引用构造器
// Lambda表达式被构造器替代的时候,它的形式参数全部传递给构造器作为参数
useStudentBuilder(Student::new);
}
}
- 实例方法引用
- 格式:对象::成员方法
- Lambda表达式被对象的实例方法替代的时候,它的形式参数全部传递给该方法作为参数
- 范例:HelloWorld::toUpperCase
//1:定义一个接口(Printer),里面定义一个抽象方法
public interface Printer {
void printUpperCase(String s);
}
//2:定义一个类(PrintString),里面定义一个方法
public class PrintString {
public void printUpper(String s) {
String result = s.toUpperCase();
System.out.println(result);
}
}
//3:定义一个测试类(PrinterDemo),在测试类中提供两个方法
//一个方法是: usePrinter(Printer p)
//一个方法是主方法,在主方法中调用usePrinter方法
public class PrinterDemo {
private static void usePrinter(Printer p) {
p.printUpperCase("HelloWordl");
}
public static void main(String[] args) {
// Lambda表达式,最简化模式
usePrinter(s -> System.out.println(s.toUpperCase()));
// 引用对象的是实例方法
PrintString ps = new PrintString();
usePrinter(ps::printUpper);
}
}
# 函数式接口
函数式接口的条件:
- 有且仅有一个抽象方法的接口,才可以使用Lambda表达式
- @FunctionalInterface注解是可选的,建议加上
@FunctionalInterface
public interface MyInterFace{
void show();
}
public class MyInterFaceDemo{
public static void main(String[] args){
MyInterface my = () -> System.out.printIn("函数式接口");
my.show();
}
}
# 函数式接口作为方法的参数
如果方法的参数是一个函数式接口,我们可以使用Lambda表达式作为参数传递
//定义一个类(RunnableDemo),在类中提供两个方法
//一个方法是: startThread(Runnable r)方法,参数Runnable是一个函数式接口(源码中已添加注解)
//一个方法是主方法,在主方法中调用startThread方法
public class RunnableDemo {
private static void startThread(Runnable r) {
new Thread(r).start();
}
public static void main(String[] args) {
// 使用匿名内部类
startThread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "线程启动");
}
});
// 使用Lambda表达式
startThread(() -> System.out.println(Thread.currentThread().getName() + "线程启动"));
}
}
# 函数式接口作为方法的返回值
如果方法的返回值是一个函数式接口,我们可以使用Lambda表达式作为结果返回
//定义一个类(ComparatorDemo),在类中提供两个方法
//一个方法是: Comparator<String> getComparator() 方法返 回值Comparator是一个函数式接口
//一个方法是主方法,在主方法中调用getComparator方法
public class ComparatorDemo {
private static Comparator<String> getComparator() {
// 匿名内部类,可以直接返回
// return new Comparator<String>() {
//
// @Override
// public int compare(String o1, String o2) {
// // 按照字符串的数量,从少到多排序
// return o1.length() - o2.length();
// }
// };
// Lambda表达式
return (s1, s2) -> s1.length() - s2.length();
}
public static void main(String[] args) {
// 定义集合,存储字符元素
ArrayList<String> array = new ArrayList<>();
array.add("cccc");
array.add("aaa");
array.add("b");
array.add("ddd");
System.out.println("排序前:" + array);
// 这里使用我们自己定义的排序规则
Collections.sort(array, getComparator());
System.out.println("排序后:" + array);
}
}
# 常用的函数式接口
- Supplier接口:Supplier< T > 包含一个无参的方法
- T get():它会按照某种实现逻辑(由Lambda表达式实现)返回一个数据
- Supplier< T >接口也被称为生产型接口,如果我们指定了接口的泛型是什么类型,那么接口中的get方法就会生产什么类型的数据供我们使用
//定义一个类(SupplierTest),在类中提供两个方法
//一个方法是: int getMax(Supplier<Integer> sup)
//用于返回一个int数组中的最大值
//一个方法是主方法,在主方法中调用getMax方法
public class SupplierTest {
// 返回一个int数组中的最大值
private static int getMax(Supplier<Integer> sup) {
return sup.get();
}
public static void main(String[] args) {
// 定义一个int数组
int[] arr = { 13, 34, 56, 23 };
int maxValue = getMax(() -> {
int max = arr[0];
for (int i = 1; i < arr.length; i++) {
if (arr[i] > max) {
max = arr[i];
}
}
return max;
});
System.out.println(maxValue);
}
}
- Consumer接口:Consumer< T > 包含两个方法
- void accept(T t):对给定的参数执行此操作
- default Consumer< T > andThen(Consumer after):返回一个组合的Consumer,依次执行此操作
- Cosumer< T >接口也被称为消费型接口,它消费的数据的数据类型由泛型指定
public class ConsumerTest {
private static void printInfo(String[] arr,Consumer<String> con1,Consumer<String> con2)
{
for (String str : arr) {
// 将con1和con2组合到一起,然后操作
con1.andThen(con2).accept(str);
}
}
public static void main(String[] args) {
String[] strArray = { "林青霞,30", "张曼玉,35", "王祖贤,33" };
// Lambda表达式
printInfo(strArray, (String str) -> {
// 将此字符串拆分为给定的的匹配。
String name = str.split(",")[0];
System.out.print("姓名:" + name);
}, ((String str) -> {
int age = Integer.parseInt(str.split(",")[1]);
System.out.println(",年龄:" + age);
}));
System.out.println("--------------------");
// 简化Lambda表达式
printInfo(strArray, str -> System.out.print("姓名:" + str.split(",")[0]),
str -> System.out.println(",年龄:" + Integer.parseInt(str.split(",")[1])));
}
}
- Function接口:Function< T,R > 包含两个常用方法
- R apply(T t):将此函数应用于给定的参数
- default Function andThen(Function after):返回一个组合函数,首先将该函数应用于输入,然后将after函数用于结果
- Function< T,R >接口常用于对参数T进行处理,然后返回一个新值R
public class FunctionDemo {
public static void main(String[] args) {
// Lambda表达式
convert("100", s -> Integer.parseInt(s));
// 方法引用
// convert("100", Integer::parseInt);
convert(100, i -> String.valueOf(i + 566));
convert("100", s -> Integer.parseInt(s), i -> String.valueOf(i + 566));
}
// 定义一个方法,把一个字符串转换int类型,在控制台输出
private static void convert(String s, Function<String, Integer> fun) {
//R apply(T t):将此函数应用于给定的参数
int i = fun.apply(s);
System.out.println(i);
}
// 定义一个方法,把一个int类型的数据加上一个整数之后,转为字符串在控制台输出
private static void convert(int i, Function<Integer, String> fun) {
String s = fun.apply(i);
System.out.println(s);
}
// 定义一个方法,把一个字符串转换int类型,再把int类型的数据加上一个整数
private static void convert(String s, Function<String, Integer> f1
, Function<Integer, String> f2)
{
Integer i = f1.apply(s);
String ss = f2.apply(i);
System.out.println(ss);
// Function andThen(Function after):返回一个组合函数
// 首先将该函数应用于输入,然后将after函数应用于结果
// String ss = fun1.andThen(fun2).apply(s);
// System.out.println(ss);
}
}
- Predicate接口:Predicate< T > 包含四个常用方法
- boolean test(T t):对给定的参数进行判断(判断逻辑由Lambda表达式实现),返回一个布尔值
- default Predicate< T > negate():返回一个逻辑的否定,对应逻辑非
- default Predicate< T > and(Predicate other):返回一个组合判断,对应短路与
- default Predicate< T > or(Predicate other):返回一个组合判断,对应短路或
- Predicate< T >接口常用于判断参数是否满足指定的条件
//tes(T t)t和negate()方法的使用
public class PredicateDemo01 {
public static void main(String[] args) {
// checkString方法返回一个Boolean类型,直接接受即可
boolean b = checkString(("hello"), s -> s.length() > 5);
System.out.println(b);
}
// 判断给定的字符串是否满足要求
private static boolean checkString(String s, Predicate<String> pre) {
return pre.test(s); //返回false
// 返回一个逻辑的否定,对应逻辑非,和test是相反的结果
// 此操作和 return !pre.test(s):是一样的
// return pre.negate().test(s); //返回true
}
}
//and(Predicate other)方法的使用
public class PredicateDemo02 {
public static void main(String[] args) {
boolean b1 = checkString("hello", s -> s.length() > 5, s -> s.length() < 10);
System.out.println(b1); //返回false
boolean b2 = checkString("hello", s -> s.length() > 3, s -> s.length() < 10);
System.out.println(b2); //返回true
}
// 同一个字符串给出两个不同的判断条件
// 最后把这两个判断的结果做逻辑与运算的结果作为最终的结果
private static boolean checkString(String s, Predicate<String> p1, Predicate<String> p2)
{
return p1.and(p2).test(s);
}
}
//or(Predicate other)方法的使用
public class PredicateDemo02 {
public static void main(String[] args) {
boolean b1 = checkString("hello", s -> s.length() > 5, s -> s.length() < 4);
System.out.println(b1); //返回false
boolean b2 = checkString("hello", s -> s.length() > 3, s -> s.length() < 10);
System.out.println(b2); //返回true
}
// 同一个字符串给出两个不同的判断条件
// 最后把这两个判断的结果做逻辑与运算的结果作为最终的结果
private static boolean checkString(String s, Predicate<String> p1, Predicate<String> p2)
{
return p1.or(p2).test(s);
}
}
# Stream流
# Stream流的常见生成方式
- Collection体系的集合可以使用默认方法stream()生成流
- Map体系的集合间接的生成流
- 数组可以用Stream接口的静态方法of(T…values)生成流
//Stream流的常见生成方式
public class StreamDemo01 {
public static void main(String[] args) {
// 1:Collection体系的集合可以使用默认方法stream ()生成流
// default Stream<E> stream ()
List<String> list = new ArrayList<String>();
Stream<String> listStream = list.stream();
Set<String> set = new HashSet<String>();
Stream<String> setStream = set.stream();
// 2:Map体系的集合间接的生成流
Map<String, Integer> map = new HashMap<String, Integer>();
// 使用key值间接生成Stream流
Stream<String> keyStream = map.keySet().stream();
// 使用value值间接生成Stream流
Stream<Integer> valueStream = map.values().stream();
// 使用键值对间接生成Stream流
Stream<Entry<String, Integer>> entryStream = map.entrySet().stream();
// 3:数组可以通过Stream接口的静态方法of (T... values)生成流
String[] strArray = { "hello", "world", "java" };
Stream<String> strArrayStream = Stream.of(strArray);
// 也可以直接使用参数生成Stream流
Stream<String> strArrayStream2 = Stream.of("hello", "world", "java");
// int类型也可以
Stream<Integer> streamStream3 = Stream.of(10, 20, 30);
}
}
# Stream流的常见中间操作
- Strean< T > filter(Predicate predicate):用于对流中的数据进行过滤
- Strean< T > limit(long maxSize):截取指定个数的数据
- Strean< T > skip(long n):跳过指定个数的数据
- static< T > Strean< T > concat(Stream a,Stream b):合并两个流
- Strean< T > distinct():返回由该流的不同元素组成的流
- Strean< T > sorted():根据自然顺序排序
- < R > Strean< R > map(Function mapper):返回由给定函数应用于此流的元素的结果组成的流
//findFirst:如果一个集合数据是有序的,且你要查找符合条件的第一条数据。这时用findFirst比较合适
Optional<Pig> pigOptional = pigs.stream().filter(a -> a.getAge() > 5).findFirst();
Pig pigOptional = pigs.stream().filter(a -> a.getAge() > 5).findFirst().get();
//findAny:将返回集合中符合条件的任意一个元素
Optional<Pig> anyPig = pigs.stream().filter(a -> a.getAge() < 30).findAny();
Pig anyPig = pigs.stream().filter(a -> a.getAge() < 30).findAny().get();
//判断对象是否存在
boolean b = userList.stream().filter(t -> 3 == t.getId()).findAny().isPresent();
//anyMatch:是否有1条age>50的数据?
