# 计算机硬件
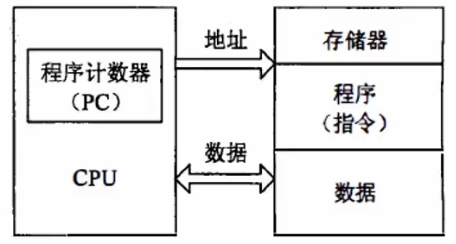
计算机硬件组成结构是由冯.诺依曼提出的称为冯.诺依曼结构,也称普林斯顿结构
# 分为运算器、控制器、存储器、输入设备和输出设备5部分
# 运算器、控制器集成为处理器,输入设备和输出设备集成为总线、接口、外部设备
# 冯.诺依曼结构是一种将程序指令存储器和数据存储器合并在一起的存储器结构
# 程序指令和数据共用一个存储空间,程序指令存储地址和数据存储地址指向同一个存储器的不同物理位置
# 采用单一的地址及数据总线,程序指令和数据的宽度相同
# 处理器执行指令时,先从储存器中取出指令解码,再取操作数执行运算,是一种串行的执行结构
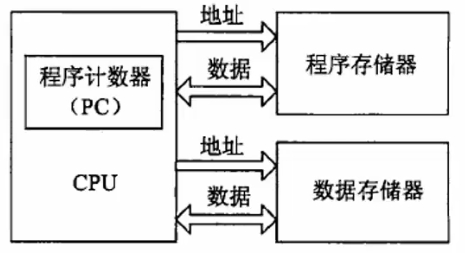
哈佛结构是一种并行体系结构
# 程序指令存储器和数据存储器是两个独立的存储器,在不同的存储空间中,每个存储器独立编址、独立访问
# 有两套独立的地址总线和数据总线,允许在一个机器周期内同时获取指令和操作数,从而提高速度和吞吐率
# 处理器(CPU)
- 主要组成:运算器、控制器、寄存器组(容量小32bit、64bit,速度非常快)、内部总线等部件
- 主要功能:控制器(程序控制、操作控制、时间控制),运算器(数据处理)
- 按使用目的:GPU(图形处理器)、DSP(信号处理器)、FPGA(可编程逻辑门阵列)
运算器的组成:
算数逻辑单元ALU # 实现算术运算和逻辑运算 3
累加寄存器AC # 存储运算结果或源操作数 +5=8
数据缓冲寄存器DR # 暂时存放内存的指令或数据
状态条件寄存器PSW # 保存指令运行结果的状态,如溢出
控制器的组成:
程序计数器PC # 存放指令的地址
指令寄存器IR # 暂存CPU执行指令
指令译码器ID # 分析指令操作码
地址寄存器AR # 保存当前CPU所访问的内存地址
# 指令系统
- 一条指令由操作码(操作要求,如:加减)和操作数(参加运算的数据及其地址也称地址码)组成
- 执行指令的过程:取指令——分析指令——执行指令
# 1、首先将程序计数器PC中的指令地址取出,送到地址总线
# 2、CPU依据指令地址去内存中取出指令内容存入指令寄存器IR
# 3、然后由指令译码器ID进行分析,分析指令操作码
# 4、最后执行指令,取出指令执行所需要的源操作数
注意
CPU 根据指令周期的不同阶段来区分二进制的指令和数据,因为在指令的不同阶段,指令会命令 CPU 分别去取指令或数据
指令的寻址方式:这条指令执行完成后怎么找到下条指令
顺序寻址 # 按照程序计数器的指令地址一条接着一条的顺序执行
跳跃寻址 # 下条指令不是程序计数器给的,而是由本条指令直接给出下条指令的地址
指令操作数的寻址方式:指令在执行过程中怎么找操作数
立即寻址方式 # 指令的地址码中存的不是地址而是操作数本身
直接寻址方式 # 指令的地址码中存的是操作数在主存中的地址
简接寻址方式 # 指令的地址码中存的是操作数B的地址,根据B再找到A
寄存器寻址方式 # 指令的地址码中存的寄存器的编号
基址寻址方式 # 指令的地址码中的地址加上基址寄存器的内容
变址寻址方式 # 指令的地址码中的地址加上变址寄存器的内容
复杂指令系统(CISC)和精简指令系统(RISC)的区别:
复杂指令系统(CISC)
# 兼容性强,指令繁多,长度可变,周期长,多种寻址方式,由微程序实现,以Intel、AMD的x86 CPU为代表
精简指令系统(RISC)
# 指令少,使用频率接近,增加了通用寄存器,适合采用流水线,主要靠硬件实现,以ARM和Power为代表
# 国产处理器目前有龙芯、飞腾、申威等品牌,采用RISC-V、MIPS、ARM等精简指令集架构
指令流水线的原理:将指令分成不同段,每段由不同的部件去处理,产生叠加的效果
RISC中流水线技术:
超流水线技术 # 每条流水线增加指令的分段数,这样并行的部件数量增多
超标量技术 # 增加流水线的数量,依靠硬件来实现
超长指令字技术 # 同超标量技术,只是它是通过软件的方式
流水线的计算方式:
流水线周期 # 指令分成不同执行段,其中执行时间最长的段为流水线周期,指令有时会被称为任务
流水线执行时间 # 1条指令总的执行时间 + (总的指令条数 - 1)* 流水线周期
流水线吞吐率计算 # 单位时间内执行的指令条数:指令条数/流水线执行时间
流水线的加速比计算 # 不使用流水线的执行时间/使用流水线的执行时间
注意
1秒 = 1000ms毫秒
1秒 = 1000000μs微秒
1秒 = 1000000000ns纳秒
# 假设磁盘块与缓冲区大小相同,每个盘块读入缓冲区的时间为15us,由缓冲区送至用户区的时间是5us
# 在用户区内系统对每块数据的处理时间为1us,若用户需要将大小为10个磁盘块的文件逐块从磁盘读入缓冲区
# 并送至用户区进行处理,那么采用单缓冲区需要花费的时间为()us;采用双缓冲区需要花费的时间为()us
# 问题1 A.150 B.151 C.156 D.201
# 问题2 A.150 B.151 C.156 D.201
# 解析
# 在单缓冲区的情况下:
# 一次只能往缓冲区读入一个盘块时间是15us,等把缓冲区里的盘块送入用户区后才能往缓冲区读入下一个盘块
# 注意开始往缓冲区里面读入下一个盘块的同时用户区里的系统就开始对每块数据进行处理了(时间为1us)
# 每个缓冲区读入盘块的间隔是(15us + 5us)因为盘块从读入缓冲区,再到被送入用户区之后
# 缓冲区就马上开始读入下一个盘块了,同时系统处理数据的时间只有1us,而间隔是20us
# 所以当下一个盘块被送入用户区的同时,前一个系统已经处理完数据了
# 所以第十个盘块被送入用户区的同时,前面九个都完成数据处理了
# 所以我们就可以这样算前面九个盘块的时间加上最后一个盘块的处理时间:
# (15+5)x9 + (15+5+1) = 20x10+1 = 201us
# 在双缓冲区的情况下:
# 这里有两个缓冲区,先往第一个缓冲区里面读入盘块,然后第一个缓冲区里的盘块开始被送入用户区的同时
# 第二个缓冲区也能开始读入盘块了,第一个缓存区盘块送入用户区的时间是5us
# 而第二个缓冲区读入完盘块的时间是15us>5us,也就是说当第二个缓冲区读完后,第一个缓冲区已经处理完
# 等着读入数据了,这时候每个缓冲区读入盘块的间隔是15us
# 同理第十个盘块被送入用户区的同时,前面九个都完成数据处理了
# 我们也是用算前面九个盘块的时间加上最后一个盘块的处理时间来算:
# 15x9+(15+5+1)=15x10+5+1=156us
# 校验码
码距
# 在两个编码中,从A码到B码转换所需要改变的位数称为码距,如A:00要转换为B:11,码距为2
# 一般来说,码距越大,越有利于纠错和检错
奇偶校验码
