# 安装
- [下载地址](https:-- dev.mysql.com/downloads/mysql/)
- MySQL6.X版本开始收费
# MySQL8.X安装方式一
安装过程中出现问题,先卸载,再下载最新版本安装
# Choose a Setup Type:选择Custom
# Select Products and Features:依次点击+,添加MySQL Server
# Authentication Method:选第二个
# Use Strong Password Encryption for Authentication(RECOMIMENDED)
# 使用强密码加密进行身份验证(已升级)
# Use Legacy Authentication Method (Retain MySQL 5.x Compatibility)
# 使用传统身份验证方法(保留MySQL 5.x兼容性)
# MySQL8.X安装方式二
- my.ini 配置文件
[client]
# 设置mysql客户端默认字符集
default-character-set=utf8
[mysqld]
# 设置3306端口
port = 3306
# 设置mysql的安装目录
basedir=C:\\web\\mysql-8.0.11
# 设置 mysql数据库的数据的存放目录,MySQL 8+ 不需要以下配置,系统自己生成即可,否则有可能报错
# datadir=C:\\web\\sqldata
# 允许最大连接数
max_connections=20
# 服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
- 启动 MySQL 数据库
# 切换目录
cd C:\web\mysql-8.0.11\bin
# 初始化数据库
mysqld --initialize --console
# 如果出现无法启动此程序,因为计算机中丢失VCRuntime
# 先下载https:-- www.microsoft.com/zh-cn/download/confirmation.aspx?id=48145
# 再将vcruntime140_1.dll文件放到C:\Windows\System32 和 C:\Windows\SysWOW64下
# 执行完成后,会输出 root 用户的初始默认密码,如:APWCY5ws&hjQ 就是初始密码
A temporary password is generated for root@localhost: APWCY5ws&hjQ
# 输入以下安装命令
mysqld install
# 启动输入以下命令
net start mysql
# 设置环境变量
# 系统变量:Path中添加"mysql安装目录/bin"的路径
# 查看mysql的版本
select version();
# mysql服务
net start mysql # 启动mysql的服务
net stop mysql # 关闭mysql服务
# 登录退出
mysql -uroot -proot # 登录
mysql -hip -uroot -proot # 登录别人计算机中的数据库
exit/quit # 退出 不需要加分号
# 备份还原
-- 备份
mysqldump -uroot -proot 数据库名称 > d:-- data.sql
-- 还原
登录数据库 -> 创建数据库 -> 使用数据库 -> 执行文件(source d:-- data.sql)
# MyISAM与InnoDB的区别
- mysql5.5之前默认使用Myisam,5.6以后默认的为Innodb
- Innodb 支持事务,支持行级锁,更好的恢复性,高并发下性能更好
- Innodb存储文件有frm(表定义文件)、ibd(数据文件)
- Myisam存储文件有frm(表定义文件)、MYD(数据文件)、MYI(索引文件)
# MySQL8.0中的my.ini文件位置说明
该文件在C:\ProgramData\MySQL\MySQL Server 8.0目录下
# 性能
# 最大数据量
- MySQL没有限制单表最大记录数,它取决于操作系统对文件大小的限制
- 单表行数超过500万或者表容量超过2G,才推荐分库分表
# 最大并发数据
max_connections # MySQL实例的最大连接数,上限值事16384
max_user_connections # 服务器响应的最大连接数,每个数据库用户的最大连接数
# 对于mysql最大连接数设置比较理想的是:服务器响应的最大连接数值占服务器上限连接数值的比在10%以上
# 如果在10%以下,说明mysql服务器最大连接上限值设置过高:max_user_connections/max_connections
# 查看最大连接数与响应最大连接数:
show variables like '%max_connections%';
show variables like '%max_user_connections%';
# 在配置文件 my.cnf 中修改最大连接数:
max_connections = 100
max_used_connections = 20
# 查询耗时 0.5 秒
# 建议将单次查询耗时控制在 0.5 秒以内,0.5 秒是个经验值,源于用户体验的 3 秒原则
# 如果用户的操作 3 秒内没有响应,将会厌烦甚至退出
# 响应时间 = 客户端 UI 渲染耗时 + 网络请求耗时 + 应用程序处理耗时 + 查询数据库耗时
# 0.5 秒就是留给数据库 1/6 的处理时间
# 日志
# 查看日志功能是否开启
mysql -uroot -p123
# general_log: OFF表示没有开启普通日志功能
# general_log_file: 这里记录的是普通日志开启以后,日志文件路径
show variables like "%general_log%";
# 临时开启
通过mysql交互终端临时设置
# 设置临时开启,mysql重启后关闭
set global general_log = 'ON';
# 可以不设置日志路径,默认日志路径
set global general_log_file = 'C:/Users/Administrator/general.log';
# 永久开启
通过mysql的配置文件进行参数设置