Boolean anyOldThan50 = pigs.stream().anyMatch(a -> a.getAge() > 50);
//allMatch:是否所有数据都满足age<50
Boolean allLittleThan50 = pigs.stream().allMatch(a -> a.getAge() < 50);
//noneMatch:是否所有数据都不满足age<50
Boolean noneLittleThan50 = pigs.stream().noneMatch(a -> a.getAge() < 50);
注意
// 根据创建时间倒序排序
.sorted(Comparator.comparing(ProjectDynamic::getGmtCreate).reversed())
//分组查询
list.stream().collect(Collectors.groupingBy(TbCollection::getSpeciesCh))
# Stream流的常见终结操作
- void forEach(Consumer action):对此流的每个元素执行操作
- long count():返回此流中的元素数
//把集合中的元素在控制台输出
list.stream().forEach(System.out::println);
//统计集合中有几个以张开头的元素,并把统计结果在控制台输出
long count = list.stream().filter((s) -> s.startsWith("张")).count();
# Stream流的收集操作
- R collect(Collector collector)
- 但是这个收集方法的参数时一个Collector接口
工具类Collectors提供了具体的收集方法
- public static < T > Collector toList():把元素收集到List集合中
- public static < T > Collector toSet():把元素收集到Set集合中
- public static Collector toMap(Function keyMapper,Function valueMapper):把元素收集到Map集合中
public class CollertDemo {
public static void main(String[] args) {
// 创建List集合
ArrayList<String> list = new ArrayList<String>();
list.add("林青霞");
list.add("张曼玉");
list.add("王祖贤");
list.add("柳岩");
// 需求1:得到名字为3个字的流
Stream<String> listStream = list.stream().filter(s -> s.length() == 3);
// 需求2:把使用Stream流操作完毕的数据收集到List集合中并遍历
List<String> listCollect = listStream.collect(Collectors.toList());
for (String s : listCollect) {
System.out.println(s);
}
// 创建Set集合
Set<Integer> set = new HashSet<Integer>();
set.add(10);
set.add(20);
set.add(30);
set.add(33);
set.add(35);
System.out.println("-----------------");
// 需求3:得到年龄大于25的流
Stream<Integer> setStream = set.stream().filter(i -> i > 25);
// 需求4:把使用Stream流操作完毕的数据收集到Set集合中并遍历
Set<Integer> setCollect = setStream.collect(Collectors.toSet());
for (Integer i : setCollect) {
System.out.println(i);
}
System.out.println("-----------------");
// 创建Map集合
String[] strArray = { "林青霞,30", "张曼玉,35", "王祖贤,33", "柳岩,25" };
// 需求5:得到字符串中年龄数据大于28的流
Stream<String> arrayStream = Stream.of(strArray).filter(s ->
Integer.parseInt(s.split(",")[1]) > 28);
// 需求6:把使用Stream流操作完毕的数据收集到Map集合中并遍历,字符串中的姓名作键,年龄作值
Map<String, Integer> mapStream =
arrayStream.collect(Collectors.toMap(key -> key.split(",")[0],
value -> Integer.parseInt(value.split(",")[1])));
// 遍历mapStream
Set<String> keySet = mapStream.keySet();
for (String key : keySet) {
Integer value = mapStream.get(key);
System.out.println(key + "." + value);
}
}
}
数组输出字符串
intList.stream().map(n -> String.valueOf(n)).collect(Collectors.joining("-"));
# 单元测试
JUnit 是单元测试框架 xUnit 的一个实例,属于白盒测试,一般使用Junit4.x
- 黑盒测试:相当于把程序放入一个黑盒子中,输入值后看是否能够输出期望的值,一般由测试人员完成
- 白盒测试:需要写代码来测试,一般由开发人员测试
# 使用步骤
- 定义一个测试类
- 包名:xxx.xxxx.test com.abc.test
- 被测试的类名+Test CaculatorTest
- 定义测试方法
- 方法名:test+测试的方法名 testAdd()
- 返回值:void
- 参数:空参
- 给方法添加@Test
- 导入junit依赖环境
package test;
import junit.Calculator;
import org.junit.Test;
public class CalculatorTest {
@Test
public void testAdd(){
System.out.println("执行testAdd方法");
//创建对象
Calculator c = new Calculator();
//调用方法
int result = c.add(1, 2);
System.out.println(result);
}
}
# 判定结果
一般我们会使用断言操作来判定结果,红色代表失败,绿色代表成功
//让测试直接出错
Assert.fail() //抛出 AssertionError
Assert.fail(String message) //抛出message错误信息
//断言对象是null
Assert.assertNull(Object object) //抛出 AssertionError
Assert.assertNull(String message, Object object) //抛出message错误信息
//断言两个对象是同一个
Assert.assertSame(Object expected, Object actual) //抛出 AssertionError
Assert.assertSame(String message, Object expected, Object actual) //抛出message错误信息
//断言为true
Assert.assertTrue(boolean condition) //抛出 AssertionError
Assert.assertTrue(String message, boolean condition) //抛出message错误信息
//断言两个值相等
Assert.assertEquals(long expected, long actual) //抛出 AssertionError
Assert.assertEquals(String message, long expected, long actual) //抛出message错误信息
//断言两个对象相等
Assert.assertEquals(Object expected, Object actual) //抛出 AssertionError
Assert.assertEquals(String message, Object expected, Object actual) //抛出message错误信息
//断言两个数组相等
Assert.assertArrayEquals(T[] expected, T[] actual) //抛出 AssertionError
Assert.assertArrayEquals(String message, T[] expected, T[] actual) //抛出message错误信息
//示例
package test;
import junit.Calculator;
import org.junit.Assert;
import org.junit.Test;
public class CalculatorTest {
@Test
public void testAdd(){
System.out.println("执行testAdd方法");
//创建对象
Calculator c = new Calculator();
//调用方法
int result = c.add(1, 2);
//用断言操作
Assert.assertEquals(3,result);
}
}
# 常用注解:
- @Ignore 忽略此方法
- @Before:修饰的非静态方法会在测试方法之前被自动执行,用于资源申请
- @After:修饰的非静态方法会在测试方法执行之后自动被执行,释放资源方法
- @BeforeClass:修饰的静态方法会在全局只执行一次,而且是第一个运行
- @AfterClass:修饰的静态方法会在全局只执行一次,而且是最后一个运行
Junit4 和 Junit5 中所共有功能的对应注解:
package com.test;
import com.person.person;
import org.junit.*;
public class persontest {
@BeforeClass
public static void beforeClass(){
System.out.println("before class:begin this class--------------");
}
@AfterClass
public static void afterClass(){
System.out.println("after class:end this class--------------");
}
@Before
public void before(){
System.out.println("before:begin test");
}
@After
public void after(){
System.out.println("after:end test");
}
@Test
public void TestCount(){
person p =new person();
int count = p.Count(10,20);
Assert.assertEquals(30,count);
}
}
# 反射
反射机制:将类的各个组成部分封装为其他对象,即将类的成员变量封装为Field对象(注意是field 不是filed),将类的构造方法封装为Constructor对象,将成员方法封装为Method对象,这些对象合起来就是一个Class对象,唯一的确定一个类的信息
# 为什么用反射
- 可以在程序运行过程中,操作这些对象,例如:idea提示
- 可以解耦,提高程序的扩展性
# 类加载器
类加载器的作用:
- 负责将.class文件加载到内存中,并为之生成对应的java.lang.Class对象
- ClassLoader:是负责加载类的对象
- static ClassLoader getSystemClassLoader():返回用于委派的系统类加载器
- ClassLoader getParent():返回父类加载器进行委派
public class ClassLoaderDemo {
public static void main(String[] args) {
// static ClassLoader getSystemClassLoader (): 返回用于委派的系统类加载器
ClassLoader c = ClassLoader.getSystemClassLoader();
System.out.println(c); // AppClassLoader
// ClassLoader getParent (): 返回父类加载器进行委派
ClassLoader c2 = c.getParent();
System.out.println(c2); // ExtClassLoader
ClassLoader c3 = c2.getParent();
System.out.println(c3); // null
}
}
//输出
//AppClassLoader:系统类加载器(System)
//ExtClassLoader:平台类加载器(Platform)
//null:内置类加载器(Bootstrap),所以它控制台输出为null
# Java代码在计算机中经历的三个阶段

- Source源代码阶段:java代码编译为class文件,还没进入内存,而是存储在硬盘上
- Class类对象阶段:使用类加载器getClassLoader()将硬盘上的字节码文件加载进内存并生成一个对象
- Runtime运行时阶段:可以使用new创建对象
# 对应Java代码的三个阶段,有三种不同的获取Class对象的方式
- Source源代码阶段
- 此时字节码文件还存储在硬盘中,需要手动将字节码文件加载到内存中,然后生成对应的Class对象
- Class.forName("全类名");将字节码文件加载到内存中,返回Class对象,其中的静态类会自动执行
- 这种方式多用于配置文件,可以将类名写在配置文件中,读取文件后加载类
- Class类对象阶段
- 已经将字节码文件加载进了内存,直接通过类名就可以直接获取
- 类名.class
- 这种方式一般用于参数的传递
- Runtime运行时阶段
- 已经有对象了
- 对象.getclass:直接通过对象继承自Object的getClass()方法就可以获取Class对象
- 多用于对象的获取字节码
public class ReflectTest {
public static void main(String[] args) throws ClassNotFoundException {
//1、Source阶段进行反射
Class clazz1 = Class.forName("java.lang.String");
System.out.println(clazz1);
//2、Class类对象阶段进行反射
Class clazz2 = String.class;
System.out.println(clazz2);
//3、直接通过类名,利用Object类的getClass方法进行反射
Integer i = 0;
Class clazz3 = i.getClass();
System.out.println(clazz3);
}
}
注意
对于同一个字节码文件,在一次程序运行过程中,只会被加载一次,因此也只能创建一个Class文件,因此这三种方式加载的同一个字节码文件的Class文件必然是同一个Class对象
Class对象 即Class字节码文件
# 成员变量
Field getField(String name) //获取指定名称的public修饰的成员变量
Field[] getFields() //获取所有public修饰的成员变量
Field getDeclaredField(String) //获取指定名称的成员变量,不考虑修饰符
Field[] getDeclaredFields() //获取所有成员变量,不考虑修饰符