# 在编码中增加1位校验位(1或者0)来使编码中1的个数为奇数(奇校验)
# 编码中含有奇数个1,接收方收到后,会计算收到的编码有多少个1,如果是奇数个则无误,是偶数个则有误
# 在编码中增加1位校验位(1或者0)来使编码中1的个数为偶数(偶校验)
# 奇偶校验码的码距为2(出错位+校验位)
# 奇偶校验只能检测1位错,且无法纠错
循环余冗校验码 CRC
# 首先需要在原始信息位后面加0,多项式的阶为几就加几个0
# 多项式G(x)的最高位和最低为必须是1
# 被除数和出书进行模2除法运算,得到的余数和阶数一致,不足时左侧补0
# 只能检错,无法纠错

# 存储器
根据存储器的硬件结构可分为SRAM、DRAM、NVRAM、Flash、EPROM、Disk等。计算机系统中的存储器通常采用分层的体系结构,按照与处理器的物理距离可分为4个层次。
片上缓存
# 在处理器核心中直接集成的缓存,一般为SRAM结构,可实现数据的快速读取,容量较小一般为16kb-512kb
片外缓存
# 在处理器核心外的缓存,需要经过交换互联开关访问,一般也是由SRAM构成,容量略大,可以为256kB~4MB
# 按照层级被称为 L2Cache或 L3Cache, 或者称为平台 Cache
主存(内存)
# 通常采用DRAM结构,以独立的部件/芯片存在,通过总线与处理器连接
# 依赖不断充电维持其中的数据,容量在数百MB至数十GB之间
外存
# 可以是磁带、磁盘、光盘和各类Flash等介质器件,访问速度慢,但容量大,且在掉电后能够保持其数据
# Cache
- 存储最活跃的程序和数据,位于CPU和主存之间直接和CPU交互,容量小速度快,由半导体材料构成
- 由控制部分【判断CPU访问的数据是否在Cache中,在则命中不在则替换】和存储器【存储数据】组成
替换算法: 使Cache尽可能高的命中,常用算法:
随机替换算法、先进先出算法(FIFO)、近期最少使用算法、优化替换算法
地址映射: 在CPU工作时送出的是主存单元的地址,但是需要从Cache存储器中读写数据,这就需要将主存地址转换为Cache存储器地址,这种转换称为地址映射,由硬件自动完成,分为下列三种方法:
直接映像
# 将Cache等分成块(比如1KB),主存先分组(比如1M)再等分成块(比如1KB)并编号
# 二者编号相同才命中(可以是1组的1块也可以是2组的1块),变换简单但不灵活,且容易浪费资源
全相连映像
# 将Cache等分成块(比如1KB),主存不分组直接等分成块(比如1KB)并编号
# 主存中任意一块都与Cache中任意一块对应,变换复杂速度慢,但是最不容易发生冲突
组组相连映像
# 前两种方式的结合,将Cache和主存都是先分组(比如1M)再等分成块(比如1KB)
# 组间采用直接映像,组内采用全相连映像
命中率及平均时间: 当CPU所访问的数据在Cache中则命中,不在则需要从内存中读取
# 若读取一次Cache的时间为1ns,读取一次内存的时间为100ns,CPU在多次读取数据过程中,有90%命中Cache
# 则CPU读取一次的平均时间为:(90%*1+10%*1000)ns
# 磁盘结构和参数
磁盘有正反两个盘面,每个盘面有多个同心圆,每个同心圆是一个磁道,每个磁道又被划分为多个扇区,数据就存放在扇区中。
寻道时间(平均定位时间、移臂时间) # 指磁头移动到磁道所需要的时间
等待时间(转动延迟时间、磁盘转速) # 指磁头转到待读写扇区下方的时间
其中寻道时间耗时较长,需要重点调度,有如下的调度算法:
先来先服务FCFS # 根据进程请求磁盘的先后顺序进行调度
最短寻道时间优先SSTF # 请求访问的磁道与当前磁道最近的优先调度
扫描算法SCAN # 又称电梯算法,磁头在磁盘上双向移动,一直移动完才掉头
单向扫描调度算法CSCAN # 与SCAN不同的是,只做单向移动

# 输入输出技术
计算机系统中存在多种内存与接口地址的编址方法(主存与外部设备):
独立的编制方法
# 内存地址与接口地址是完全独立的两个地址空间
# 缺点是用于接口的指令太少、功能太弱
统一的编制方法
# 内存地址与接口地址在一个公共的地址空间里,用于内存的指令全都可以用于接口
# 缺点是内存地址被分成两部分不连续
计算机和外设间的数据交互方式(CPU与外部设备):
程序控制(查询、直接)方式 # CPU主动查询外设是否完成数据传输(类似同步执行),效率极低
程序中断方式 # 外设完成数据传后,像CPU发送中断,等待CPU处理数据,效率相对较高
DMA方式(直接主存存取)
# CPU只需要完成初始化操作,数据传输由DMA控制器完成,在主存和外设之间直接建立数据通道,效率很高
注意
在一个总线周期结束后,CPU会相应DMA请求开始读取数据
CPU相应程序中断方式请求是在一条指令执行结束后
# 总线结构
总线(bus)是计算机设备和设备间传输信息的公共通道,可将计算机系统内的多种设备连接到总线上。
广义上讲任何连接两个以上电子元器件的导线都可以称为总线,通常分为以下三类:
内部总线 # 芯片级总线,芯片与处理器之间通信的总线
系统总线 # 板级总线,用于计算机内各部分的连接,分为数据总线、地址总线、控制总线
外部总线 # 设备级总线,用于连接外部设备
# 如RS232(串行总线适合长距离低速传输)、SCSI(并行总线适合短距离高速传输)、USB
数据总线 # 数据并行传输的位数,如32位、64位
地址总线 # 系统可以管理的内存空间大小,如32位的系统最多支持2^32个字节,即4GB的内存
控制总线 # 传输控制命令
总线之间通过桥实现连接,它是一种特殊的外设,主要实现总线协议间的转换。
总线的性能指标:总线带宽、总线服务质量、总线时延、总线抖动等。
单工 # 任意时刻只能在一个方向上传输信息
半双工 # 同一时刻可以在两个方向上传输信息
全双工 # 任意时刻可以在两个方向上传输信息
并行总线与串行总线的区别:
| 名称 | 数据线 | 特点 | 应用 |
|---|---|---|---|
| 并行总线 | 多条双向数据线 | 有传输延迟,适合近距离传输 | 系统总线 |
| 串行总线 | 一条双向数据线或两条单项数据线 | 速率不高,但适合长距离连接 | 通信总线 |
# 接口
接口是指同一计算机不同功能之间的通信规则,常见的有:
显示类接口 # HDMI、DVI
网络类接口 # RJ45、FC
音频输入输出类接口 # TRS、RCA、XLR
USB接口、SATA接口、RS232接口等
# 计算机软件
# 操作系统概述
操作系统的三个重要作用:
- 管理计算机中运行的程序和分配各种软硬件资源
- 为用户提供友善的人机界面
- 为应用程序的开发和运行提供一个高效率的平台
操作系统的4个特征是:
并发性、共享性、虚拟性、不确定性