general-log=1
general_log_file="C:/Users/Administrator/general.log"
# 调整日志时间
mysql日志文件中时间一般跟系统时间是对不上的。原因是mysql的时区是0时区,我们这边是东八区
# 可以发现是UTC,0时区
select @@log_timestamps;
# 如果要永久设置,在上面配置文件中,添加 log_timestamps = SYSTEM
set global log_timestamps=SYSTEM;
# SQL
- DDL(Data Definition Language)数据定义语言
用来定义数据库对象:数据库、表等。关键字:create、drop、alter等 - DML(Data Manipulation Language)数据操作语言
用来对数据库中的数据进行增删改。关键字:insert、delete、update等 - DQL(Data Query Language)数据查询语言
用来查询数据。关键字:select、where等 - DCL(Data Control Language)数据控制语言
用来定义数据库的访问权限和安全级别,及创建用户。关键字:grant、revoke等
注意
- 可以单行或多行书写,以分号结尾
- SQL语句不区分大小写,关键字建议使用大写
# DDL
-- 创建数据库
create database 数据库名 -- 创建数据库
create database if not exists 数据库名 -- 判断不存在,再创建
create database 数据库名 character set 字符集 -- 创建数据库,并指定字符集(gbk、utf8)默认utf8
-- 查询数据库
show databases -- 查询所有数据库
show create database 数据库名 -- 查询某个数据库信息
-- 修改数据库
alter database 数据库名 character set 字符集
-- 删除数据库
drop database 数据库名
drop database if exists 数据库名
-- 使用数据库
use 数据库名 -- 使用数据库
select database() -- 查询当前正在使用的数据库
-- 创建表
create table 表名(列名1 数据类型1,列名2 数据类型2 ……)
CREATE TABLE stu (
id int(11) NOT NULL AUTO_INCREMENT,
username varchar(20) DEFAULT NULL COMMENT '字段的注释',
math int(11) DEFAULT NULL,
english int(11) DEFAULT NULL,
chinese int(11) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
create table 表名 like 被复制的表名 -- 复制表
-- 查询表
show tables -- 查询所有的表名
desc 表名 -- 查询表结构
-- 修改表
alter table 表名 rename to 新的表名 -- 修改表名
alter table 表名 character set 字符集名称 -- 修改表的字符集
alter table 表名 add 列名 数据类型 -- 添加一列
alter table 表名 modify 列名 新数据类型 -- 修改列的类型
alter table 表名 change 列名 新列名 新数据类型 -- 修改列名及类型
alter table 表名 drop 列名 -- 删除列
alter table 表名 modify 列名 comment '修改后的字段注释'
--注意:字段名和字段类型照写就行,如果之前有规定长度 这里也要指定一下
-- 删除表
drop table 表名
drop table if exists 表名
-- 更改表的备注
alter table 表名 comment '修改后的表的注释';
注意
- VARCHAR:长度是可变的,可以节省空间,最长长度为255
例:name VARCHAR(8),存入数据hello,name的字段长度自动变成了5 - CHAR:长度是不可变的,会用空格帮助自动补全
例:name CHAR(10),存入hello,name的字段用空格补充剩余的位置
时间类型设置默认值
设置 datetime 类型的默认值为当前时间,可以使用 DEFAULT CURRENT_TIMESTAMP 选项
在 MySQL8 以下的版本中需要将类型设置为 timestamp
# DML
-- 添加数据
insert into 表名 values (值1,值2……)
insert into 表名(列名1,列名2……) values (值1,值2……)
insert into 表名1(列名1,列名2……) select (列名1,列名2……) from 表名2 -- 不支持select into的写法
-- 删除数据
delete from 表名 -- 不推荐使用,有多少记录就执行多少次
truncate table 表名 -- 推荐使用,效率更高。先删除表,再建张一样的空表
-- 修改数据
update 表名 set 列名1=值1,列名2=值2……
# DQL
-- 基础查询
select distinct 列名1,列名2…… from 表名 -- 去除重复
select ifnull(列名,0) from 表名 -- null参与的运算,计算结果都为nul
select 列名1 as 列名2 from 表名 -- 起别名
select s.username,s.math from stu s -- 表起别名
-- 条件查询
BETWEEN...AND:SELECT * FROM message WHERE age BETWEEN 35 AND 45
LIKE:模糊查询,_:单个任意字符 %:多个任意字符
-- 查询一个字段包含另一个字段内容
select capital,name from world where capital like concat('%',name,'%')
-- 查询一个字段不包含另一个字段内容