field.get(Object obj) //获取该类示例对象的成员变量值
field.set(Object obj,Object value) //设置该类示例对象的成员变量值
field.setAccessible(Boolean bool) //暴力反射,忽略权限访问修饰符
//示例
class person {
int fild=3;
static int staticFild=4;
}
public static void main(String[] args) throws Exception
{
Field field=person.class.getDeclaredField("fild");
int a= (Integer)field.get(new person()) ;
//int c= (Integer)field.get(null) ; //不是静态字段不能传null
System.out.println(a);
Field staticfield=person.class.getDeclaredField("staticFild");
int b= (Integer)staticfield.get("") ;
int d= (Integer)staticfield.get(null) ;
System.out.println(b);
System.out.println(d);
Field staticfield=person.class.getDeclaredField("staticFild");
staticfield.setAccessible(true);
staticfield.set(new person(),"李四");
Object o = field.get(p);
System.out.println(o);
}
# 成员方法
Method getMethod(String methodName,Class…… parameterType.class)
Method getMethods()
Method getDeclaredMethod(String methodName,Class…… parameterType.class)
Method getDeclaredMethods()
method.invoke(Object obj,Object…… args) //执行方法,如果方法为void返回null
method.getName() //获取方法名称
method.setAccessible(Boolean bool) //暴力反射,忽略权限访问修饰符
//示例
Method hasMarry = personClass.getDeclaredMethod("hasMarry", boolean.class);
hasMarry.setAccessible(true);
Object invoke = hasMarry.invoke(p, false);
System.out.println(invoke);
System.out.println(hasMarry.getName());
# 构造方法
Constructor getConstructor(Class…… parameterType.class)
Constructor[] getConstructors()
Constructor getDeclaredConstructor(Class…… parameterType.class)
Constructor[] getDeclaredConstructors()
constructor.newInstance(Object…… args) //创建对象,initargs:成员变量的值
constructor.getName() //获取这个类的全类名
constructor.getSimpleName() //获取这个类的简称
Class对象.newInstance() //如果使用空参数构造方法创建对象,可以使用Class对象的newInstance方法
//示例
Constructor constructor = personClass.getConstructor(String.class, int.class, Date.class);
Object o = constructor.newInstance("王五",30,new Date("2000/12/01"));
System.out.println(o);
Object o1 = personClass.newInstance();
System.out.println(o1);
String name = personClass.getName();
System.out.println(name); //com.person.person
String simpleName = personClass.getSimpleName();
System.out.println(simpleName); //person
# 注解
注解(Annotation),也叫元数据,是 JDK1.5之后的新特性,用来说明程序的
# 作用分类
- 编写文档:通过代码里标识的注解生成doc文档【javadoc】
- 代码分析:通过代码里标识的注解对代码进行分析 【使用反射】
- 编译检查:通过代码里标识的注解让编译器能够实现基本的编译检查 【Override】
# JDK中预定义的一些注解
- @Override:表示被注解的方法继承自符类
- @Deprecated:表示被注解的方法已过时
- @SuppressWarnings:表示被注解的方法可以压制警告信息(idea右侧的警告,一般加在类上)
- 一般传递参数all @SuppressWarnings("all")
# 自定义注解
注解的本质:就是一个接口,该接口默认继承自Annotation接口,格式如下:
元注解
public @interface 注解名称{
属性列表 //本质接口中的抽象方法
}
属性的返回值
- 基本数据类型
- String
- 枚举
- 注解
- 以上类型的数组
//注解的属性本质是方法,但此处用作属性,所以属性在起名时尽量像属性些
public @interface AnnotationSylone {
int value();
String str() default "张三";
AnnotationEnum annotationEnum();
Deprecated deprecated();
String[] strArry();
}
使用时需要给属性赋值
- 如果定义属性时,使用default关键字给属性设置默认值,则使用注解时,可以不进行属性的赋值
- 如果只有一个属性需要赋值,并且属性的名称是value,则value可以省略,直接定义值即可
- 数组赋值时,值使用{}包裹。如果数组中只有一个值,则{}可以省略
@AnnotationSylone(value = 10,annotationEnum = AnnotationEnum.电动车,
deprecated = @Deprecated,strArry = {"a","b"})
public int count (int a,int b){
return a+b;
}
元注解:用于描述注解的注解
- @Target:描述注解能够作用的位置
- ElemntType.TYPE:可以作用于类上
- ElemntType.METHOD:可以作用于方法上
- ElmentType.FIELD:可以作用于成员变量上
- @Retention:描述注解被保留的阶段
- RetentionPolicy.SOURCE:被描述的注解会保留到源代码阶段
- RetentionPolicy.CLASS:被描述的注解会保留到加载类阶段
- RetentionPolicy.RUNTIME:被描述的注解会保留到class字节码文件中,并被JVM读取到(自定义注解时常用)
- @Documented:描述注解是否被抽取到api文档中
- @Inheried:描述注解是否被子类继承
@Target({ElementType.TYPE,ElementType.METHOD,ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
public @interface MyAnno3 {
}
# 注解的作用
- 可以获取注解中定义的属性值
Class对象.getAnnotation(注解.class)
Class对象.getAnnotations()
//示例
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface Pro {
String className();
String methodName();
}
@Pro(className = "com.person.person",methodName = "count")
public class AnnotationDemo2 {
public static void main(String[] args) throws ClassNotFoundException,
InvocationTargetException,
NoSuchMethodException,
IllegalAccessException,
InstantiationException {
Class<AnnotationDemo2> annotationDemo2Class = AnnotationDemo2.class;
//注意获取的是Pro
Pro annotation = annotationDemo2Class.getAnnotation(Pro.class);
String className = annotation.className();
String methodName = annotation.methodName();
Class aClass = Class.forName(className);
Object o = aClass.newInstance();
System.out.println(o);
Method method = aClass.getMethod(methodName, int.class, int.class);
Object invoke = method.invoke(o, 10, 30);
System.out.println(invoke);
}
}
- 判断方法上是否有某个注解
method.isAnnotationPresent(注解.class)
//示例
public static void main(String[] args) throws IOException {
Caculator c =new Caculator();
Class caculatorClass = c.getClass();
Method[] methods = caculatorClass.getMethods();
int count = 0;
BufferedWriter bw = new BufferedWriter(new FileWriter("bug.txt"));
for (Method method:methods){
//是否有Check注解
if(method.isAnnotationPresent(Check.class)){
try {
Object invoke = method.invoke(c);
} catch (Exception e) {
count ++;
bw.write(method.getName()+ " 方法出异常了");
bw.newLine();
bw.write("异常的名称:" + e.getCause().getClass().getSimpleName());
bw.newLine();
bw.write("异常的原因:"+e.getCause().getMessage());
bw.newLine();
bw.write("--------------------------");
bw.newLine();
}
}
}
}
# JDBC
Java Database Connectivity
Java语言中用来规范访问数据库程序的接口,然后各个数据库生产商提供这套接口的实现
//第一步:导入数据库驱动jar包mysql-connector-java
import java.sql.*;
public class JDBCDemo1 {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Connection connection=null;
Statement statement=null;
try {
//第二步:注册数据库驱动(加载驱动实现类) --- Driver
Class.forName("com.mysql.jdbc.Driver")
//第三步:使用驱动管理这个类去(DriverManager)获取操作数据库的连接对象
String url="jdbc:mysql://localhost:3306/student02";
//String url="jdbc:mysql:///student02"; //协议和要操作的数据库student02
String uername="root"; //数据库的登录名
String password="123"; //数据库的登录密码
connection = DriverManager.getConnection(url, uername, password);
//第四步:通过连接对象创建能够执行sql语句的statement对象
statement = connection.createStatement();
//第五步:执行sql语句
String sql="INSERT INTO emp(id,NAME,gender,salary,join_date,dept_id)
VALUE(10,'白龙马','男','7800',NULL,'2')";
statement.execute(sql);//出现了错误,释放资源的代码就执行不了了
} catch (SQLException e) {
e.printStackTrace();
} finally {
//关闭连接对象
//为什么要关闭数据库的连接对象---因为数据库连接是有限的,是非常宝贵的。
try {
if(statement!=null){
statement.close();
statement=null; //为了快速被回收掉
}
if(connection!=null){
connection.close();
connection=null;
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
# DriverManager 驱动管理对象
- 注册驱动
- 获取连接
//注册驱动
Driver driver = new Driver()
registerDriver(Driver driver)
//实际开发中一般会采用,因为在com.mysql.cj.jdbc.Driver静态类中已经调用了注册驱动的方法
//在mysql5.0版本之后可以注册驱动,但是建议大家不要省略
//真正起到注册驱动的代码 DriverManager.registerDriver(new Driver());
Class.forName("com.mysql.cj.jdbc.Driver") //将字节码文件加载进内存,自动执行其中的静态类
//获取连接
//url:jdbc:mysql://localhost:3306/test01?useSSL=false&serverTimezone=UTC
//如果连接本地的数据库且端口默认3306可简写为:jdbc:mysql:///test01
Connection conn = DriverManager.getConnection(String url,String user,String pass)
# Connection 数据库连接对象
- 获取执行SQL语句的对象
- 管理事务
//获取执行SQL语句的对象
Statement createStatement() //执行sql
CallableStatement perpareCall() //执行存储过程
PrepareStatement prepareStatement(String sql) //执行带参数sql,解决SQL注入漏洞
//管理事务
void setAutoCommit(boolean autoCommit) //参数为fasle 即开启事务
void commit() //提交事务