并发 # 指在一段时间内交替去执行任务。指的是任务数多于CPU核数时,通过操作系统的各种任务调用算法
# 来实现用多个任务"一起"(看上去是一起)执行的效果。(分时段切换执行)
并行 # 指的是任务数小于等于cpu核数,即任务真的是一起执行的
操作系统的功能:
进程管理 # 对CPU的执行时间进行管理,将CPU的时间合理的分配给每个任务
文件管理 # 主要包括文件相关的管理
存储管理 # 对主存空间进行管理
设备管理 # 对硬件设备的管理
作业管理 # 包括任务、界面管理、人机交互、图形界面、语音控制、虚拟现实等
操作系统的分类:
批处理操作系统 # 分为单道批处理(同时处理一个任务)和多道批处理(同时处理多个任务)
分时操作系统 # 将CPU的工作时间划分为多个很短的时间片,轮流为各个终端的用户服务
实时操作系统 # 计算机对外来的信息以足够快的速度进行处理并在被控对象允许的时间内做出响应
网络操作系统 # 使联网计算机能方便有效的共享网络资源,分为:集中模式、客户端/服务器模式、对等模式
分布式操作系统 # 多个分散的计算机连接而成的计算机系统,系统中的计算机无主次之分,任意两台可以通信
微机操作系统 # 常用的有windows、mac os、linux
嵌入式操作系统的特点:
微型化 # 从性能和成本角度考虑,希望占用的资源和系统代码量少、内存少、字长短
可定制 # 要求嵌入式操作系统能针对硬件变化进行结构与功能上的配置,以满足不同应用需要
实时性 # 嵌入式操作系统主要应用于需要迅速响应的场合,所以对实时性要求较高
可靠性 # 系统构件、模块和体系结构必须达到应有的可靠性,对关键要害应用还要提供容错和防故障措施
易移植性 # 为了提高系统的易移植性,通常采用硬件抽象层和板级支撑包的底层设计技术
注意
嵌入式系统初始化过程按照自底向上、从硬件到软件的次序依次为:
片级初始化 -> 板级初始化 -> 系统初始化
# 进程组成和状态
- 进程的组成:
进程控制块PCB # 进程的唯一标志
程序 # 描述程序要做什么
数据 # 存放进程执行时所需数据
- 三态图:任务数大于cpu的核数时,一定有一些任务正在执行,而另外一些任务在等待cpu。进程基础的状态是下图左侧的三态图
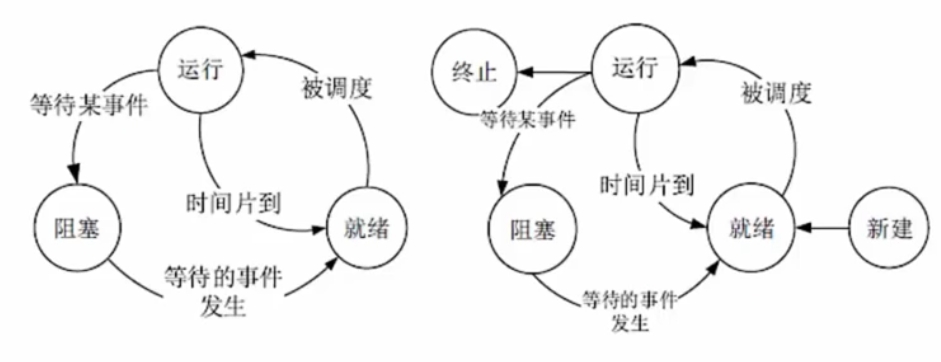
运行:已经有了CPU
就绪:就差CPU
阻塞:有了CPU后,需要额外的数据,后被CPU抛弃
运行和就绪可以相互转换
阻塞需要先到就绪再到运行
就绪也不能直接到阻塞
- 前驱图:用来表示哪些任务可以并行,哪些任务之间有顺序关系
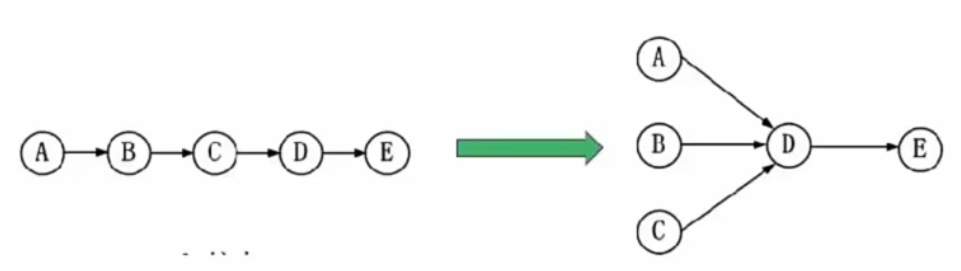
A B C 可以并行,但必须是 A B C 都执行完后才能执行D
反映了两点:
# 任务间的并行及先后顺序
# 每个箭头代表一个信号量,执行完后释放信号量
进程资源图:表示进程和资源之间的分配和请求关系
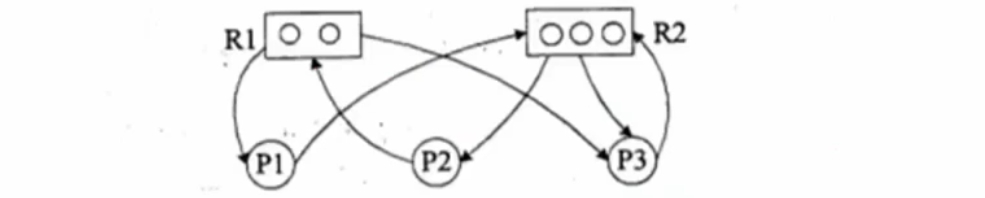
P代表进程,R代表资源,R方框里有几个圆就代表几个资源
# R1指向P1,表示R1有一个资源分配给了P1
# P1指向R2,表示P1还需要请求一个R2资源才能执行
阻塞节点 # 某进程所请求的资源已经全部分配完毕,无法获取所需资源,如P2
非阻塞节点 # 某进程所请求的资源还有剩余,可以分配给该进程继续运行,如P1、P3
死锁状态 # 所有进程都是阻塞节点的时候就陷入死锁状态
注意
R2虽然只剩余1个被2个节点需要,此时资源分配后,进程执行完会被回收,继续被其他进行使用 进程资源图化简的方法:先执行非阻塞节点,再回收分配给它的节点
- PV操作图:
互斥 # 在同一时间内只能由一个任务单独使用,使用时需要加锁,解锁后才能被其他任务使用,如打印机
同步 # 多个任务可以并发执行,只不过有速度上的差异,不存在资源是否单独或共享的问题
临界资源 # 进程间以互斥方式进行访问的资源
临界区 # 对临界资源实施操作的那段程序,本质是一段程序代码
互斥信号量 # 对临界资源采用互斥访问,使用互斥信号量后其他进程无法访问,初始值为1
同步信号量 # 对共享资源的访问控制(控制的是总量),初始值一般是共享资源的数量
互斥信号量和同步信号量都有两个操作:P操作和V操作
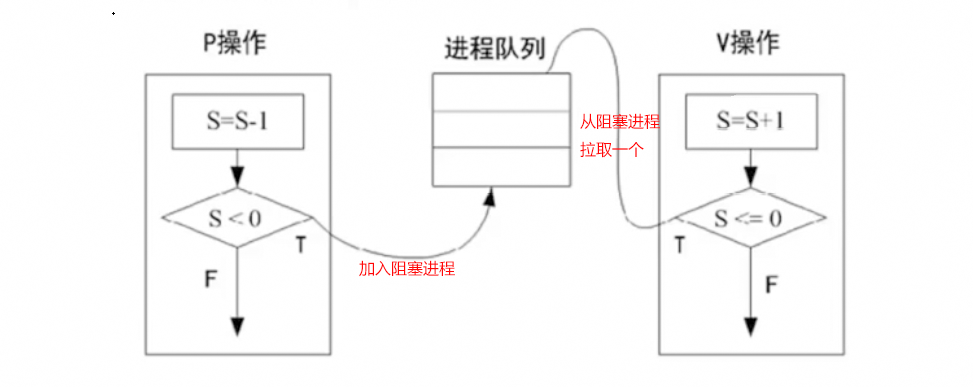
P操作 # 申请资源,资源数减1(S=S-1)
# S>=0 时进程继续执行,S<0 时该进程为阻塞状态(无资源可用),并将其插入阻塞队列
V操作 # 释放资源,资源数加1(S=S+1)
# S>0 时进程继续执行,S<=0 时,从阻塞队列唤醒一个进程插入就绪队列,然后该进程继续执行
# 进程调度
进程调度方式是指当有更高优先级的进程到来时如何分配CPU,分为可剥夺和不可剥夺两种。
一个作业从提交到完成需要经历高、中、低三级调度:
高级调度 # 也称作业调度(一组进程),它决定将哪个后备作业调入主系统做好就绪准备
中级调度 # 它决定将交换区的哪个进程调入内存,参与对CPU的竞争
低级调度 # 它决定将处于内存中的哪个进程可以占用CPU,低级调度最活跃、最重要,对系统的影响最大
调度算法:
先来先服务FCFS # 先到达的进程先分配CPU,用于宏观调度
时间片轮转 # 分配给每个进程的CPU时间片,轮流使用CPU,用于微观调度
优先级调度 # 每个进程都有一个优先级,优先级大的先分配CPU
多级反馈调度 # 时间片轮转和优先级调度结合而成,队列间是优先级调度,队列内是时间片轮转
# 死锁
若系统中有很多进程处于死锁状态,就会造成系统死锁
死锁产生的四个必要条件:
资源互斥
每个进程占有资源并等待其他资源
系统不能剥夺进程资源
进程资源图是一个环路
解决死锁的措施是打破四大条件,有下列方法:
死锁预防 # 采用某种策略限制并发进程对资源的请求,破坏死锁产生的四个条件之一
死锁避免 # 采用银行家算法,提前计算出一条不会死锁的资源分配方法,才分配资源,否则不分配资源
死锁检测 # 允许死锁产生,但系统定时运行一个检测死锁的程序,若检测到死锁则设法解除
死锁解除 # 如强制剥夺资源,撤销进程等
死锁资源计算:系统内有n个进程,每个进程都需要R个资源
发生死锁的最大资源数为:n*(R-1) # 每个进程都处于死锁状态
不发生死锁的最小资源数为:n*(R-1)+1 # 解锁其中的一个进程
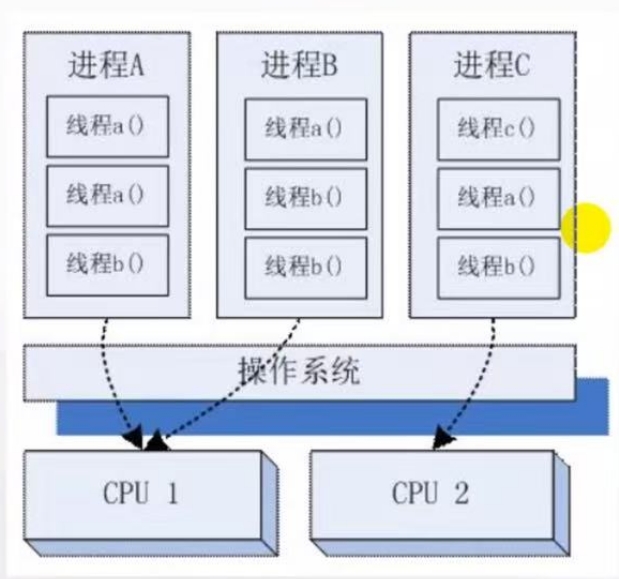
# 线程
进程有两个属性:拥有独立分配资源的单位,可独立调度和分配的基本单位。
每个进程都会有一个线程,是主线程。
线程是进程的一个实体,引入进程的原因:
- 进程在创建、撤销、切换中,系统需要较大的开销,故系统中的进程数不宜过多,切换频率不宜太高