select capital,name from world where capital not like concat('%',name,'%')
-- LIMIT 设定返回的记录数 OFFSET指定开始查询的数据偏移量。默认情况下偏移量为0
SELECT column_name FROM table_name [WHERE Clause] [LIMIT N] [ OFFSET M]
-- sqlserver 没有LIMIT使用top
-- 分组查询
select 字段 from 表名 group by 关键字
group by 和 order by一起使用时,order by要在group by的后面
-- having
-- having是group by的一个关键字,只能和group by同时出现
-- 主要作用是进行分组后的数据筛选
-- having类似where(唯一的差别是where过滤行,having过滤组)having支持所有where操作符
-- where后是不能放聚集函数的,having后面可以放聚集函数
SELECT product,SUM(price) FROM orders GROUP BY product HAVING SUM(price)>100
SELECT product,SUM(price) FROM orders WHERE price>100 GROUP BY product HAVING SUM(price)>100
-- 统计重复数据
SELECT COUNT(*) as count, name FROM person GROUP BY name HAVING count > 1
-- 多表查询
select * from dept,emp
-- 显式内连接
select * from dept inner join emp on dept.did = emp.dno
-- 隐式内连接
select * from dept,emp where dept.did = emp.dno
select * from dept d,emp e where d.did = e.dno
-- 左外连接
select * from dept left outer join emp on dept.did=emp.dno -- outer可以省略
-- 外连接
select * from dept right outer join emp on dept.did=emp.dno -- outer可以省略
-- UNION
-- UNION 只会选取不同的值,UNION ALL会选取重复的值
SELECT country FROM Websites UNION SELECT country FROM apps ORDER BY country
SELECT country FROM Websites UNION ALL SELECT country FROM apps ORDER BY country
-- 时间操作
date_format(birthday,'%Y-%m-%d')='2016-08-23' -- 判断日
date_format(birthday,'%Y-%m')='2016-08' -- 判断月
date_format(birthday,'%Y')='2016' -- 判断年
-- 获取日期的年月日 YEAR()、month()、day()
select username, stuid, YEAR(birthday), month(birthday), day(birthday) from student;
# DCL
-- 查询用户
USE mysql -- 切换到mysql数据库
SELECT * FROM user -- Host中的%表示可以在任意主机连接数据库
-- 创建用户
CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码'
-- 删除用户
DROP USER '用户名'@'主机名'
-- 修改密码
UPDATE USER SET PASSWORD('新密码') WHERE USER = '用户名' -- 不适用于mysql8
SET PASSWORD FOR '用户名'@'主机名' = PASSWORD('新密码')
ALTER USER '用户名'@'主机名' IDENTIFIED BY '新密码' -- mysql8.0以上使用
-- 查询权限
SHOW GRANTS FOR '用户名'@'主机名';
-- 授予权限
GRANT '权限列表' ON '数据库名.表名' TO '用户名'@'主机名';
GRANT SELECT,DELETE,UPDATE ON db1.emp TO 'pty'@'localhost';
GRANT ALL ON *.* TO 'pty'@'localhost' -- 授予所有权限,在任意数据库任意表上
-- 注意授予权限后需要刷新权限
flush privileges -- 刷新权限
-- 撤销权限
REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名'
REVOKE UPDATE ON db1.emp FROM 'pty'@'localhost'
忘记MySQL密码
- 1.net stop mysql 停止mysql服务(使用管理员运行)
- 2.使用无验证方式启动mysql服务:mysqld -- skip-grant-tables
- 3.打开新的cmd窗口,直接输入mysql命令,回车。就可以登录成功
- 4.use mysql;
- 5.ALTER USER 'root'@'localhost' IDENTIFIED BY 'root';
- 6.关闭两个窗口
- 7.打开任务管理器,手动结束mysql.exe的进程
- 8.启动mysql服务
- 9.使用新密码登录
# 索引
- 创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件上(一般作为 WHERE 子句的条件)
- 过多的使用索引将会造成滥用。虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件
# 普通索引 Normal
普通索引是最基本的索引,它没有任何限制,值可以为空;仅加速查询
-- 创建索引