void rollback() //回滚事务
//示例
Connection conn = null;
PreparedStatement pstmt = null;
try {
conn = JDBCUtils.getConnection();
// 开启事务
conn.setAutoCommit(false);
String sql = "update account set money=money+? where name=?";
pstmt = conn.prepareStatement(sql);
// 设置参数
pstmt.setDouble(1, -1000);
pstmt.setString(2, "aaa");
pstmt.executeUpdate();
//执行错误
int i = 1 / 0;
pstmt.setDouble(1, 1000);
pstmt.setString(2, "bbb");
pstmt.executeUpdate();
// 提交事务
conn.commit();
} catch (Exception e) {
// 回滚事务
try {
conn.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
}
e.printStackTrace();
} finally {
// 释放资源
JDBCUtils.release(pstmt, conn);
}
# Statement 执行sql的对象
//执行SQL
boolean execute(String sql) //结果是ResultSet对象,则返回true,否则返回false
ResultSet executeQuery(String sq) //返回ResultSet
int executeUpate(String sql) //返回操作的行数
//执行批处理
void addBatch(String sql) //添加多条SQL语句
void clearBatch() //清空Statement对象中的SQL语句
int[] executeBatch() //执行多个SQL语句,返回执行次数的数组
//示例
connection = DBUtils.getConnection();
statement = connection.createStatement();
//批量操作就是给stattement对象添加之后再执行,执行只有一条语句
for (int i = 0; i < 10; i++) {
statement.addBatch("insert into user (name,password)"
+ " values('name=="+i+"','password=="+i+"')");
}
int[] rowCounts = statement.executeBatch();
# PreparedStatement 执行sql的对象
Connection conn = null;
PreparedStatement pstmt = null;
try {
// 获得连接
conn = JDBCUtils.getConnection();
// 编写SQL语句
String sql = "insert into user values (null,?,?,?,?)";
// 预编译SQL
pstmt = conn.prepareStatement(sql);
// 设置参数
pstmt.setString(1, "eee");
pstmt.setString(2, "abc");
pstmt.setString(3, "小兰");
pstmt.setInt(4, 32);
// 执行SQL语句
int i = pstmt.executeUpdate();
if (i > 0) {
System.out.println("添加成功");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 释放资源
JDBCUtils.release(pstmt, conn);
}
注意
插入语句时,自增字段一定要设置为null
# ResultSet结果集对象
boolean next() //从字段名那一行开始(不是数据行),直到返回的是false为止
//结果集的获取
//int结果使用getInt,String结果使用getString
while(rs.next()){
System.out.print(rs.getInt("id") + " ");
System.out.print(rs.getString("username") + " ");
System.out.print(rs.getString("password") + " ");
System.out.print(rs.getString("nickname") + " ");
System.out.print(rs.getInt("age"));
}
getXXX() //方法通常都会有一个重载的方法。
getXXX(int columnIndex) //通过列数来获取数据,列数从1开始
getXXX(String columnLabel) //通过列的名字获取数据,推荐使用本方法
# JDBC的资源释放
JDBC程序执行结束后,将与数据库进行交互的对象释放掉,通常是ResultSet,Statement,Connection
这几个对象中尤其是Connection对象是非常稀有的。这个对象一定要做到尽量晚创建,尽早释放掉
mysal默认的最大连接数100,手动设置的最大连接数只有300或者400左右
//完整示例
Connection con = null;//与数据库连接的对象
Statement stmt= null;//执行SQL的对象
ResultSet rs = null;//存放结果集的对象
// 驱动程序名
final String driver = "com.mysql.cj.jdbc.Driver";
// URL指向要访问的数据库名
final String url = "jdbc:mysql://localhost:3306/jdbc?useSSL=false&serverTimezone=UTC";
// MySQL配置时的用户名
final String user = "root";
// MySQL配置时的密码
final String password = "123456";
// 遍历查询结果集
try {
// 加载驱动程序
Class.forName(driver);
System.out.println("加载驱动成功!");
// 1.getConnection()方法,连接MySQL数据库!!
con = DriverManager.getConnection(url, user, password);
System.out.println("连接数据库!");
// isClosed():检索此Connection对象是否已关闭
if (!con.isClosed()) {
System.out.println("连接到数据库成功!");
}
// 2.创建statement类对象,用来执行SQL语句!!
stmt= con.createStatement();
// 要执行的SQL语句
String sql = "select * from user";
// 3.ResultSet类,用来存放获取的结果集!!
rs = stmt.executeQuery(sql);
while (rs.next()) {
System.out.print(rs.getInt("id") + " ");
System.out.print(rs.getString("username") + " ");
System.out.print(rs.getString("password") + " ");
System.out.print(rs.getString("nickname") + " ");
System.out.print(rs.getInt("age"));
System.out.println();
}
} catch (ClassNotFoundException | SQLException e) {
e.printStackTrace();
} finally {
if (rs != null) {
try {
rs.close();
System.out.println("释放ResultSet成功");
} catch (SQLException e) {
e.printStackTrace();
}
rs = null;
}
if (stmt!= null) {
try {
stmt.close();
System.out.println("释放Statement成功");
} catch (SQLException e) {
e.printStackTrace();
}
stmt= null;
}
if (con != null) {
try {
con.close();
System.out.println("释放Connection成功");
} catch (SQLException e) {
e.printStackTrace();
}
con = null;
}
}
注意
内存泄露,占据内存没有释放,使得内存容量变小
# 数据库连接池
存放数据库连接的容器,直接从内存中获取数据连接可以提升性能,节约资源

# 实现方式
- 标准接口:DataSource(javax.sql包下的)
- 常用方法:获取连接:getConnection() 归还连接:close()
- 一般我们不去实现它,由数据库厂商来实现,数据库厂商常用的技术:
- C3P0:比较老
- Druid:德鲁伊,阿里巴巴提供的
# 数据库连接池-Druid
Druid阿里旗下开源连接池产品,使用非常简单,可以与Spring框架进行快速整合
- 导入jar包(druid的jar包 (opens new window)、数据库驱动jar包)
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.16</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
- 定义配置文件
- 是properties形式的
- 可以叫任意名字,可以放在任意目录下
- initialSize数量要比maxActive小
- druid支持过滤器,可以在获取连接或者调用连接对象的方法时,先调用过滤器,再执行底层方法
driverClassName=com.mysql.cj.jdbc.Driver url=jdbc:mysql://127.0.0.1:3306/test01 username=root password=root initialSize=5 maxActive=10 maxWait=3000 filters=stat(开启SQ运行监控),wall(开启防火墙功能,防御SQL注入攻击),slf4j(打印执行的SQL语句) - 获取数据库连接池对象,通过工厂类获取:DruidDataSourceFactory
- 获取连接:getConnection
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
// 使用连接池,创建连接池对象
DruidDataSource dds = new DruidDataSource();
// 手动设置数据库连接的参数
dds.setDriverClassName("com.mysql.cj.jdbc.Driver");
dds.setUrl(" jdbc:mysql://localhost:3306/jdbc?useSSL=false&serverTimezone=UTC");
dds.setUsername("root");
dds.setPassword("123456");
//使用配置文件获取连接池
Properties pro = new Properties();
pro.load(new FileInputStream("src/db.properties"));// 使用web项目时更换为InputStream
// InputStream is = Demo.class.getClassLoader().getResourceAsStream("druid.properties");
pro.load(is);
dds.setConnectProperties(pro); //或者DruidDataSourceFactory.createDataSource(pro);
// 获得连接
conn = dds.getConnection();
// 编写SQL语句
String sql = "select * from account";
// 预编译SQL
pstmt = conn.prepareStatement(sql);
// 执行SQL
rs = pstmt.executeQuery();
// 遍历结果集
while (rs.next()) {
System.out.println(rs.getInt("id") + " " + rs.getString("name"));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//使用工具类释放资源
JDBCUtils.release(rs, pstmt, conn);
}
# JDBCTemplate
Spring框架对JDBC的简单封装,不需要去释放各种连接
- 导入jar包,下载地址 (opens new window)
<dependency> <groupId>org.springframework</groupId> <artifactId>spring-jdbc</artifactId> <version>5.3.1</version> </dependency> - 创建JDBCTemplate对象,依赖于数据源DataSource
JDBCTemplate tem = new JDBCTemplate(DataSource ds) - 调用JDBCTemplate的方法完成CRUD操作
- update():执行DML语句
- query():将结果封装为JavaBean对象
- 自定义RowMapper的实现类,或者使用RowMapper的系统实现类BeanPropertyRowMapper
- 用BeanProperty给实体类的属性赋值时,要给实体类加上空构造器
- queryForMap():将结果封装为map集合
- 注意查询的结果只能为1条数据
- 将查询的字段名作为key,值作为value,将这条记录封装为map集合
- queryForList():将结果封装为list集合
- 每条数据封装为一个Map集合,再将Map集合装载到List集合中
- queryForObject():将结果封装为对象,一般用户聚合函数的查询
package ln.javatest.day01.demo03;
import ln.javatest.day01.demo02.JDBCUtils;
import org.junit.Test;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.RowMapper;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.List;
import java.util.Map;
public class JDBCTemplateDemo02 {
//获取JDBCTemplate对象
private JdbcTemplate template = new JdbcTemplate(JDBCUtils.getDataSource());
@Test
public void test1(){
String sql = "update student set sorce = 78 where id = 2";
int count = template.update(sql);
System.out.println(count);
}
//2.添加一条记录
@Test
public void test2(){
String sql = "insert into student(id,namee,sorce) values(?,?,?)";
int count = template.update(sql,4,"赵六",88);
System.out.println(count);
}
//3.删除刚才添加的记录
@Test
public void test3(){
String sql = "delete from student where id = ?";