- 分开传统进程的两个属性:进程作为独立分配资源的最小单位,线程是cpu调度的最小单位
# 线程基本上不拥有资源,只拥有一点运行中必不可少的资源(如程序计数器、寄存器、栈)
# 它与同属一个进程的其他线程共享进程的全部资源(如公共数据、全局便令、代码、文件等)
# 但不能共享线程独有的资源(如线程的栈指针等标识数据)
# 线程资源可共享,进程间资源不共享
# 计算密集型:计算量比较大时,用多进程
# IO密集型:如爬虫、文件读写,用多线程
# 分区存储管理
分区存储就是整存,将进程运行所需的内存整体分配给它,然后执行,有三种分区方式:
固定分区 # 静态分区法,分区固定,大小和作业所需大小不同,会产生内部碎片
可变分区 # 动态分区法,分区大小和作业所需大小相同,无内部碎片,但将整个主存切割成多块产生外部碎片
可重定位分区 # 可以解决碎片问题,移动所有已经分配好的区域,使其称为一个连续的区域
可变分区的算法:
首次适应法 # 按内存地址排序,查找第一个>=9k的空闲块
最佳适应法 # 按从小到大排序,查找第一个>=9k的空闲块
最差适应法 # 按从大到小排序,查找第一个>=9k的空闲块
循环首次适应法 # 按内存地址排序,查找第一个>=9k的空闲块,后面若还需分配则找下一个,不用每次从头找
# 分表存储管理
用于内存小于进程所需大小
- 页内地址就是偏移地址(页面大小)
- 逻辑地址=页号+页内地址
- 物理地址=页帧号+页内地址
- 页表:存储逻辑页号和物理页帧号的对应关系
优点 # 利用率高,碎片小(最后一页会有),分配及管理简单
缺点 # 增加了系统开销,可能产生抖动现象
 页面置换算法:
页面置换算法:
最优算法 # 理论上的算法,无法实现
先进显出算法 # 先调入内存的页先被淘汰,会产生抖动现象,分配的页数越多,效率越低
最近最少使用 # 过去最少使用的页面先被淘汰,这种方式效率高,且不会产生抖动现象
注意
淘汰原则:优先淘汰最近未访问的,而后淘汰最近未被修改的页面
快表: 是一块小容量的相联存储器,由快速存储器组成,按内容访问速度快,存放访问最频繁的页号
- 快表是将页表存于Cache中,慢表是将页表存于内存上
- 慢表需要访问两次内存才能取出页,而快表是访问一次Cache和一次内存,速度更快
# 设备管理
设备是计算机与外界交互的工具,负责计算机的输入/输出工作,常称为外部设备,简称外设或I/O系统
I/O设备管理软件使用分层管理,隐藏了I/O操作的实现细节,所有层次为:
用户进程、设备无关软件、设备驱动程序、终端处理程序、硬件
SPOOLING(外围设备联机操作)技术:
# 在外设上建立两个数据缓冲区,分别称为输入井和输出井,这样无论多少进程都会排队存储在缓冲区中,
# 打印机自动按顺序打印,实现了物理外设的共享,这就是物理设备的虚拟化
# 文件管理
- 文件是具有符号名的,在逻辑上具有完整意义的一组信息项的集合。
- 信息项是构成文件内容的基本单位,可以是一个字符,也可以是一个记录。
- 一个文件包括文件体和文件说明,文件体是文件真实的内容,文件说明是为了管理文件所用到的信息。
文件的逻辑结构可以分为两大类:
有结构的记录式文件、无结构的流式文件
文件的物理结构是指文件在物理存储设备上的存放方法,包括:
连续结构(顺序结构) # 将连续的文件信息依次存放在连续编号的物理块上
链接结构(串联结构) # 将连续的文件信息存放在不连续的物理块上,每个物理块有指向下个物理块的指针
索引结构 # 将连续的文件信息存放在不连续的物理块上,用索引表记录文件信息逻辑块号与物理块号的对应
多个物理块的索引表 # 索引表是文件创建时由系统自动建立的,和文件存放在同一文件卷上
索引文件结构:
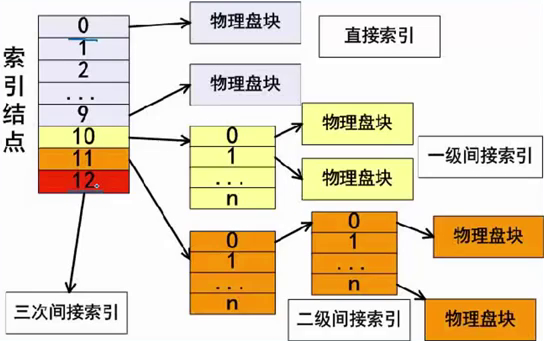
直接索引 # 0-9为直接索引,每个索引节点存放的是数据,若每个物理盘块为4KB,共存 4*10=40KB 的数据
一级索引 # 10存放的是物理盘块的地址,若每个地址占4B,共有1024个地址即1024个物理盘,1024*4=4096KB
二级索引 # 即11,直接盘存放一级地址,一级地址再存物理盘块地址,容量为 1024*1024*4KB数据
文件控制块包含以下三类信息:
基本信息类 # 如文件名、文件的物理地址、文件长度和文件块数等
存取控制信息类 # 文件的存取权限
使用信息类 # 文件的建立日期、最后一次修改日期、访问日期等
文件控制块的有序集合称为文件目录
相对路径 # 从当前路径开始的路径,前面不能加/
绝对路径 # 从根目录开始的路径
全文件名 # 绝对路径+文件名
文件的存取方法:读/写文件存储器上的一个物理块的方法,有顺序存取(磁带)和随机存取两种方法。
文件存储空间的管理:
空闲区表 # 每个表项对应一个空闲区,适用于连续文件结构,如第一个空闲块号18,空闲数5,则18-22为空闲
位示图 # 记录文件存储器的情况,每一位对应文件存储器上的一个物理块,取值0和1分别表示空闲和占用
空闲块链 # 每个空闲物理块中有指向下个空闲物理块的指针,所有空闲物理块构成一个链表,用于不连续文件
成组链接法 # 将空闲块分成若干组
# 中间件
中间件(Middleware)是应用软件与各种操作系统之间使用的标准化编程接口和协议,常见的分类如下:
通信处理(消息)中间件 # 保证系统能在不同平台之间通信,如:MQSeries
事务处理中间件 # 实现协调处理顺序,监视和调度,负载均衡等功能。如:Tuexdo
数据存取管理中间件 # 为不同种类的数据读写和解密提供统一接口
Web服务器中间件 # 提供Web程序执行的运行时容器,如:Tomcat、JBOSS
安全中间件 # 用中间件屏蔽操作系统的缺陷,提升安全等级
跨平台和架构的中间件 # 用于开发大型应用软件
专用平台中间件 # 为解决特定应用的开发设计问题提供的构件库
网络中间件 # 包括网关工具、接入工具等
# 软件构件
构件又称组件,是一个自包容、可复用的程序集,这个集合整体向外提供统一的访问接口,构件外部只能通过接口访问,不能直接操作构件的内部
优点是 # 易扩展、可重用、并行开发
缺点是 # 需要经验丰富的设计师
商用构件的标准规范有:
OMG的公共对象请求代理架构(CORBA)
# 是一个规范不是产品,分为3个层次:对象请求代理、公共对象服务和公共设施
# 采用IDL定义接口,易于转化为具体的实现语言
SUN的J2EE
# 定义了完整的基于Java开发面向企业分布的应用规范,其中EJB是J2EE的构建标准
# EJB中的构件称为Bean,分为会话Bean、实体Bean和消息驱动Bean
Microsoft的DNA2000 # 采用DCOM/COM/COM+作为构件标准