CREATE INDEX indexName ON table_name (column_name)
-- 创建表的时候直接指定
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
);
-- 修改表结构(添加索引)
ALTER table tableName ADD INDEX indexName(columnName)
-- 删除索引
DROP INDEX [indexName] ON mytable;
# 唯一索引 Unique
唯一索引与普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值
-- 创建索引
CREATE UNIQUE INDEX indexName ON mytable(username(length))
-- 创建表的时候直接指定
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
UNIQUE [indexName] (username(length))
);
-- 修改表结构(添加索引)
ALTER table mytable ADD UNIQUE [indexName] (username(length))
# 主键索引
主键索引是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值
CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, PRIMARY KEY(ID) );
# 全文索引
FULLTEXT 用于搜索很长一篇文章的时候,效果最好。用在比较短的文本,如果就一两行字的,普通的 INDEX 也可以
-- 创建索引
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` char(255) CHARACTER NOT NULL,
`content` text CHARACTER NULL,
`time` int(10) NULL DEFAULT NULL,
PRIMARY KEY (`id`),
FULLTEXT (content)
);
-- 修改表结构(添加索引)
ALTER TABLE article ADD FULLTEXT index_content(content)
-- 使用全文索引
select * from command where match(instruction) against('directory');
# 空间索引 SPATIAL
mysql支持GIS空间数据,包括创建空间索引,空间索引是对空间数据类型的字段建立的索引,创建空间索引的列,必须将其声明为NOT NULL
-- 创建表时创建空间索引
CREATE TABLE tb_geo(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(128) NOT NULL,
pnt POINT NOT NULL,
SPATIAL INDEX `spatIdx` (`pnt`)
)ENGINE=MYISAM DEFAULT CHARSET=utf8;
# btree索引和hash索引的区别
- BTREE(B树(可以是多叉树))主流使用
- HASH(key,value) 这种方式对范围查询支持得不是很好
# 约束
- 非空约束:not null
- 唯一约束:unique
- 主键约束:primary key
- 自动增长:auto_increment
- 外键约束:foreign key
- 全文索引:fulltext
# 非空约束
create table stu(id int,name varchar(20) not null) -- 创建表时添加非空约束
alter table stu modify name varchar(20) not null -- 创建表后,添加非空约束
alter table stu modify name varchar(20) -- 删除非空约束
# 唯一约束
create table stu(id int,phone varchar(20) unique) -- 创建表时添加唯一约束
alter table stu modify phone varchar(20) unique -- 创建表后,添加唯一约束
alter table stu drop index phone -- 删除唯一约束
# 主键约束
create table stu(id int primary key,name varchar(20)) -- 创建表时添加主键约束
alter table stu modify id int primary key -- 创建表后,添加主键约束
alter table stu drop primary key -- 删除主键约束
# 自动增长
create table stu(id int primary key auto_increment,name varchar(20)) -- 创建表时自动增长
alter table stu modify id int auto_increment -- 创建表后,添加自动增长
alter table stu modify id int -- 删除自动增长
-- 自增初始值设置
ALTER TABLE table_name AUTO_INCREMENT=n;
# 外键约束
外键定义服从下列情况:(前提条件)
- 所有要建立外键的字段必须建立索引
- 只有InnoDB类型的表才支持外键,对于非InnoDB表,FOREIGN KEY会被忽略掉
-- 创建表时添加外键约束
create table 表名(…,外键列 [constraint 外键名] foreign key (外键列) references 主表名(主表列))
CONSTRAINT fk_emp_dept1 FOREIGN KEY(deptId) REFERENCES tb_dept1(id)
-- 创建表后,添加外键约束
alter table 表名 add constraint 外键名 foreign key (外键列名) references 主表名(主表列名)
-- 删除外键约束