int count = template.update(sql,4);
System.out.println(count);
}
//4.查询id为3的记录,将其封装为Map集合
@Test
public void test4(){
String sql = "select * from student where id = ?";
//注意查询的结果集长度只能为1
Map<String, Object> map = template.queryForMap(sql, 3);
System.out.println(map);
}
//5.查询所有记录,将其封装为List集合
@Test
public void test5(){
String sql = "select * from student";
//每一条记录封装为一个Map集合,再将Map集合装载到List集合中
List<Map<String, Object>> list = template.queryForList(sql);
for (Map<String, Object> stringObjectMap : list) {
System.out.println(stringObjectMap);
}
}
//6.查询所有记录,将其封装为Student对象的List集合
@Test
public void test6(){
String sql = "select * from student";
//自定义的RowMapper
List<Student> list = template.query(sql, new RowMapper<Student>() {
@Override
public Student mapRow(ResultSet rs, int i) throws SQLException {
Student student= new Student();
int id = rs.getInt("id");
String namee = rs.getString("namee");
int sorce = rs.getInt("sorce");
String sex = rs.getString("sex");
int age = rs.getInt("age");
student.setId(id);
student.setNamee(namee);
student.setSorce(sorce);
student.setSex(sex);
student.setAge(age);
return student;
}
});
for (Student student : list) {
System.out.println(student);
}
}
//6.查询所有记录,将其封装为Student对象的List集合
//BeanPropertyRowMapper:这个要求类中的数据得是引用类型数据 int-->Integer
@Test
public void test6_2(){
String sql = "select * from student";
//使用RowMapper的系统实现类BeanPropertyRowMapper
List<Student> list = template.query(sql,
new BeanPropertyRowMapper<Student>(Student.class));
for (Student student : list) {
System.out.println(student);
}
}
//7.查询总记录数,或者单个对象
@Test
public void test7(){
String sql = "select count(id) from student";
//count(id)返回的是long类型的参数
Long total = template.queryForObject(sql, Long.class);
System.out.println(total);
}
}
# DBUtils
Apache组织提供的一个对JDBC的简单封装,不需要去释放各种连接
- 导入jar包,下载地址 (opens new window)
- 创建QueryRunner对象,依赖于数据源DataSource
QueryRunner qr = new QueryRunner(DataSource ds) - 调用QueryRunner的方法完成CRUD操作
- update():执行DML语句
- ResultSetHandler< T >:结果集的处理接口,需要我们使用匿名内部类(handle)的方式把结果集封装,也可以使用以下系统实现类:
- ArrayHandler和ArrayListHandler:可以把数据装到数组当中
- BeanHandler和BeanListHandle:可以将数据装到Javabean当中
- MapHandler和MapListHandler:可以将数据装到Map当中
- ColumnListHandler:将数据中的某列封装到List集合中
- ScalarHandler:将单个值封装
//添加操作
public void demo1() {
QueryRunner qr = new QueryRunner(JDBCUtils2.getDataSource());
try {
qr.update("insert into account values (null,?,?)", "ddd", 10000);
} catch (SQLException e) {
e.printStackTrace();
}
}
//修改操作
public void demo2() {
QueryRunner qr = new QueryRunner(JDBCUtils2.getDataSource());
try {
qr.update("update account set name=?,money=? where name=?", "eee", 100, "ddd");
} catch (SQLException e) {
e.printStackTrace();
}
}
//删除操作
public void demo3() {
QueryRunner qr = new QueryRunner(JDBCUtils2.getDataSource());
try {
qr.update("delete from account where name=?", "eee");
} catch (SQLException e) {
e.printStackTrace();
}
}
//查询一条记录的操作
public void demo1() {
QueryRunner qr = new QueryRunner(JDBCUtils2.getDataSource());
try {
// 执行查询 将结果集返回到封装的对象类中
Account account = qr.query("select * from account where name=?",
new ResultSetHandler<Account>() {
@Override
public Account handle(ResultSet rs) throws SQLException {
//创建Account对象用于将数据封装到对象中
Account account = new Account();
// 遍历结果集
//因为是查询一条记录,使用可以使用if也可以使用while
if(rs.next()) {
//将结果集的数据封装到对象中
account.setId(rs.getInt("id"));
account.setName(rs.getString("name"));
account.setMoney(rs.getDouble("money"));
}
return account;
}
}, "aaa");
System.out.println(account);
} catch (SQLException e) {
e.printStackTrace();
}
}
//查询多条记录
public void demo2() {
QueryRunner qr = new QueryRunner(JDBCUtils2.getDataSource());
try {
// 执行查询
List<Account> list = qr.query("select * from account",
new ResultSetHandler<List<Account>>() {
@Override
public List<Account> handle(ResultSet rs) throws SQLException {
// 创建一个集合用于封装数据
List<Account> list = new ArrayList<Account>();
// 遍历结果集
// 因为是查询一条记录,使用可以使用if也可以使用while
while (rs.next()) {
// 将结果集的数据封装到对象中
Account account = new Account();
account.setId(rs.getInt("id"));
account.setName(rs.getString("name"));
account.setMoney(rs.getDouble("money"));
// 将对象存入List集合
list.add(account);
}
return list;
}
});
// 遍历集合
for (Account account : list) {
System.out.println(account);
}
} catch (SQLException e) {
e.printStackTrace();
}
}
//ArrayHandler:将一条记录封装到一个Object[ ]数组当中
public void demo1() {
QueryRunner qr = new QueryRunner(JDBCUtils2.getDataSource());
try {
//执行SQL
Object[] obj = qr.query("select * from account where name=?",
new ArrayHandler(), "aaa");
System.out.println(Arrays.toString(obj));
} catch (SQLException e) {
e.printStackTrace();
}
}
//ArrayListHandler:将多条记录封装到一个装有Object数组的List集合中
public void demo2() {
QueryRunner qr = new QueryRunner(JDBCUtils2.getDataSource());
try {
//执行SQL
List<Object[]> list = qr.query("select * from account",
new ArrayListHandler());
for (Object[] obj : list) {
System.out.println(Arrays.toString(obj));
}
} catch (SQLException e) {
e.printStackTrace();
}
}
//BeanHandler:将一条记录封装到Javabean中
public void demo3() {
QueryRunner qr = new QueryRunner(JDBCUtils2.getDataSource());
try {
Account account = qr.query("select * from account where name=?",
new BeanHandler<Account>(Account.class),
"aaa");
System.out.println(account);
} catch (SQLException e) {
e.printStackTrace();
}
}
//BeanListHandler:将多条记录封装到一个装有JavaBean的List集合中。
public void demo4() {
QueryRunner qr = new QueryRunner(JDBCUtils2.getDataSource());
try {
List<Account> list = qr.query("select * from account",
new BeanListHandler<Account>(Account.class));
for (Account account : list) {
System.out.println(account);
}
} catch (SQLException e) {
e.printStackTrace();
}
}
//MapHandler:将一条记录封装到一个Map集合中 ,Map的key是列名,Map的value就是表中列的记录值。
public void demo5() {
QueryRunner qr = new QueryRunner(JDBCUtils2.getDataSource());
try {
Map<String, Object> map = qr.query("select * from account where name=?",
new MapHandler(), "aaa");
System.out.println(map);
} catch (SQLException e) {
e.printStackTrace();
}
}
//MapListHandler:将多条记录封装到一个装有Map的list集合中
public void demo6() {
QueryRunner qr = new QueryRunner(JDBCUtils2.getDataSource());
try {
List<Map<String, Object>> list = qr.query("select * from account",
new MapListHandler());
for (Map<String, Object> map : list) {
System.out.println(map);
}
} catch (SQLException e) {
e.printStackTrace();
}
}
//ColumnListHandler:将某列的值封装到List集合当中
public void demo7() {
QueryRunner qr = new QueryRunner(JDBCUtils2.getDataSource());
try {
List<Object> list = qr.query("select name from account",
new ColumnListHandler<>("name"));
for (Object object : list) {
System.out.println(object);
}
} catch (SQLException e) {
e.printStackTrace();
}
}
//ScalarHandler:将单个值封装
public void demo8() {
QueryRunner qr = new QueryRunner(JDBCUtils2.getDataSource());
try {
Object obj = qr.query("select count(*) from account",
new ScalarHandler<>());
System.out.println(obj);
} catch (SQLException e) {
e.printStackTrace();
}
}
事务的使用
public void demo02() throws SQLException{
// 获得连接
Connection conn = null;
try {
//#1 开始事务
conn.setAutoCommit(false);
//.... 加钱 ,减钱
//#2 提交并关闭连接,不抛异常
DbUtils.commitAndCloseQuietly(conn);
} catch (Exception e) {
//#3 回滚并关闭连接,不抛异常
DbUtils.rollbackAndCloseQuietly(conn);
e.printStackTrace();
}
}
# Servlet
通过Servlet我们就能够在不使用main方法的情况下由tomcat帮助我们处理浏览器传来的信息
# Servlet使用步骤
- 定义一个类实现Servlet接口,并重写所有方法