# 计算机语言 Computer Language
人与计算机之间交流的一种语言,主要由一套指令组成,这套指令包括:表达式、流程控制和集合三部分
计算机语言的分类:
机器语言 # 第一代计算机语言,由计算机能直接理解和执行的指令组成,指令格式由操作码和操作数组成
汇编语言 # 在机器语言的基础上采用英文字母和符号串来表达指令,是机器语言的符号化描述
# 每条语句由名字、操作符、操作数和注释4个字段组成
# 伪指令语句包括:数据定义伪指令DB、DW、DD,段定义伪指令SEGMENT,过程定义伪指令PROC等
# 编译后不产生机器代码
高级语言 # 比汇编语言更贴近于人类使用的语言,易于理解、记忆和使用,如:C、C++、Java、Python等
建模语言 # 主要指统一建模语言UML
# 统一建模语言 UML
是一种可视化的建模语言,而非程序设计语言,支持从需求分析开始的软件开发全过程,其结构包括:
构造块 # 有三种基本的构造块,分别是事物(thing)、关系(relationship)和图(diagram)
# 事物是UML的重要组成部分,关系把事物紧密联系在一起,图是多个相互关联的事物的集合
公共机制 # 达到特定目标的公共UML方法
规则 # 是构造块如何放在一起的规定
- 事物:UML中有4种事物(结构事物、行为事物、分组事物、注释事物)
结构事物 Structure thing
# 名词,模型的静态部分,包括:类Class、接口Interface、协作Collaboration
# 用例UseCase、主动类Active Class、构件Component、制品Artifact和节点Node
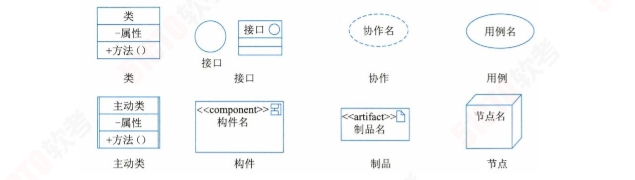
行为事物 Behavior thing
# 动词,模型的动态部分
# 包括:交互Interaction、状态机State Machine和活动Activity

分组事物 Grouping thing # 模型的组织部分,如包
注释事物 Annotation thing # 模型的解释部分

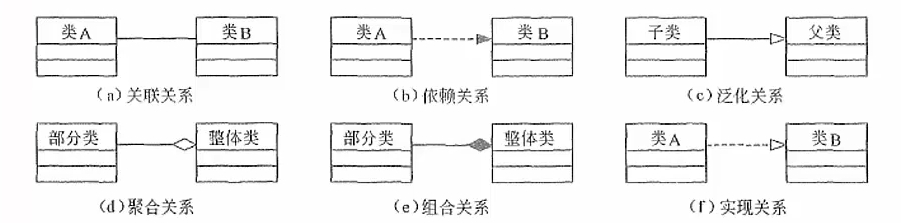
- 关系:UML中有4种关系(依赖、关联、泛化和实现)
依赖关系 # 其中一个事物发生变化会影响另一个事物,依赖关系是一种使用关系
关联关系 # 是一种拥有关系,提供了不同类对象之间的结构关系,它在一段时间内将多个类的实例连接在一起
# 关联关系有2个特例:聚合关系和组合关系,都表示类之间整体与部分的关系,区别在于
# 聚合关系:"部分"可能同时属于多个"整体","部分"与"整体"生命周期可以不同
# 组合关系:"部分"只属于一个"整体","部分"与"整体"的生命周期相同
# "部分"随着"整体"的创建而创建,随着"整体"的消亡而消亡
泛化关系 # 一般/特殊的关系,子类和父类之间的关系
实现关系 # 两种情况下会使用实现关系:接口和实现它们的类型或构件之间、用例和实现它们的协作之间
- 图:一组元素的图形表示,UML2.0提供了14种图:13种的不包含制品图
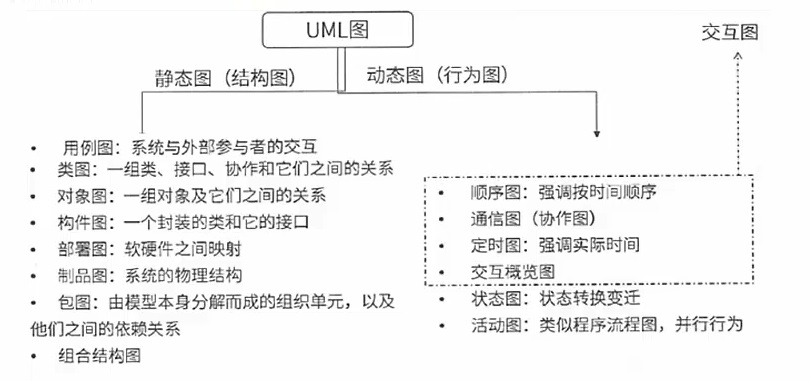
类图 # 静态图,系统的静态设计图,展现一组对象、接口、协作和他们之间的关系
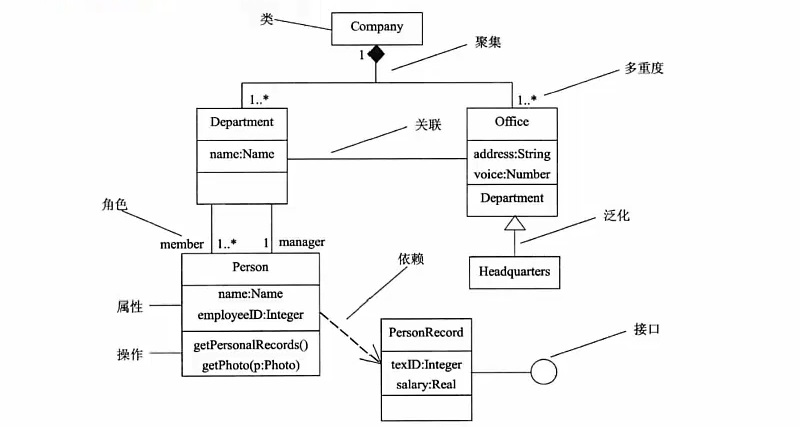
对象图 # 静态图,展现某一时刻一组具体对象及他们之间的关系,是类图的某一快照
# 在没有类图的前提下,对象图就是静态设计视图
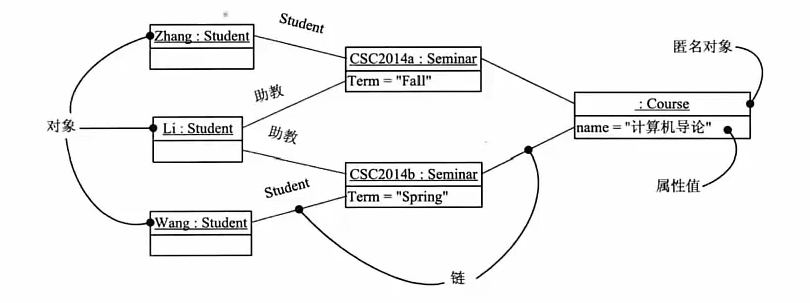
用例图 # 静态图,展现了一组用例、参与者以及他们之间的关系
# 用例图中参与者是人、硬件或者其他系统可以扮演的角色,参与到系统中的实体
# 用例是参与者完成的一系列操作(功能),用例之间的关系有扩展、包含、泛化(用例图特有的)
# 包含:include 例如执行登记信息前必须先执行用户登录,箭头 -->
# 扩展:extend 例如查询书籍信息时可以修改书籍信息也可以不修改,可做可不做,箭头 <--
# 泛化:指父子关系
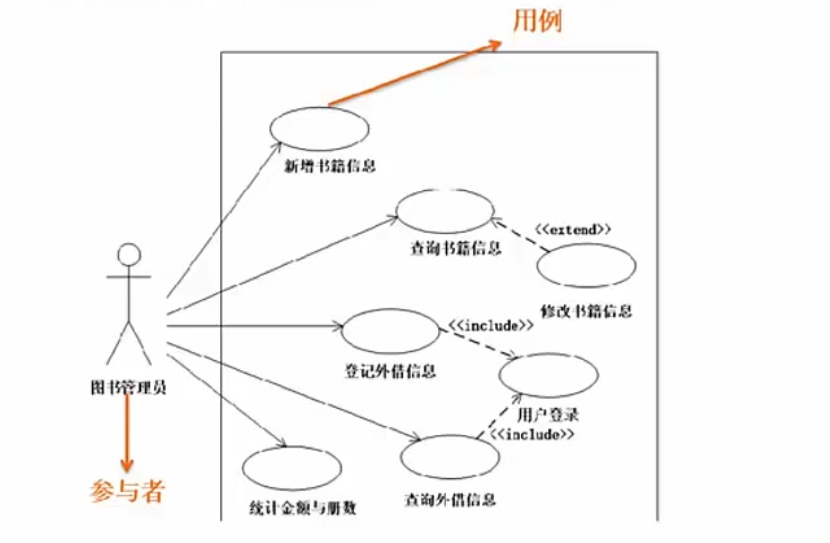
序列图 # 动态图,即顺序图,是场景的图形化表示,描述了以时间顺序组织的对象之间的交互活动
# 同步消息:阻塞等待返回消息,用实心三角箭头表示
# 异步消息:不引起调用者阻塞,也不等待返回消息,由空心箭头表示
# 返回消息:由从右到左的虚线箭头表示
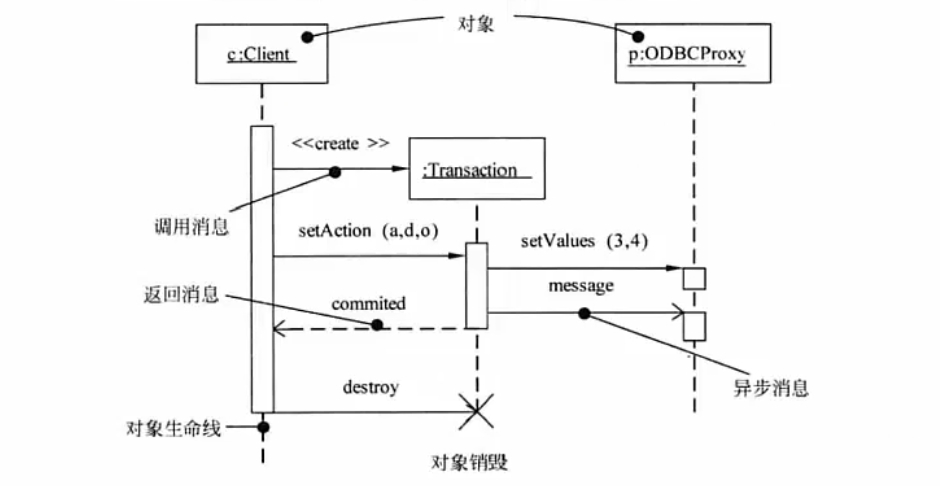
通信图 # 动态图,即协作图,强调参加交互的对象的组织,按序号进行传递
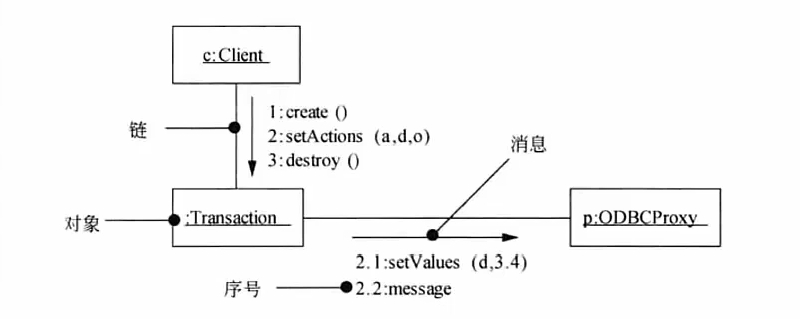
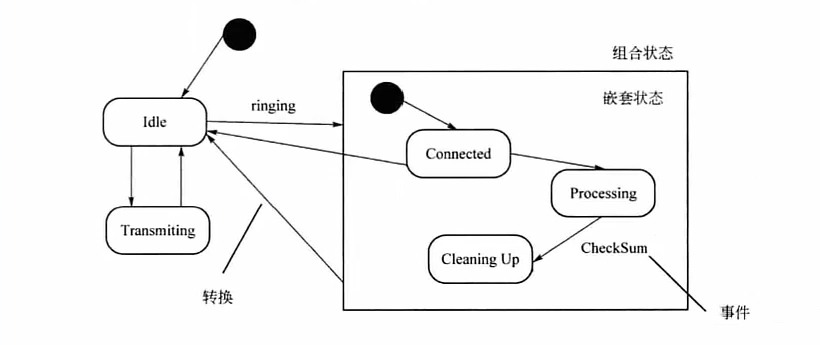
状态图 # 动态图,描述单个对象在多个用例中的行为,包括简单状态和组合状态
# 状态转换需要满足2个条件:1、通过事件触发器触发,2、事件触发后满足相应的监护条件
# 转换和状态是两个独立的概念
# 图中方框代表状态,箭头上的代表触发事件,实心圆是起点和终点
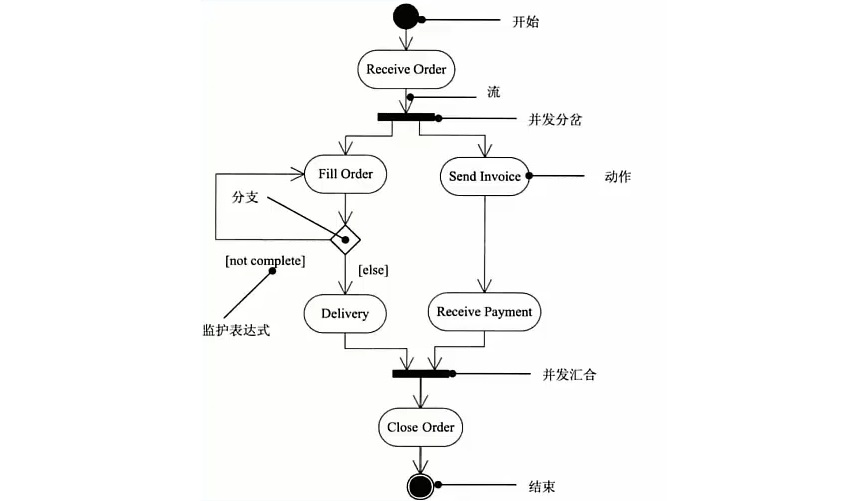
活动图 # 动态图,是一种特殊的状态图,展现了在系统内从一个活动到另一个活动的流程
# 活动的分岔和会和线是一条水平粗线,牢记下图中的并发分岔、并发汇合、监护表达式、分支、流
# 每个分岔的分支数代表了可同时运行的线程数
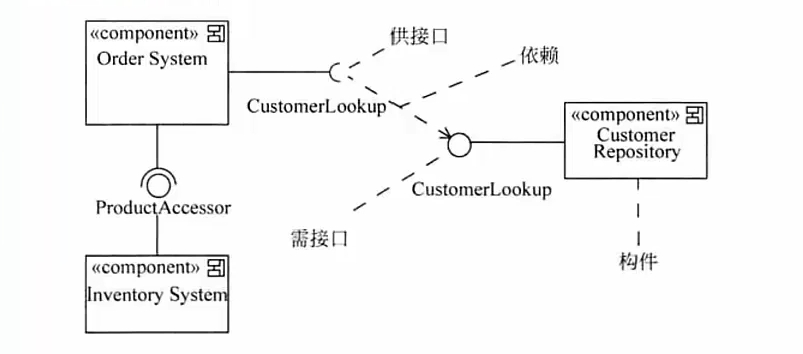
构件图(组件图,可复用的模块) # 静态图,展现了一组构件之间的组织和依赖
# 供接口:半圆,表示供应;需接口:圆,表示需要
部署图 # 静态图,系统的静态部署视图,展示物理模块的节点分布,和物理、硬件相关
# 与构件图相关,通常一个节点包含一个或多个构件
# 依赖关系类似于包依赖,因此部署组件之间的依赖是单向的类似于包含关系
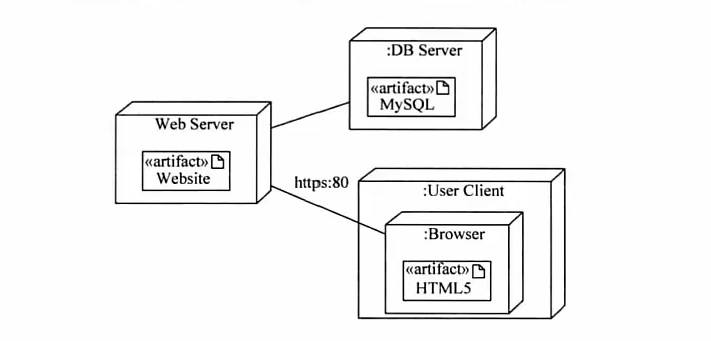
- UML中有5种视图
逻辑视图 # 即设计视图,表示设计模型中在架构方面具有重要意义的部分,即类、子系统、包和用例实现的子集
进程视图 # 可执行线程和进程作为活动类的建模,它是逻辑视图的一次执行实例,描述了并发和同步结构
实现视图 # 对组成基于系统的物理代码的文件和构件进行建模
部署视图 # 把构件部署到一组物理节点上,表示软件到硬件的映射和分部结构
用例视图 # 用例视图居于中心地位,是最基本的需求分析模型
- 形式化方法:形式化方法的开发过程贯穿软件工程的整个生命周期
根据描述方式分 # 模型描述和性质描述
根据表达能力分 # 模型方法、代数方法、进程代数方法、逻辑方法和网络模型方法