alter table 表名 drop foreign key 外键名 -- 只有在定义外键时,使用了constraint 外键名 的情况
alter table drop foreign key -->会提示出错.此时出错信息中,会显示foreign key的系统默认外键名
-- 级联操作
ON DELETE {CASCADE | SET NULL | NO ACTION | RESTRICT}
ON UPDATE {CASCADE | SET NULL | NO ACTION | RESTRICT}
CASCADE -- 外键表中外键字段值会被更新或删除所在的行
SET NULL -- 外键表中外键字段值会被设置为null
RESTRICT -- 也相当于no action,即不进行任何操作,没定义时默认采用restrict
-- 示例一
CREATE TABLE tab_favorite (
rid INT, -- 线路id
DATE DATETIME,
uid INT, -- 用户id
-- 创建复合主键
PRIMARY KEY(rid,uid), -- 联合主键
FOREIGN KEY (rid) REFERENCES tab_route(rid),
FOREIGN KEY(uid) REFERENCES tab_user(uid)
);
-- 示例二
CREATE TABLE parent(id INT NOT NULL,
PRIMARY KEY (id)
) TYPE=INNODB; -- type=innodb 相当于 engine=innodb
CREATE TABLE child(id INT, parent_id INT,
INDEX par_ind (parent_id),
FOREIGN KEY (parent_id) REFERENCES parent(id)
ON DELETE CASCADE
) TYPE=INNODB;
-- child中的parent_id的值只能是parent中有的数据,否则插入不成功
-- 删除parent记录时,child中的相应记录也会被删除;-->因为: on delete cascade
-- 更新parent记录时,不给更新;-->因为没定义,默认采用restrict
# 全文索引
create table stu(
id int primary key auto_increment,
title varchar(255),
body text,
fulltext(title,body));
-- 使用 match against 进行全文搜索
selec * from stu where match(title, body) against('关键词' in natural language mode);
# 事务
- 开启事务:start transaction
- 回滚:rollback
- 提交:commit
-- 示例 张三给李四转账 500 元
SELECT * FROM account;
UPDATE account SET balance = 1000;
-- 开启事务
START TRANSACTION;
-- 张三账户 -500
UPDATE account SET balance = balance - 500 WHERE NAME = 'zhangsan';
-- 李四账户 +500
UPDATE account SET balance = balance + 500 WHERE NAME = 'lisi';
-- 发现执行没有问题,提交事务
COMMIT;
-- 发现出问题了,回滚事务
ROLLBACK;
# 事务的ACID原则
- 原子性(Atomicity):事务作为一个整体被执行,对数据库的操作要么全部被执行,要么都不执行
- 一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态
- 隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行
- 持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中
# 事务的提交方式
- 自动提交
- mysql就是自动提交的
- 执行一条DML(增删改)语句就是自动提交一次事务,每条语句都会自动开启一个事务,语句执行完毕自动提交事务
- 手动提交
- Oracle 数据库默认是手动提交事务
- 需要先开启事务,再提交
# 修改事务的默认提交方式
- 查看事务的默认提交方式:SELECT @@autocommit; 1 代表自动提交 0 代表手动提交
- 修改默认提交方式: set @@autocommit = 0
- 在mysql中修改提交方式为0时,每条DML语句都不会执行成功,需要执行commit
# 事务产生的问题
多个事务之间隔离的,相互独立的。但是如果多个事务操作同一批数据,则会引发一些问题,设置不同的隔离级别就可以解决这些问题
- 脏读:一个事务读取到另一个事务还没提交的数据
- 不可重复读:同一个事务中两次读取到的数据不一样,就是两次读取的结果不同
- 幻读:一个事务操作所有数据,另一个事务添加一条数据,而第一个事务查询不到自己的修改
# 事务的隔离级别
- read uncommitted:事务所作的修改在未提交前,其他并发事务是可以读到的
- 产生的问题:脏读、不可重复读、幻读
set transaction_isolation = 'READ-UNCOMMITTED'; -- 先设置事务隔离级别 start transaction; -- 开启事务 update account set balance = balance - 500 where id = 1; -- 张三减500 update account set balance = balance + 500 where id = 2; -- 李四加500 -- 此时张三未提交事务,但是李四新开一个窗口查询时,发现已经加了500,读取到了未提交的数据 rollback; -- 之后,张三又执行了一步回滚的操作 -- 李四再去查,发现并没有增加500,这样就发生了脏读和不可重复读 - read committed:只能读取到其他并发事务提交的数据,未提交的数据读不到
- 产生的问题:不可重复读、幻读
- repeatable read:每次读取的结果集都相同,而不管其他并发事务有没有提交