public interface Servlet {
// 负责初始化Servlet对象,容器创建好Servlet对象后由容器调用,只执行一次
// 当load-on-startup设置为负数或者不设置时会在Servlet第一次用到时才被调用
void init(ServletConfig config) throws ServletException;
// 获取该Servlet的初始化参数信息
ServletConfig getServletConfig();
// 负责响应客户端的请求
void service(ServletRequest req, ServletResponse res)
throws ServletException, IOException;
// 返回Servlet信息,包含创建者、版本、版权等信息
String getServletInfo();
// Servlet结束生命周期时调用,释放Servlet对象占用的资源
void destroy();
}
- 在service方法中处理请求
- 其它方法一般不会使用,所以我们也可以通过继承GenericServlet,只需要重写service方法
- 也可以通过继承HttpServlet,然后重写doget和dopost方法

- 在WEB-INF/web.xml文件中配置Servlet的访问路径
<!--配置Servlet的访问路径-->
<servlet>
<servlet-name>ServletDemo1</servlet-name>
<servlet-class>com.example.demo1.ServletDemo1</servlet-class>
<!-- servlet加载时机,若为负数,则在第一次请求时被创建 -->
<!-- 若为0或者正数,在web应用被Servlet容器加载时创建实例,值越小越早被启动 -->
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>ServletDemo1</servlet-name>
<url-pattern>/aaa</url-pattern>
</servlet-mapping>
- Servelt3.0(JavaEE6.0)后使用注解 @WebServlet("/ServletDemo1"),注意区分大小写
- tomcat中的web.xml包含有一个缺省的Servlet
<servlet>
<servlet-name>default</servlet-name>
<servlet-class>org.apache.catalina.servlets.DefaultServlet</servlet-class>
<init-param>
<param-name>debug</param-name>
<param-value>0</param-value>
</init-param>
<init-param>
<param-name>listings</param-name>
<param-value>false</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>default</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
# servlet生命周期
- 被创建:执行init方法,只执行一次
- Servlet对象是一个单例对象,只会被创建一次,多个用户访问可能存在线程安全的问题
- 尽量不要在Servlet中定义成员变量,即使定义了,也不要修改其值
- 提供服务:执行service方法,执行多次
- 被销毁:执行destory方法,只执行一次
- 只有服务器正常关闭才会执行,并且在服务器关闭之前执行
# servlet路径配置
- 完整路径:/ServletDemo1
- 通配符方式:/* /user/* (优先级没有第一种高)
- 后缀名匹配: *.do (优先级没有通配符高)
- 缺省Servlet:/ (当请求的路径没有任何资源匹配的时候执行)
- 多个访问路径:@WebServlet({"/d1","/d2","/d3"})
# HTTP协议
- HTTP协议(超文本传输协议)是基于TCP协议,HTTP在传输数据之前先要建立安全连接
- HTTP协议有不同的版本(三个版本) http1.0 http1.1(现在一般用的是这种) http2.0(未普及)
- 传输过程中数据格式
- get请求:只包含请求行和请求头
- post请求:除了请求行、请求头还包含请求体
- 两者的响应数据都包含相应行、相应头、响应体

# 状态码分类
- 1**(信息):服务器收到请求,需要请求者继续执行操作
- 2**(成功):操作被成功接收并处理
- 3**(重定向):需要进一步的操作以完成请求
- 4**(客户端错误):请求包含语法错误或无法完成请求
- 5**(服务器错误):服务器在处理请求的过程中发生了错误
# HttpServletRequest
//请求行 http://127.0.0.1:8080/day1/demo1?name=zhangsan&age=20
request.getMethod() //获取请求方式 get/post
request.getContextPath() //获取虚拟目录 /day1
request.getServletPath() //获取资源路径 /demo1
request.getRequestURI() //获取请求资源路径 /day1/demo1
request.getRequestURL().toString() //获取请求资源路径 http://127.0.0.1:8080/day1/demo1
request.getQueystring() //获取请求参数 name=zhangsan&age=20
request.getProtocol() //获取请求协议 HTTP/1.1
request.getRemoteAddr() //获取客户机IP地址
//请求头
request.getHeader("Host") //本次请求的主机
request.getHeader("User-Agent") //告诉服务器本次请求的浏览器版本信息(兼容/电脑/手机)
request.getHeader("Accept") //告诉服务器本次请求的数据的格式 text/html/xml
request.getHeader("Accept-language") //本次请求支持的语言
request.getHeader("Accept-Encoding")//本次请求支持的压缩格式
request.getHeader("Referer") //告诉服务器本次请求的来源(防盗链) http://localhost:8080/
request.getHeader("Connection") //HTTP1.1 支持长连接 keep-alive
Enumeration<String> names = request.getHeaderNames(); //获取所有的请求头名称
//Enumeration的循环方式
while(names.hasMoreElements()){
String name = names.nextElement();
String value = request.getHeader(name);
System.out.println(name+"----"+value);
}
//post请求体
ServletInuputStream in = request.getInputStream(); //获取请求体的字节输入流
BufferedReader br = request.getReader(); //获取请求体的字符输入流
br.readline(); //读取一行信息
//当form表单修改为多部分表单时,request.getParameter()将失效
Part part = request.getPart("file"); //获取上传的文件 需要添加注解@MultipartConfig
String fileName = part.getSubmittedFileName(); //上传的文件名
//解决get和post代码有差异的问题,对get和post都适用(方法一致)
request.getParameter("username")
request.getParameter("password")
request.getParameterValues("hobby") //主要利用在多选框上面,一个名字对应多个值
request.getParameterMap() //一次性获取所有请求参数,然后遍历map集合
//获取名称 hasMoreElements//判断 nextElement()//遍历获取名称
Enumeration<String> names = request.getParameterNames();
//post请求中文乱码问题解决方法
request.setCharacterEncoding("utf-8")
//作为域对象存取数据,作用范围是一次请求
request.setAttribute(String name,Object o) //保存数据
request.getAttribute(String name) //获取数据
request.removeAttribute(String name) //移除数据
//请求转发,特点:
//浏览器只会发生了一次请求
//浏览器地址栏不会发生变化
//请求转发的时候只能跳转到服务器内容资源
request.getRequestDispatcher("/success.html").forward(request,response);
# HttpServletResponse
response.setStatus(200) //设置状态码
response.setHeader(String key,String value) //设置响应头
//告诉客户端以什么格式打开响应体数据 in-line:在当前页面打开 attachment:以附件打开
response.setHeader("Content-disposition","attachment;filename=xxx")
response.setHeader("Content-Type","text/html;utf-8") //告诉客户端本次响应体的数据格式及编码
//设置响应体 简单写法
response.setContentType("text/html;utf-8") //需要先设置编码方式
response.setCharacterEncoding("utf-8");
PrintWriter pw = response.getWriter() //获取字符输出流
pw.write("hello") //输出数据
ServletOutputSream sos = response.getOutputStream() //获取字节输出流
sos.write("hello".getBytes()) //输出数据
//重定向
response.sendRedirect(String location)
response.sendRedirect("/web02/demo1.jsp")
# 请求转发与重定向的区别
- 请求转发是一次请求一次响应,而重定向是两次请求两次响应
- 请求转发地址栏不会变化的,重定向地址栏发生变化
- 请求转发路径不带工程名,重定向需要带工程名路径
- 请求转发只能在本网站内部,重定向可以定向到任何网站
# ServletContext
# 获取方式
//通过request对象获取
ServletContext servletcontext = request.getServletContext()
//通过httpServlet获取
ServletContext servletcontext = this.getServletContext()
# ServletContext对象的生命周期
- 创建:项目启动的时候服务器会为每一个项目创建一个ServletContext对象
- 销毁:服务器关闭的时候销毁ServletContext
# 作为域对象共享数据
servletcontext.setAttribute(String name,Object value)
servletcontext.getAttribute(String name)
servletcontext.removeAttribute(String name)
- 域对象的作用范围:整个项目的所有人在任何位置共享数据,一般存储一些单例对象或者全局的数据
- 一个项目唯一对应一个ServletContext,很容易导致内存泄漏,一定要保证数据使用完毕之后及时清除
# 获取文件的MIME类型(格式:大类型/小类型 => text/html)
servletcontext.getMimeType(String filename)
- 通过文件扩展名可以得到文件对应的MIME类型
- 要查找文件的mime类型可以到tomcat/web.xml中可以查看所有文件的mime类型
# 获取文件路径
- 获取当前项目的虚拟路径
- 获取文件的真实(服务器)路径
String path = servletContext.getContextPath();//当前项目的虚拟路径
servletcontext.getRealPath("/a.txt") //web目录下资源访问
servletcontext.getRealPath("/WEB-INI/b.txt") //WEB-INI目录下资源访问
servletcontext.getRealPath("/WEB-INI/classes/c.txt") //java目录下资源访问
# 获取文件所对应的流
通过类加载器只能加载类路径下面的资源,ServletContext能够加载整个web项目的任何资源
DownloadServlet.class.getClassLoader().getResource("").getPath()
InputStream resourceAsStream = servletContext.getResourceAsStream("img/1.jpg");
# 获取配置信息
servletcontext.getInitParameter("contextConfigLocation");
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee
http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<!--配置Listener-->
<listener>
<listener-class>com.qianshun.Listenter.MyListener</listener-class>
</listener>
<!--配置加载的文件-->
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/classes/jdbc.properties</param-value>
</context-param>
</web-app>
# JavaBean
实体类属于javabean
# 成员变量和属性的区别
属性:getter 和 setter 截取后的,大部分情况下和成员变量相同
例如:getUsername() ->去掉get或set:Username ->首字母小写:username
private String sex;
//hehe是属性名
//这个方法操作成员变量sex的值
public Void setHehe(String sex){
this.sex = sex;
}
# beanutils
beanutils下载地址 (opens new window)
//把Bean的属性值放入到一个Map里面
public Map describe(Object bean)
//把Map里面的值封装到Bean对象中
public void populate(Object bean, Map properties)
//设置Bean对象的name的属性值为value
public void setProperty(Object bean, String name, Object value)
//取得bean对象中名为name的属性的值
public String getProperty(Object bean, String name)
//把orig中的值copy到dest中
public void copyProperties(Object dest, Object orig)