- 形式化语言:Z语言
# 具有"状态-操作"风格,借助模式来表达系统结构,建立在集合论和数理逻辑的基础上
# 是一个强类型系统,可以使用自然语言
# 多媒体技术
- 4个主要特征:多维化、集成性、交互性、实时性
- 多媒体系统的关键技术:
音频技术 # 音频数字化、语音处理、语音合成、语音识别
视频技术 # 视频数字化和视频编码技术
通信技术 # 包括数据传输信道技术和数据传输技术
数据压缩技术 # 包括即时压缩和非即时压缩、数据压缩、文件压缩、无损压缩、有损压缩
虚拟现实VR
# 是一种可以创建和体验虚拟世界的计算机仿真系统,采用计算机技术生成一个逼真的视觉、听觉、
# 触觉、味觉及嗅觉的感知系统与用户交互
增强现实AR
# 指把原本在现实世界一定时间和空间范围内很难体验到的实体信息
# 通过模拟仿真后,再叠加到现实世界中被人类感官所感知,从而达到超越现实的感官体验
VR/AR技术主要分为桌面式、分布式、沉浸jin式和增强式
# 数据库系统
# 基础知识
数据(Data)# 描述事物的符号记录,具有多种表现形式,如文字、图形、图像、声音和语言等
数据库(DB)# 是统一管理的、长期储存在计算机内的,有组织的相关数据的集合
数据库系统(DBS)# 采用了数据库技术,有组织的动态存储大量数据,方便多用户访问的计算机系统
数据库管理系统(DBMS):
# 数据库系统的核心软件,由一组相互关联的数据集合和一组访问这些数据的软件组成
# 分为三类:关系数据库系统、面向对象数据库系统、对象关系数据库系统
# 主要功能:数据定义、数据库操作、数据库运行管理、数据组织存储和管理、数据库的建立和维护
# 主要他点:数据结构化且统一管理,有较高的数据独立性、数据控制功能
# 数据控制功能包括:保证数据的安全性和完整性以及并发控制的能力、故障恢复能力
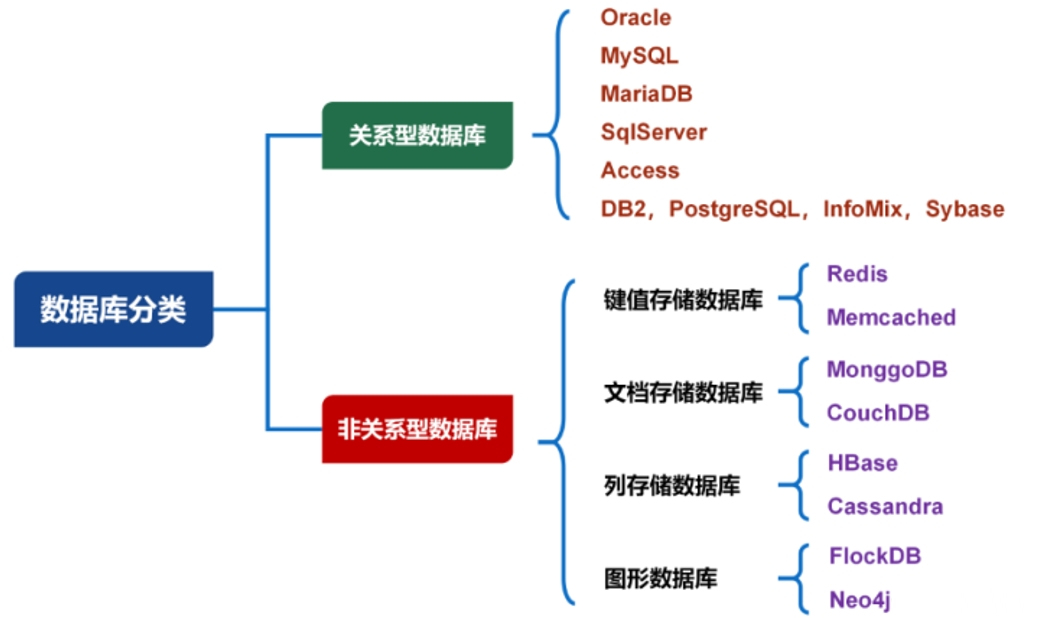
# 数据库分类
根据数据库存储体系的分类,可以分为:
关系型数据库 # 把复杂的数据结构归结为简单的二元关系,对数据的操作几乎全部建立在一个或多个关系表格上
键值数据库 # 分关系型数据库,使用简单的兼职方法来存储数据,其中键作为唯一标识符
列存储数据库 # 相对于传统关系型数据库行式存储来说的,两者的区别是表中数据存储形式的差异
文档数据库 # 存放的文档相当于键值数据库所存放的“值”,可视为其值可查的键值数据库,XML、JSON等格式
图数据库 # 存储通过图建模的数据,如社交网络、生物信息网络、交通网络,常见产品:Neo4J、InfoGrid
搜索引擎数据库 # 由搜索引擎爬取大量数据,并以特定的格式进行存储
 文件系统的优缺点:
文件系统的优缺点:
优点 # 数据可以长期保留,数据不属于某个特定应用,文件组织形式多样性且文件之间没有联系相互独立
缺点 # 数据冗余(Data Redundancy),数据不一致(Data Inconsistency),数据孤立(Data Isolation)
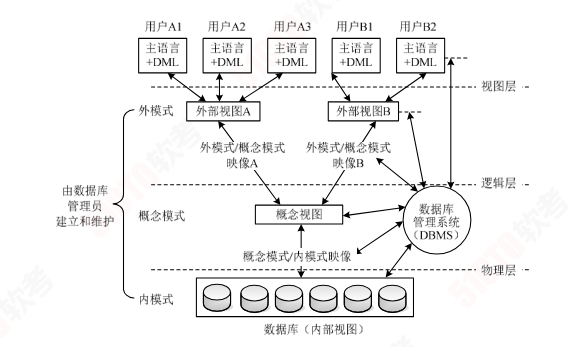
# 三级模式两级映像
开发人员需要通过视图层、逻辑层和物理层三个层次上的抽象来降低系统复杂度,简化用户与系统的交互
内模式 # 管理如何存储物理数据,对应具体的物理存储文件
模式 # 又称概念模式,就是我们通常使用的表
外模式 # 对应数据中的视图这个级别,将表处理后再提供给用户
外模式-模式映像 # 表和视图间的映射,若表中的数据发生改变,只要修改此映射,无需修改应用程序
模式-内模式映像 # 表和数据的物理存储间的映射,若修改了数据的存储方式,只要修改此映射无需修改应用
注意
- 外模式-模式映像保证了数据的逻辑独立性,模式-内模式映像保证了数据的物理独立性
- 如果对一个表创建局促索引,那么改变的是数据库的内模式
# 数据库设计
需求分析
# 分析存储数据的要求,产出物有数据流图、数据字典、需求说明书
# 获得用户对系统的三个要求:信息要求、处理要求、系统要求
概念结构设计
# 就是设计E-R图。工作步骤:选择局部应用,逐一设计分E-R图、E-R图合并
# 分E-R图合并时存在的冲突:属性冲突、命名冲突、结构冲突
逻辑结构设计
# 将E-R图转换成关系模式
# 工作步骤:确定数据模型、将E-R图转成指定的数据模型、确定完整性约束和确定用户视图
物理设计 # 步骤包括确定数据分布、存储结构和访问方式
# 数据分布:集中式管理还是分布式管理
# 存储结构:数据文件中记录之间的物理结构,包括:顺序存储、哈希存储、堆存储、B+树存储
# 为提高数据的访问速度,一般采用索引技术
# 访问方式:数据的访问方式是由其存储结构决定的,数据库物理结构组成有:
# 存储记录结构的设计、存储记录布局、存取方法的设计
数据库实施 # 建立实际的数据库结构,数据加载,数据库试运行和评价
数据库运行和维护 # 数据库性能的检测和改善、数据库的备份和故障恢复、数据库重组和重构
# 数据模型
设计数据库的方法:
关系模型 # 是二维表的形式表示实体-联系模型,是由开发人员设计的
概念模型 # 是从用户角度进行建模的,是现实世界到信息世界的第一抽象,是真正的实体-联系模型
网状模型 # 表示实体及实体间的联系,形成一张网
面向对象模型 # 采用面向对象的方法,以对象位单位,每个对象包括属性和方法,具有类和继承等特点
数据模型的三要素:
数据结构 # 研究对象的类型集合
数据操作 # 对数据库中对象的增删改查操作
数据的约束条件 # 一组完整性规则的集合,比如年龄小于18岁
数据的约束条件包括:
实体完整性约束 # 即主键约束,主键不能为空也不能重复
参照完整性约束 # 即外键约束,外键必须是其他表中已经存在的主键的值,可以为空
用户自定义完整性约束 # 自定义表达式约束,如年龄必须在0-150之间
# E-R模型
- 使用椭圆表示属性(一般没有),长方形表示(强)实体,菱形表示联系,联系的两端要写联系类型
- 长方形加两个竖线是弱实体,弱实体依赖强实体而存在,依赖关系通过小圆圈表示
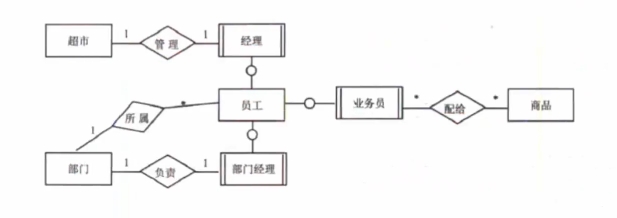
E-R模型转换为关系模型:每个实体都对应一个关系模型,联系分为三种:
1:1 联系中 # 联系可以放到任意两端的实体中,作为一个属性,也可以做为一个单独的关系模型
1:N 联系中 # 可以在N端加入1端实体的主键,也可以做为一个单独的关系模型
M:N 联系中 # 联系必须做为一个单独的关系模型,其主键就是M和N端的联合主键
# 关系代数
表和表之间的逻辑运算
并(∪) # 两张表中所有记录数合并,相同记录只显示一次
交(∩) # 两张表中相同的记录
差(-) # S1-S2,S1表中有而S2表中没有的记录