- 产生的问题:幻读
set transaction_isolation = 'REPEATABLE-READ'; -- 先设置事务隔离级别 start transaction; -- 开启事务 update account set balance = 1000; update account set balance = balance - 500 where id = 1; -- 张三减500 update account set balance = balance + 500 where id = 2; -- 李四加500 commit; -- 张三这边修改的了数据并提交 start transaction; -- 张三开启事务后,李四也开启了事务 select * from account; -- 返回张三1000,李四1000 -- 李四没有提交事务,就看不到张三修改的数据,只有李四提交后才可以看到 - serializable:串行化,起始就是一个锁表的操作
- 如果一个事务在操作一张数据表,另外一个事务是不可以操作这张表的,只有当这个锁打开后,才可以操作,但这样效率会很低
set transaction_isolation = 'SERIALIZABLE'; -- 先设置事务隔离级别 start transaction; -- 开启事务 update account set balance = 1000; update account set balance = balance - 500 where id = 1; -- 张三减500 update account set balance = balance + 500 where id = 2; -- 李四加500 start transaction; -- 张三开启事务后,李四也开启了事务 select * from account; -- 李四查询时发现光标一直闪烁,代表这个表已经锁定 commit; -- 张三这边提交。李四的操作才会执行
注意
- 隔离级别从小到大安全性越来越高,但是效率越来越低
- 在其他并发事务未提交前,本事务不能修改其他事务修改的数据,需要等待其他事务提交
- 大多数数据库默认为repeatable read级别
- MySQL默认为repeatable read级别
- oracle默认为read commited
# 修改事务的隔离级别
- 查看数据库隔离级别:select @@transaction_isolation
- 数据库设置隔离级别:set transaction_isolation = 'READ-UNCOMMITTED'
如果是使用JDBC对数据库的事务设置隔离级别的话,也应该是在调用Connecton对象的setAutoCommit(false)方法之前,调用Connection对象的setTransactionIsolation(level)即可设置当前连接的隔离级别,至于参数level,可以使用Connection对象的字段
# 函数
CHAR_LENGTH(s) -- 返回字符串 s 的字符数
CONCAT(s1,s2...sn) -- 字符串 s1 s2 等多个字符串合并为一个字符串
FIELD(s,s1,s2...) -- 返回第一个字符串 s 在字符串列表(s1,s2...)中的位置
LOCATE(s1,s) -- 从字符串 s 中获取 s1 的开始位置
LOWER(s) -- 将字符串 s 的所有字母变成小写字母
UPPER(s) -- 将字符串转换为大写
LPAD(s1,len,s2) -- 在字符串 s1 的开始处填充字符串 s2,使字符串长度达到 len
RPAD(s1,len,s2) -- 在字符串 s1 的结尾处添加字符串 s2,使字符串的长度达到 len
LTRIM(s) -- 去掉字符串 s 开始处的空格
RTRIM(s) -- 去掉字符串 s 结尾处的空格
REPLACE(s,s1,s2) -- 将字符串 s2 替代字符串 s 中的字符串 s1
REVERSE(s) -- 将字符串s的顺序反过来
SUBSTR(s, start, length) -- 从字符串 s 的 start 位置截取长度为 length 的子字符串
# 将MySQL结果转换为JSON
MySQL查询结果可以使用MySQL的内置函数JSON_OBJECT()和JSON_ARRAY()来转换为JSON格式
SELECT JSON_OBJECT('name', name, 'age', age) FROM users;
# 跨服务器查询数据
要在服务器A查询服务器B的数据,则需要在服务器A开启federated引擎(默认关闭)以进行映射表查询
-- L执行show engines命令可以查看federated引擎的是否关闭状态
show engines
启用FEDERATED引擎,Linux通过vim /etc/my.cnf修改(Windows修改my.ini),在[mysqld] 下加上federated后保存

并重启数据库服务
service mysqld restart
在mysql中创建远程服务器数据库中的需要映射的表,数据结构一样,映射表名称可以不同
CREATE TABLE `user_remote` (
`id` bigint(20) NOT NULL COMMENT '主键',
`name` varchar(1000) NULL DEFAULT NULL COMMENT '姓名',
`create_date` datetime NULL DEFAULT '1000-01-01 00:00:00' COMMENT '创建时间',
`created_by` bigint(20) NULL DEFAULT NULL COMMENT '创建人'
) ENGINE=FEDERATED CONNECTION='mysql:-- root:passward@172.16.10.10:3306/db/user';
这样就可以将远程的user表数据实时映射到hn_user表中,实现mysql跨服务器查询数据
# 循环方式
-- 使用 LOOP
CREATE PROCEDURE loop_example()
BEGIN
DECLARE counter INT DEFAULT 0;
loop_label: LOOP
SET counter = counter + 1;