# Cookie/Session
# Cookie
数据会保存在浏览器中,只能保存少量的数据到浏览器
//第一次请求服务器,服务器给浏览器响应cookie
Cookie cookie = new Cookie("code",code);
resp.addCookie(cookie);
//再次请求服务器,会携带上一次响应的cookie,然后服务器会获取cookie
Cookie[] cookies = request.getCookies();
if(cookies!=null&&cookies.length>0){
for (int i = 0; i < cookies.length ; i++) {
String name = cookies[i].getName();
String value = cookies[i].getValue();
System.out.println("服务器生成的验证码"+name+":"+value);
}
}
# Cookie在传输过程中存在的位置
- 响应消息的响应头里面会响应set-Cookie:code=OCQ4P,自动保存在浏览器内存中
- 请求消息的请求头里面会携带Cookie:code=OCQ4P,自动携带
# Cookie的相关方法
- 设置cookie的有效路径,以后只有浏览器访问这个路径的资源才会携带这个cookie
String code="123456";
Cookie cookie = new Cookie("code",code);
cookie.setPath("/Cookie03/user");//这里需要设置cookie的真实路径
- 设置Cookie的有效域名,为了cookie的跨域共享实现的
String code="123456";
Cookie cookie = new Cookie("code",code);
cookie.setDomain(".baidu.com"); //在baidu.com的所有二级域名下都可以访问
- 在cookie中使用中文会出现乱码问题
//URL编码
String code="中国";
code = URLEncoder.encode(code, "utf-8");
//解码
code = URLDecoder.decode(code, "utf-8");
- 持久级别的Cookie,这种Cookie不是保存在浏览器的内存中,而是保存(持久化)到硬盘上
//持久级别的cookie:
Cookie cookie = new Cookie("code",code);
//设置cookie的有效时间
cookie.setMaxAge(5*60);//保存五分钟
resp.addCookie(cookie);
//删除持久级别的cookie,可以设置cookie的有效时间为0
Cookie cookie = new Cookie("code","");
cookie.setMaxAge(0);
resp.addCookie(cookie);
# Session
应用在一次会话的多次请求之间,数据保存在服务器中,关闭浏览器之后,Session不会保存之前的数据
//产生验证码保存在服务器的Session里面
HttpSession session = req.getSession();
session.setAttribute("code",code);
//第二次请求服务器的时候,从Session取数据
HttpSession session = request.getSession();
Object code = session.getAttribute("code");
//移除Session中数据
session.removeAttribute(code);
# 基本原理
Session的实现基于cookie
- 用一个唯一的ID去标识Session,两个用户同时访问服务器的时候,会通过携带的ID找到对应的Session
- 第一次请求时没有携带JSessionID,所以第一次请求时是创建Session,然后响应JSessionID给浏览器
- set-Cookie:JSESSIONID:3AC643B6443FAD920FC11D6262F11FD2
- 第二次请求和以后的请求就会标识对应浏览器携带的JSessionID去对应的Session里面去取对应的数据
- Cookie:JSESSIONID:3AC643B6443FAD920FC11D6262F11FD2
# JSP
JAVA Server Pages,本质是一个Servlet,基于Servlet做了一些封装
# JSP的脚本
<%! %>声明脚本:翻译成Servlet中的成员内容<% %>代码块脚本:翻译成Servlet中service方法内的内容<%= %>输出脚本:翻译成Servlet中service方法中的out.print()
注意
- Response.write会优先输出在页面顶部,out可以输出在任意位置
- 尽量不要使用<%! %>定义Servlet成员,防止产生线程安全问题
# JSP的注释
- JSP的注释:
<%-- --%> - Java代码的注释:
- 单行注释://
- 多行注释:/* */
# JSP的指令
- page指令
<%@ page contentType="text/html;chaertset=UTF-8" pageEncoding="UTF-8"%>
+ contentType:设置页面的字符集编码
+ pageEncoding:设置页面保存到本地硬盘上的编码
+ import:引入类对象,可以出现多次: <% @page import="java.util.ArrayList" %>
+ isELIgnored:是否忽略EL表达式,默认false不忽略
+ errorPage:设置错误的友好页面,出现错误后跳转的错误页面
+ isErrorPage:是否显示错误信息,如果设置成true,可以在页面中使用Exception对象获取错误
+ language:使用的语言,目前只能写java
+ buffer:缓冲区大小,一般是8kb
- include指令:在页面中包含其他页面
<%@ include file="top.jsp"%>
- taglib指令:在页面中引入第三方标签库
<%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %>
# JSP的内置对象
在jsp中不需要创建就可以直接使用的对象,共有9个,这些对象全部会被翻译到service方法里面
前4个是域对象,能够在其对应的作用域内共享数据
+ pageContext:只在当前页面共享数据。它能获取其他8个内置对象:pageContext.getRequest()
+ request:一次请求访问的多个资源间共享数据
+ session:一次会话的多个请求间共享数据
+ application:ServletContext对象,整个项目范围内所有用户共享数据
+ response:响应对象
+ page:当前页面(Servlet)的对象,this
+ out:输出对象内容到页面上
+ exception:异常对象,需要配置isErrorPage为true
+ config:ServletConfig的配置对象
out和response.getWriter的区别
out:输出内容对象 类型是JSPWriter 调用println();
response.getWriter:输出响应对象 调用println();
两个对象各有一个缓冲区,最后输出时response先响应给浏览器,out中的内容先在out的缓冲区中,
然后在输出到浏览器的时候将这些内容转移到response缓冲区,然后response缓冲区原来的内容永远在最前面
# EL表达式
Expression Language,语法格式:${EL表达式}
简化JSP的代码,而且减少<% %>的使用,事实证明最后使用编写JSP页面时除了在头部使用<% %>指令外,一般展示数据都是使用EL表达式结合JSTL来动态展示数据
- pageContext用来获取request对象 在jsp页面中动态获取项目的虚拟路径
<a href="${pageContext.request.contextPath}/servletDemo1">servletDemo1</a>
- 获取普通数据,El表达式只能获取域对象中的数据
//设置取域中数据
request.setAttribute("username","tom");
request.getSession().setAttribute("password","123");
request.getServletContext().setAttribute("email","tom@oracle.com");
request.getRequestDispatcher("/el.jsp").forward(request,response);
//获取域中数据
${requestScope.username}
${sessionScope.password}
${applicationScope.email}
//通过域对象调用方法如果值没有获取到是null对象,El表达式获取数据如果没有获取到返回""
${requestScope.name} =>返回空
//可以直接全域查找,碰到那个xxx就返回值
//域对象中查找数据的顺序pageScope -> requestScope -> sessionScope -> applicationScope
${username}
- 获取复杂数据类型
//获取数组(List集合)的数据
${arrs[0]}
${arrs[1]}
//获取Map集合的数据
${map["username"]}
${map["age"]}
//或者
${map.username}
${map.age}
//获取对象的数据
${user.username}
${user.password}
//获取对象的集合的数据
User user1 = new User(1,"aaa","123");
User user2 = new User(2,"bbb","123");
User user3 = new User(3,"ccc","123");
List<User> userList = new ArrayList<User>();
userList.add(user1);
userList.add(user2);
userList.add(user3);
pageContext.setAttribute("userList", userList);
${userList[0].id} - ${userList[0].username} - ${userList[0].password}
${userList[1].id} - ${userList[1].username} - ${userList[1].password}
- 执行运算
pageContext.setAttribute("n1", "10");
pageContext.setAttribute("n2", "20");
pageContext.setAttribute("n3", "30");
pageContext.setAttribute("n4", "40");
${n1 + n2 + n3} //执行算数运算
${n1<n2 && n3 < n4} 执行逻辑运算
${n1 < n2 ? "正确":"错误"} //执行三元运算
//empty运算
${user == null} - ${empty user}
${user != null} - ${not empty user}
- 11个内置对象
1.pageScope
作用:在pageContext域对象中去获取值
用法:${pageScope.xxx}
2.requestScope
作用:在request域对象中去获取值
用法:${requestScope.xxx}
3.sessionScope
作用:在session域对象中去获取值
用法:${sessionScope.xxx}
4.applicationScope
作用:在application域对象中去获取值
用法:${applicationScope.xxx}
5.param
作用:用于在页面接收参数,获取出来是单值,就是说你传个数组来,我只能接受到第一个值
用法:${param.xxx}
6.paramValues
作用:同样用于在页面接收参数,获取出来就是多值
用法:${param.xxx}
7.header
作用:用于获得请求头中的值;
用法:${header['User-Agent']}
8.headerValues
作用:用于获得请求头中的值;
用法:${header['User-Agent']}
9.initParam
作用:可以获得在web.xml中配置的<context-param>中的值
用法:${initParam.name}就可以得到tom
<context-param>
<param-name>name</param-name>
<param-value>tom</param-value>
</context-param>
10.cookie
作用:得到cookie的值,
用法:${cookie.JSESSIONID.value}
因为cookie.JSESSIONID得到的是一个cookie对象,所以需要.value才能得到cookie的值
11.pageContext
作用:获得其他的域,操作其他的域
用法:例如:${pageContext.session.id} 得到session并且得到session的id
# JSTL
它主要提供给Java Web开发人员一个标准通用的标签库,并由Apache的Jakarta小组来维护
开发人员可以利用这些标签取代JSP页面上的Java代码(JSTL和EL结合 替换页面中<% %>),从而提高程序的可读性,降低程序的维护难度
使用JSTL的步骤
- 需要导两个jar包 ---一个标准规范,一个具体实现 java_JSTLjar包
- 在jsp的头部引入第三方的标签库
<%@ taglib prefix="core" uri="http://java.sun.com/jsp/jstl1/core" %>- 使用JSTL标签
核心标签的用法
//判断用户名是否传递过来
<c:if test="${not empty username}">
welcome ${username}
<c:if>
//JSTL里面没有else这个标签
<c:if test="${empty username}">
用户名为空,请重新登录
<c:if>
//普通的循环 fori
<c:forEach var="i" start="0" end="10" step="2">
${i}<br>
</c:forEach>
//增强的循环 iter
//varStatus="status"---用来记录当前变量的状态
<c:forEach var="u" items="${userList}" varStatus="status">
${status.count} //记录当前遍历的次数从1开始
${status.index} //记录当前遍历元素在集合中的索引
${u.id}<br>
${u.username}<br>
</c:forEach>
- JSTL提供的EL的函数库,绝大部分都与String操作相关
//引入函数库<%@ taglib prefix="fn" uri="http://java.sum.com/jsp/jstl/function" %>
${fn:toUpperCase("aaa")} //AAA
${fn:contains("Hello World","Hello")}
${fn:length("HelloWorld")}
${fn:toLowerCase("ABCDE")}
<c:forEach var="i" items='${fn:split("a-b-c-d","-")}'>
${ i }
</c:forEach>
# Filter 过滤器
当访问服务器得资源时,过滤器可以将请求拦截下来,完成一些特殊得功能
web开发三大组件:Servlet、Filter、Listener
# Filter使用步骤
- 定义一个类实现Filter接口,重写方法
- 配置拦截路径
@WebFilter("/*") //访问所有资源之前,都会执行该过滤器
public class FilterTest implements Filter{
//Filter创建时执行得方法,只执行一次
public void init(FilterConfig filterConfig) throws ServletException{
}
//Filter正常销毁时执行的方法
public void destroy(){
}
//拦截请求时执行的方法,每次请求拦截的时候都执行