笛卡尔积(×) # S1*S2,产生的结果包括S1和S2的所有属性,并且S1中每条记录依次和S2中所有记录组合
# 最终属性列为S1+S2的属性列,记录数为S1*S2的记录数
投影(π) # 按条件选择某列,列也可以用数字表示,π(Sname)或者π2
选择(σ) # 按条件选择某条记录,σ1=No003或者σ2=Candy
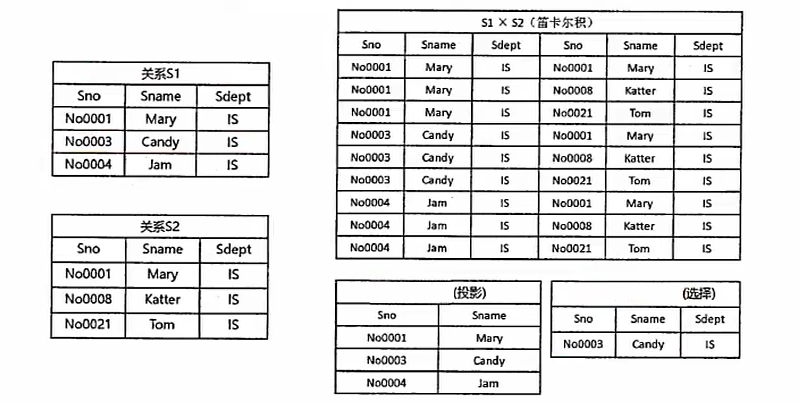
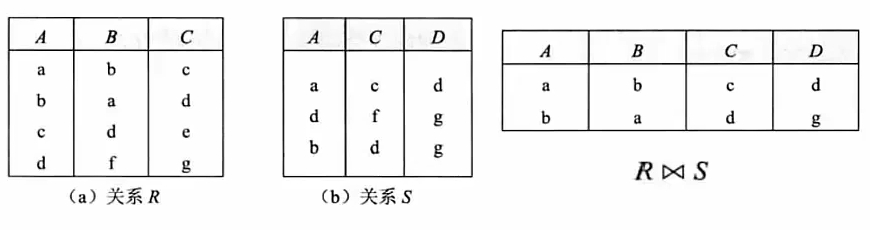
自然连接(∞) # 显示全部的属性列,但是相同属性列只显示一次,显示两个表中属性相同且值相同的记录
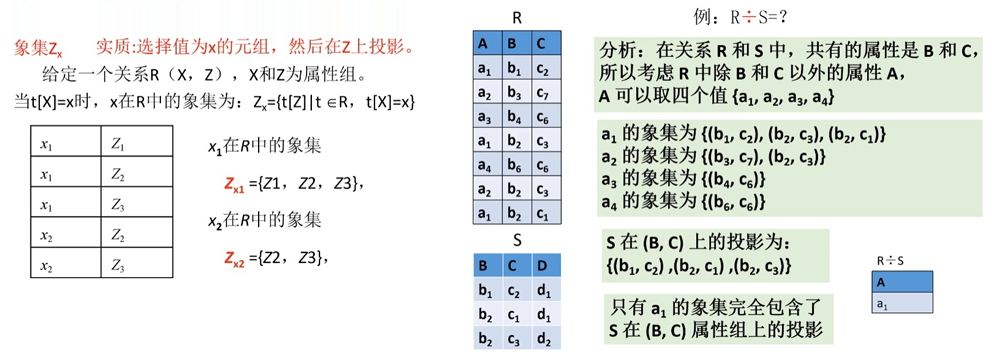
除(÷) # 1、找不同 2、求象集 3、求投影 4、求包含
# 外连接运算
左外连接(⋊)
# 取出左侧关系中所有与右侧关系中任一元组都不匹配的元组,用空值null填充所有来自右侧关系的属性
# 构成新的元组,将其加入自然连接的结果中
右外连接(⋉)
# 取出右侧关系中所有与左侧关系中任一元组都不匹配的元组,用空值null填充所有来自左侧关系的属性
# 构成新的元组,将其加入自然连接的结果中
完全外连接(⋈)
# 完成左外连接和右外连接的操作
# 即填充左侧关系中所有与右侧关系中任一元组都不匹配的元组
# 并填充右侧关系中所有与左侧关系中任一元组都不匹配的元组
# 将产生的新元组加入到自然连接的结果中
# 函数依赖
非平凡的函数依赖 # 如果 X -> Y 且X不包含Y(Y ⊈ X),则称 X -> Y是非平凡的函数依赖
平凡的函数依赖 # 如果 X -> Y 且X包含Y(Y ⊆ X),则称 X -> Y是平凡的函数依赖
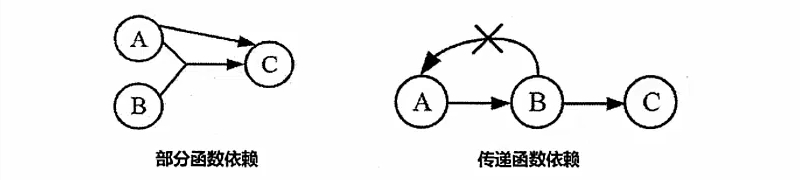
部分函数依赖 # A可以确定C,(A,B)也可以确定C,(A,B)中的一部分(即A)可以确定C,称为部分函数依赖
传递函数依赖 # A和B不等价时,A->B,B->C,则A->C,是传递函数依赖,A和B等价时不存在传递
函数依赖的公理系统(Armstrong公理系统):从已知的一些函数依赖可以推导出另外一些函数依赖
设关系模式R<U,F>,其中U为属性集,F是关系模式R的一组函数依赖,那么有如下推理规则:
自反律 # 若Y⊆X⊆U,则X->Y为F所逻辑蕴含
增广律 # 若X->Y为F所逻辑蕴含,且Z⊆U,则XZ->YZ为F所逻辑蕴含
传递律 # 若X->Y和Y->Z为F所逻辑蕴含,则X->Z为F所逻辑蕴含
根据上面三条推理规则,又可推出下面三条推理规则:
合并规则 # 若X->Y,X->Z,则X->YZ为F所逻辑蕴含
伪传递规则 # X->Y,WY->Z,则XW->Z为F所逻辑蕴含
分解规则 # 若X->Y,Z⊆Y,则X->Z为F所逻辑蕴含
# 键与约束
域 # 每个属性的取值范围对应一个值的集合
目或度 # 一个关系中属性的个数
超键(超码)# 能唯一标识此表的属性组合,例如:学号、学号+姓名、学号+姓名+年龄
候选键(候选码)# 超键中去掉冗余的属性,剩下的就是候选键
全键(全码)# 关系模型中所有的候选码
主键(主码)# 任选一个候选键,即为主键
外键(外码)# 其他表中的主键
主属性 # 候选键内的属性为主属性,其他属性为非主属性,例如:学号、身份证号
# 范式
第一范式1NF # 关系中每个分量必须是一个不可分割的数据项,就是不允许有小表存在
第二范式2NF # 如果关系R属于1NF,且每个非主属性不会依赖符合主键中的某一列,则R属于2NF
# 消除了非主属性对主属性的部分函数依赖,部分函数依赖只存在于有多个主属性中
第三范式3NF # 在满足1NF的基础上,表中不存在非主属性对主属性的传递依赖
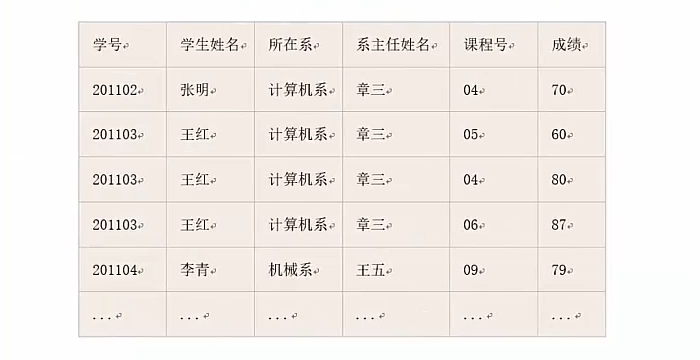
# 实例:学号->学生姓名,学号->系号,系号->系主任姓名,学号->课程号,(学号、课程号)->成绩
# 先找出主键:学号+课程号 ——> 没有在依赖集右边出现过的,并且可以推出其它属性,否则就增加此属性
# 将学生表分解为:
# 学生(学号、学生姓名、系编号、系名、系主任)
# 选课(学号、课程号、成绩)
# 每张表均属于2NF
# 将学生表进一步分解为:
# 学生(学号、学生姓名、系编号)
# 系(系编号、系名、系主任)
# 选课(学号、课程号、成绩)
# 每张表均属于3NF
BC范式BCNF # 在第三范式的基础上进一步消除主属性对对主属性的部分函数依赖和传递依赖
# 通俗来说就是在每一种情况下,每个依赖的左边都必然包含候选键
# 主要针对多个候选键
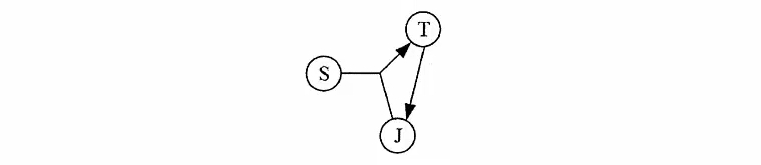
# 上图中候选键有两种情况:组合键(S,T)或者(S,J),依赖集为{SJ->T,T->J}可知,STJ三个属性都是主属性
# 因此其达到了3NF(无非主属性)
# 然而,第二种情况,即(S,J)为候选键的时候,对于依赖T->J,T在这种情况不是候选键
# 即T-J的决定因素不包含任何候选码,因此上图不是BCNF
# 要使上图关系模式转换为BCNF,只需要将依赖T->J变为TS->J这样左边决定因素就包含了候选键之一S

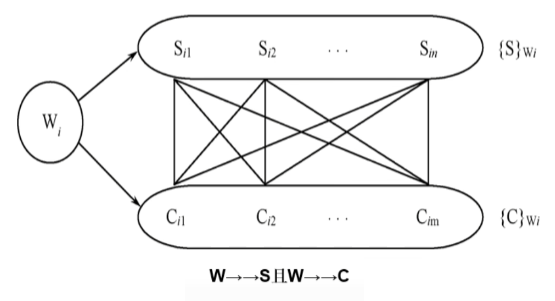
第四范式4NF # 每个依赖的左边都必然包含候选键,且属性之间不允许有非平凡且非函数依赖的多值依赖
# 允许有非平凡且函数依赖的多值依赖
# 多值依赖:一个X可以决定多个Y,X->->Y
# 下图中,如果没有W->->C,则属于平凡的函数依赖,整体属于非平凡的非函数依赖
# 可以把WSC分解成WS(W,S),WC(W,C),则WS∈4NF,WC∈4NF
注意
如果只考虑函数依赖,关系模式最高的规范化程度时BCNF
如果考虑多值依赖,关系模式最高的规范化程度时4NF
# 模式分解
范式之间的转换一般都是通过拆分属性,即模式分解,将具有部分函数依赖和传递依赖的属性分离出来,分为两种:
保持函数依赖分解 # 分解出来的多个关系模式,是否能还原原来的依赖集,注意要消除冗余依赖
# 设原关系模式U(A, B, C),依赖集F(A->B, B->C, A->C),将其分解为两个关系模式R1(A, B)和R2(B, C)
# 此时R1中保持依赖A->B,R2保持依赖B->C,说明分解后的R1和R2是保持函数依赖的分解
# 因为A->C是一个冗余依赖,可以由前2个依赖传递得到,因此不需要管
简单方法
看函数每个依赖的左右两边属性是否都在同一个分解的模式中
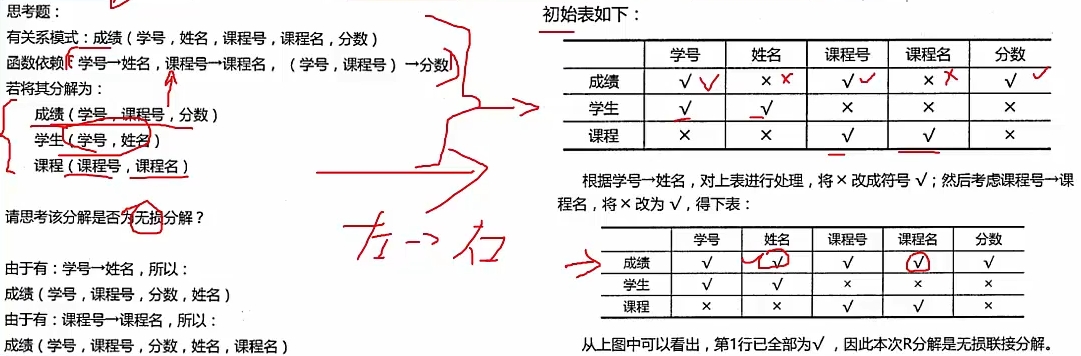
无损分解 # 分解出来的多个关系模式,能还原原来的属性,就是无损分解,不能还原就是有损