IF counter > 5 THEN
LEAVE loop_label; -- 退出循环
END IF;
SELECT counter; -- 输出当前计数
END LOOP;
END
-- 使用 WHILE
CREATE PROCEDURE while_example()
BEGIN
DECLARE counter INT DEFAULT 0;
WHILE counter < 5 DO
SET counter = counter + 1;
SELECT counter; -- 输出当前计数
END WHILE;
END
-- 使用 REPEAT
CREATE PROCEDURE repeat_example()
BEGIN
DECLARE counter INT DEFAULT 0;
REPEAT
SET counter = counter + 1;
SELECT counter; -- 输出当前计数
UNTIL counter >= 5
END REPEAT;
END
# 自定义函数
CREATE FUNCTION function_name(parameter1 datatype, parameter2 datatype)
RETURNS INT
BEGIN
DECLARE i INT DEFAULT 1; -- 设置默认值
DECLARE array_length INT;
DECLARE current_item VARCHAR(100);
-- 函数体
RETURN value;
END;
-- 创建函数后,可以通过 SQL 查询调用它:
SELECT add_numbers(5, 10) AS sum_result;
# 使用游标的存储过程
CREATE DEFINER=`root`@`%` PROCEDURE `loop_table`()
BEGIN
DECLARE done INT DEFAULT FALSE;
DECLARE emp_code VARCHAR(100);
DECLARE emp_name VARCHAR(100);
DECLARE emp_parent_code VARCHAR(100);
DECLARE emp_child bit;
DECLARE emp_pid int;
DECLARE emp_count int;
-- 定义游标
DECLARE emp_cursor CURSOR FOR
SELECT code,name, parent_code,has_child FROM tb_industry;
-- 定义继续处理的条件
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
-- 打开游标
OPEN emp_cursor;
-- 循环遍历
read_loop: LOOP
FETCH emp_cursor INTO emp_code, emp_name, emp_parent_code,emp_child;
IF done THEN
LEAVE read_loop;
END IF;
-- 不要使用 select into
SET emp_pid = (SELECT id FROM tb_industry WHERE code = emp_parent_code COLLATE utf8mb4_0900_ai_ci);
IF emp_pid IS NULL THEN
SET emp_pid = 1;
END IF;
SELECT COUNT(id) into emp_count FROM tb_dicdata WHERE code = emp_code COLLATE utf8mb4_0900_ai_ci;
IF emp_count=0 THEN
INSERT INTO tb_dicdata (code,name,parentid,isend)VALUES (emp_code,emp_name, emp_pid,!emp_child);
END IF;
SET done = FALSE;
END LOOP;
-- 关闭游标
CLOSE emp_cursor;
END
-- 要调用存储过程并执行游标处理,可以使用以下命令:
CALL loop_through_employees();
注意
如果 select into 结果为 null 会跳出循环
# LAST_INSERT_ID(expr)函数
- 核心作用是返回表达式 expr 的值,并记住这个值,作为当前会话中 LAST_INSERT_ID() 函数的返回值
- 最常见的用途是在数据库层面实现自定义的、线程安全的序列号(Sequence)生成器,类似 ORD-0001
无参数 LAST_INSERT_ID()
# 返回最近一次 INSERT 语句为 AUTO_INCREMENT 列自动生成的 ID 值。主要用于获取新插入的自增值
带参数 LAST_INSERT_ID(expr)
# 不关心 AUTO_INCREMENT 列,而是直接返回 expr 的计算结果,并且通过 LAST_INSERT_ID() 直接返回
CREATE TABLE sequence_table (
seq_name VARCHAR(50) PRIMARY KEY,
current_value BIGINT NOT NULL
);
UPDATE sequence_table
SET current_value = LAST_INSERT_ID(current_value + 1)
WHERE seq_name = 'order_number';
SELECT LAST_INSERT_ID(); -- 例如 1001
- 如下写法也可以,在语法和更新操作上是完全正确的。但它只完成了“更新”,没有“获取新值”的功能
- 虽然 UPDATE 本身是原子操作,但在你执行完 UPDATE 后、执行 SELECT 前,另一个客户端可能已经再次修改了这行数据
UPDATE sequence_table
SET current_value = current_value + 1
WHERE seq_name = 'order_number';
注意
会话隔离:LAST_INSERT_ID() 的值是会话级别的,不同客户端连接互不影响
# 空间
# 空间数据形式
- MKT:文本(WKT)格式
- MKB:二进制(WKB)格式