@Override
public void doFilter(ServletRequest req, ServletResponse res, FilterChain chain)
throw ServletException, IOException{
//放行
chain.doFilter(req,res);
}
}
<!--配置Filter方式,通过web.xml配置-->
<filter>
<filter-name>filterTest</filter-name>
<!--com开头,Filter类名结束-->
<filter-class>com.qianshun.filter.FilterTest</filter-class>
</filter>
<filter-mapping>
<filter-name>filterTest</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
# Filter的执行流程
- 每次请求被Filter拦截的时候先执行doFilter方法
- 在doFilter方法中,需要执行filterChain.doFilter(servletRequest,servletResponse)
- 在这个方法执行前的代码我们可以针对request做增强
- 在这个方法执行后的代码我们可以针对response做增强
配置多个过滤器(过滤器链)时:
- 执行顺序:如果有两个过滤器,过滤器1核过滤器2
- 过滤器1前面
- 过滤器2前面
- 资源执行
- 过滤器2后面
- 过滤器1后面
- 先后顺序的问题
- 注解配置:按照类名字符串比较,值小的先执行
- web.xml配置:filter-mapping 谁定义在上边,谁先执行
# Filter拦截路径的配置
- 具体的资源路径:/index.jsp
- 拦截目录:/user/*
- 后缀名拦截:*.jsp
- 拦截所有资源:/*
# Filter拦截方式的配置
- 注解配置,设置dispatcherTypes属性
- REQUEST:默认值,浏览器直接请求资源
- FORWARD:转发访问资源
- INCLUDE:包含访问资源
- ERROR:错误跳转资源
- ASYNC:异步访问资源
//可以配置多个 @WebFilter(value="/*",dispatcherTypes={DispatcherType.FORWARD,DispatcherType.REQUEST}) - web.xml配置
# 全站中文乱码解决
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse,
FilterChain filterChain) throws IOException, ServletException {
//在这个方法执行前的代码我们可以针对request做增强,用来解决获取请求时的乱码问题
//将ServletRequest转化为HttpServletRequest,可以获取请求参数及配置参数
HttpServletRequest request = (HttpServletRequest) servletRequest;
request.setCharacterEncoding("utf-8");
//放行请求
filterChain.doFilter(servletRequest,servletResponse);
//在这个方法执行后的代码我们可以针对response做增强,用来解决浏览器响应数据的乱码问题
HttpServletResponse response = (HttpServletResponse) servletResponse;
response.setContentType("text/html;charset=utf-8");
}
# 动态代理
可以代理真实对象,增强真实对象的功能,在程序运行期间,在不修改源码的情况下对方法功能进行增强,spring aop就是此原理
使用Proxy的静态方法newProxyInstance,让JVM自动生成一个新的Object对象(class对象),其中包含接口中的所有方法,每个方法都可以调用invoke方法
# 实现步骤
- 代理对象和真实对象实现相同的接口
- 获取代理对象:newProxyInstance()
- 使用代理对象调用方法
- 增强方法(有三种)
- 增强参数列表
- 增强返回值类型
- 增强方法体执行逻辑
//SaleComputer.java
public interface SaleComputer{
public String sale(double money);
public void show();
}
//Lenovo.java
public class Lenovo implements SaleComputer{
@Override
public String sale(double money){
System.out.println("花了"+money+"元买了一台连乡电脑……")
return "联想电脑";
}
@Override
public void show(){
System.out.println("展示电脑……");
}
}
//ProxyTest.java
public class ProxyTest{
public static void main(String[] args){
//创建真实对象:lenovo
Lenovo lenovo = new Lenovo();
//创建代理对象:proxy_lenovo 三个参数:
//真实对象的类型加载器、真实对象的接口数组(保证代理对象和真实对象实现同样的接口)、处理器
Object proxy = Proxy.newProxyInstance(lenovo.getClass().getClassLoader(),
lenovo.getClass().getInterfaces(),new InvocationHandler() {
//代理对象调用的所有方法都会触发该方法执行
//三个参数:代理对象、调用的方法、方法的参数
@Override
public Object invoke(Object proxy,Method method,Object[] args)throws Throwable{
//System.out.println("该方法被执行了……");
//return null;
//1、增强参数
if(method.getName().equals("sale")){
double money = (double)args[0];
money = money *0.85;
//3、增强方法
System.out.println("专车接你……");
Object obj = method.invoke(lenovo,money);
System.out.println("免费送货……");
//2、增强返回值
String flag = (String)obj;
return flag+"赠送鼠标垫";
}else{
Object obj = method.invoke(lenovo,args);
return obj;
}
});
//将代理对象强制转换为接口类型,增强原来对象的方法
//newProxyInstance出来的对象实现了SaleComputer接口,所以可以强转为SaleComputer
//使用多态:基类使用派生类的方法
SaleComputer proxy1 = (SaleComputer) proxy;
String sale = proxy1.sale(8000);
System.out.println(sale);
}
}
//增强request
public void doFilter(ServletRequest req, ServletResponse res, FilterChain chain){
ServletRequest proxy=(ServletRequest)Proxy.newProxyInstance(req.getClass().getClassLoader()
,req.getClass().getInterfaces()
,new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (method.getName().equals("getParameter")) {
Object invoke = method.invoke(req, args);
return invoke;
}
return method.invoke(req, args);
}
});
chain.doFilter(req, res);
}
# JDK的动态代理
基于接口的动态代理技术
//创建一个目标类和接口
public interface TargetInterface {
public void coreWork();
}
public class Target implements TargetInterface {
@Override
public void coreWork() {
System.out.println("===核心业务方法运行===");
}
}
//创建一个增强方法类
public class Advice {
public void before(){
System.out.println("对核心业务方法执行前的增强......");
}
public void after(){
System.out.println("后置增强......");
}
}
//动态代理测试
public class ProxyMain {
public static void main(String[] args) {
// 目标对象
Target target = new Target();
// 增强对象
Advice advice = new Advice();
// 使用父类接口接收
TargetInterface proxy = (TargetInterface) Proxy.newProxyInstance(
//目标对象类加载器
target.getClass().getClassLoader(),
// 目标对象相同的接口字节码对象数组
target.getClass().getInterfaces(),
new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
advice.before(); //前置增强
Object invoke = method.invoke(target, args);
advice.after(); //后置增强
return invoke;
}
}
);
// 通过代理类执行目标类的方法
proxy.coreWork();
}
}
# cglib的动态代理
基于父类的动态代理技术
//创建一个目标类
public class Target{
public void coreWork() {
System.out.println("===核心业务方法运行===");
}
}
//创建一个增强方法类
public class Advice {
public void before(){
System.out.println("对核心业务方法执行前的增强......");
}
public void after(){
System.out.println("后置增强......");
}
}
//动态代理测试
public class ProxyMain {
public static void main(String[] args) {
Target target = new Target();
Advice advice = new Advice();
// 1. 创建增强器
Enhancer enhancer = new Enhancer();
// 2. 设置增强目标类
enhancer.setSuperclass(target.getClass());
// 3. 设置回调
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object o, Method method, Object[] objects
, MethodProxy methodProxy) throws Throwable {
advice.before(); // 前置增强
Object invoke = method.invoke(target, args);
advice.after(); //后置增强
return invoke;
}
});
// 4. 创建代理
// 可以直接使用父类接收
Target targetProxy = (Target) enhancer.create();
targetProxy.coreWork();
}
}
# 监听器 Listener
监听器就是一个实现特定接口的Java程序,用于监听另一个对象的方法调用或属性改变,当被监听对象发生上述事件后,监听的某个方法将立即被执行
JavaWeb中的监听器是用来监听域对象的(request、session、ServletContext)
# ServletContext监听器
- 实现ServletContextListener接口,重写方法
- 配置Listener
//通过注解配置
@WebListener
public class MyListener implements ServletContextListener {
public MyListener() {
}
/**
* 监听ServletContext对象的创建,服务器启动的时候,监听服务器的启动
* 服务器启动的时候可以在这个监听器中去加载资源(加载配置文件)
*/
@Override
public void contextInitialized(ServletContextEvent sce) {
sce.getServletContext().getResourceAsStream("WEB-INF/classes/jdbc.properties");
//或者在下面的web.xml文件中配置
sce.getServletContext().getInitParameter("contextConfigLocation");
}
/**
* 监听ServletContext对象的销毁
* 监听服务器的关闭
*/
@Override
public void contextDestroyed(ServletContextEvent sce) {
}
}
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee
http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<!--配置Listener-->
<listener>
<listener-class>com.qianshun.Listenter.MyListener</listener-class>
</listener>
<!--配置加载的文件-->
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/classes/jdbc.properties</param-value>
</context-param>
</web-app>
# jakarta
换了个爹,所以姓要改
JavaEE 包含了对一系列标准(接口)的实现
javax是java的扩展包,因为后面的x是extension的意思
javax 中的包都只提供了接口,具体的实现是各个开发者、开发团队自己开发的,javax 中并不提供
javax 里面的接口就是 JavaEE 规范的定义
oracle在19年把javax捐给eclipse基金会,但不允许使用javax的命名空间,所以eclipse才继续发展成现在的javaee标准Jakarta,Jakarta 8与javaee 8只是换了个命名空间,jakarta9才是新的发展,spring6与spring boot3会采用Jakarta作为新的命名空间
tomcat 10版本用的就是Jakarta9的标准
# servlet-api
tomcat10中的javax.servlet-api 已经变成 jakarta.servlet-api了
<dependency>
<groupId>jakarta.servlet</groupId>
<artifactId>jakarta.servlet-api</artifactId>
<version>5.0.0</version>
<scope>provided</scope>
</dependency>
IDEA使用 →