- GEOJSON:用于描述地理空间信息的JSON数据
# 空间数据类型
- 单值类型:GEOMETRY、POINT、LINESTRING、POLYGON
- 集合类型:MULTIPOINT、MULTILINESTRING、MULTIPOLYGON、GEOMETRYCOLLECTION
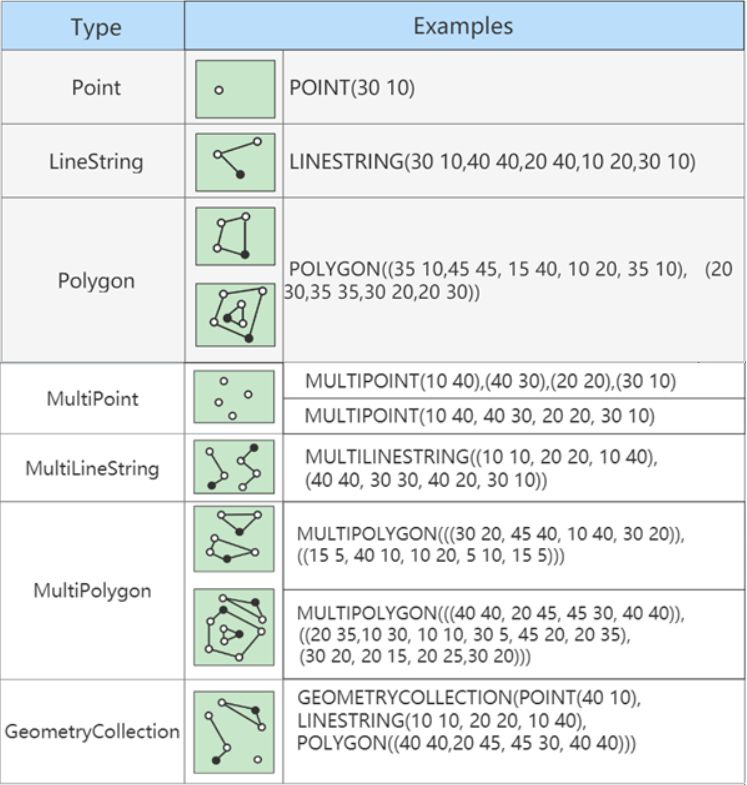
# 格式化空间数据类型(geometry相互转换geojson)
数据库存储的geometry空间数据类型不易于客户端解析,通常会将geometry转为geojson格式
ST_GeomFromGeoJSON -- geojson转geomerty
ST_AsGeoJSON -- geomerty转geojson
ST_GeomFromText -- geomerty字符串转geomerty
-- 示例
select id,point_name,ST_AsGeoJSON(point_geom) as geojson from pointinfo where id = 1
insert into pointinfo(point_name, point_geom)
values("监测点", ST_GEOMFROMTEXT("POINT(117.420671499 40.194914201)"))
insert into pointinfo(point_name, point_geom)
values("监测点", ST_GeomFromText("{\"type\": \"Point\",
\"coordinates\": [117.410671499, 40.1549142015]}"))
# 空间分析查询
- 缓冲区查询:
-- 调用方传来一个geojson字符串及半径(米),使用ST_GeomFromGeoJSON将geojson处理成geometry
-- 再使用ST_BUFFER(geometry, 半径)生成缓冲区空间数据,函数返回的格式也是geometry
-- 所以在外面包一层ST_ASGEOJSON函数将返回结果处理成geojson,便于客户端读取及渲染
SELECT ST_ASGEOJSON(ST_BUFFER(ST_GeomFromGeoJSON('${geojsonStr}'),${radius}))
注意
ST_BUFFER()的参数地理信息及返回值均使用墨卡托坐标系,如非墨卡托坐标系的geojson,需使用工具类进行转换处理
- 距离查询
-- st_distance_sphere 结果(单位:米)
SELECT st_distance_sphere(POINT(121.590346, 31.388096),POINT(121.590345, 31.388095)) AS a
-- st_distance 计算的结果单位是度,需要乘111195(地球半径6371000*PI/180)是将值转化为米
SELECT st_distance(POINT(121.590346, 31.388096),POINT(121.590345, 31.388095))*111195 AS a
-- st_distance_sphere 比 st_distance 结果更准确
- 其他常用的空间函数
ST_INTERSECTS() -- 判断两个几何是否相交
ST_DISTANCE() -- 两个几何的距离
ST_CONTAIONS() -- 几何是否包含
ST_ISVALID() -- 几何是否有效
# 问题
# 关于Mysql [ERR] 1118 - Row size too large (> 8126)解决方法
Mysql 版本:8.0 错误描述:
# [ERR] 1118 - Row size too large (> 8126). Changing some columns to TEXT or BLOB or using
# ROW_FORMAT=DYNAMIC or ROW_FORMAT=COMPRESSED may help. In current row format,
# BLOB prefix of 768 bytes is stored inline.
解决方法:在C:\ProgramData\MySQL\MySQL Server 8.0下找到my.ini文件,增加如下配置项:
[mysqld]
innodb_log_file_size = 512M
innodb_strict_mode = 0
然后重启mysql即可。注意:my.ini 文件需保存为ANSI编码,否则mysql无法启动!
# 创建函数时提示:[Err] 1418 - This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA
# 运行MySQL时提示:[Err] 1418 - This function has none of DETERMINISTIC, NO SQL, or READS SQL
# DATA in its declaration and binary logging is enabled (you *might* want to use the less
# safe log_bin_trust_function_creators variable)
这是我们开启了bin-log, 我们就必须指定我们的函数是否是:
# DETERMINISTIC 不确定的
# NO SQL 没有SQl语句,当然也不会修改数据
# READS SQL DATA 只是读取数据,当然也不会修改数据
# MODIFIES SQL DATA 要修改数据
# CONTAINS SQL 包含了SQL语句
在function里面,如果我们开启了 bin-log, 我们就必须为我们的function指定一个参数。解决方法:
show variables like 'log_bin_trust_function_creators';
set global log_bin_trust_function_creators=1;
show variables like 'log_bin_trust_function_creators';
这样添加了参数以后,如果mysqld重启,那个参数又会消失,因此记得在my.cnf配置文件中添加:
log_bin_trust_function_creators=1