# 两个关系模式,可以通过以下定理判断:
# 如果R分解为P={R1, R2},F为R所满足的函数依赖集合,分解P具有无损连接性的 充分必要条件是:
# R1 ∩ R2 -> (R1 - R2) 或者 R1 ∩ R2 -> (R2 - R1)
# 多个关系模式,可以通过表格法求解,只需要其中一行全部为 √
# 并发控制
事务的四种特性
原子性(Atomicity) # 要么全做,要么全不做
一致性(Consistency) # 事务发生后的数据是一致的,银行转账,不会存在A转出,B没收到的情况
隔离性(Isolation) # 不同事务间是隔离的,互不干涉
持续性(Durability) # 事务操作的结果是持续性的,保持不变的
相关的SQL语句
# begin transaction、commit、roll back
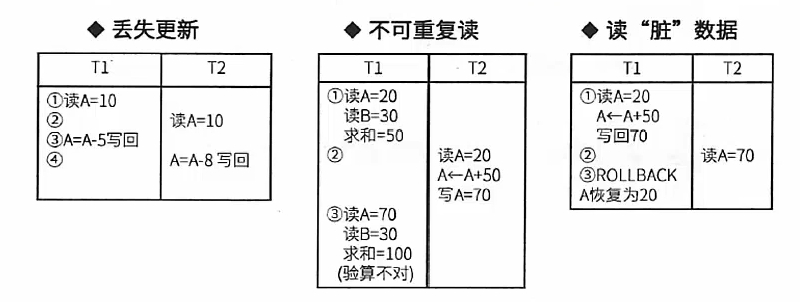
并发控制就是控制不同的事务并发执行,提高系统效率,但存在三个问题:
丢失更新
# 事务1和事务2都对A进行修改并写回,事务2写回的数据会覆盖事务1写回的数据,此时事务1丢失了对A的更新
不可重复读 # 一个事务重复读A两次,发现数据A不一致
读脏数据 # 事务2读取到了事务1回滚的数据
# 封锁协议
排他锁(X锁、写锁) # 只允许修改和读取,并且其他事务不能再加任何类型的锁
共享锁(S锁、读锁) # 只允许读取,不能修改,其他事务只能再加共享锁
三级封锁协议,解决并发控制的三个问题:
一级封锁协议 # 事务在修改数据前必须先对其加X锁,直到事务结束才释放,可解决丢失更新的问题
二级封锁协议 # 在读数据前必须先对其加S锁,读完后释放S锁,可解决丢失更新、读脏数据的问题
三级封锁协议 # 可解决丢失更新、读脏数据、数据重复读的问题
# 数据库的备份
静态转储 # 即冷备份,在转储期间不允许对数据库进行任何操作
# 优点是速度快,容易归档,缺点是只能提供到某一时间点上的恢复,不能按表或用户恢复
动态转储 # 即热备份,在转储期间允许对数据库进行操作,因此转储和用户事务可以并发执行
# 优点是金额达到秒级恢复,缺点是不能出错,否则后果严重,所得结果几乎全部无效
完全备份 # 备份所有数据
差量备份 # 津备份上一次完全备份之后变化的数据
增量备份 # 备份上一次备份之后变化的数据
# 周一完全备份,周二差量备份,周三增量备份,周四差量备份,周五增量备份
# 周四备份的周一的,周五备份周四的
日志文件 # 在事务处理过程中,DBMS把事务开始、事务结束以及对数据库的每一次操作都写入日志文件
# 一旦发生故障,DBMS的恢复子系统利用日志文件撤销事务对数据库的改变,回退到事务的初始状态
数据库的4类故障:事务故障、系统故障、介质故障、计算机病毒
# 事务故障的恢复有两个操作:撤销事务(UNDO)和重做事务(REDO)
# 介质故障的恢复由系统管理员装入数据库的副本和日志文件副本,再由系统执行撤销和重做
# 数据仓库
数据仓库是一个面向主题的、集成的、相对稳定非易失、且随时间变化的数据集合,用于支持管理决策
面向主题 # 数据按主题组织
集成的 # 消除了源数据中的不一致性,提供整个企业的一致性全局信息
相对稳定非易失 # 主要进行查询操作,只有少量的修改和删除操作
随时间变化 # 记录了企业从过区某一时刻到当前各个阶段的信息,可对发展历程和未来趋势做定量分析和预测
数据仓库的结构包含四个层次:
数据源 # 各种异构的数据库,是数据仓库系统的基础,是整个系统的数据源泉
数据的存储与管理 # 是整个仓库系统的核心,将异构的数据转换为同源的数据存储到数据仓库
OLAP(联机分析处理)服务器 # 对要分析的数据进行有效集成,并进行挖掘分析
前端工具 # 通过各种报表工具、查询工具、分析工具等进行数据展示
商业智能:BI系统主要包括商业数据预处理、建立数据仓库、数据分析和数据展现四个主要阶段
# 一般认为数据仓库、联机分析处理(OLAP)和数据挖掘是商业智能的三大组成部分
OLTP和OLAP的区别
# OLTP即联机事务处理,是关系数据库的基础
# OLAP即联机分析处理,是数据仓库的核心部分A
数据挖掘
# 数据挖掘一般是指从大量的数 据中通过算法搜索隐藏于其中信息的过程
# 通过分析每个数据,从大量数据中寻找其规律的技术,主要有数据准备、规律寻找和规律表示3个步骤
# 挖掘的信息也是出乎医疗,就越有价值
# 应用程序与数据库的交互方式
库函数级别访问接口 # 将结构化的查询语言(SQL)和高级语言相结合,强依赖于特定的数据库,难度大效率低
嵌入式SQL访问接口 # Embeded SQL 是一种将SQL直接写入高级语言源代码中的方法
通用数据接口标准 # 开放数据库连接(ODBC)是为解决异构数据库间的数据共享产生的,不依赖任何DBMS系统
# 能以统一的方式处理所有关系数据库,常见数据库接口包括:
# 数据库访问对象DAO、远程数据库对象RDO、ActiveX数据对象ADO、Java数据库连接JDBC
ORM访问接口 # 对象关系映射(ORM)用于实现不同类型系统之间的数据转换,例:Hibernate、Mybatis、JPA
# NoSQL数据库
泛指非关系型数据库,区别于关系数据库,不保证关系数据的ACID特性
一般适用于数据模型比较简单、灵活性强、对数据库性能要求较高、对数据一致性要求不高的系统
可分为:
列式存储数据库 # 用来应对分布式存储的海量数据,键仍然存在,特点是指向多个列。例:HBate、Riak
键值存储数据库 # 优势是简单、易部署,但是只对部分值插叙或更新时效率地下。例:Redis、Oracle BDB
文档型数据库 # 在处理网页等复杂数据时,比键值对数据库查询效率更高。例:CouchDB、MongoDB
图数据库 # 存储通过图建模的数据,如社交网络、生物信息网络、交通网络,常见产品:Neo4J、InfoGrid
整体框架分为4层,由下至上为:
数据持久层 # 定义了数据的存储形式,包括基于内存、硬盘、内存和硬盘接口、定制可插拔4种形式
数据分布层 # 定义了数据是如何分布的,主要有3种形式:
# 一是CAP支持,可用于水平扩展
# 二是多数据中心支持,保证在横跨多数据中心时也能平稳运行
# 三是动态部署支持,可以在运行着的集群中动态的添加或删除节点
数据逻辑层 # 定义了数据的逻辑表现形式
数据接口层 # 为上层应用提供数据调用接口,5种方式:Rest、Thrift、Map/Reduce、Get/Put、特定语言API
# 分布式数据库
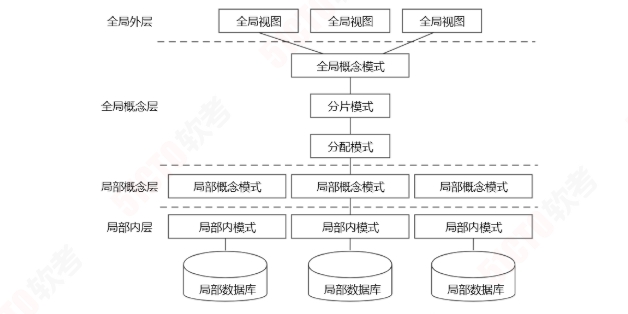
局部数据库位于不同的物理位置,使用全局的DBMS将所有局部数据库联网管理,就是分布式数据库
体系结构:
全局视图(全局外模式)# 是全局的用户视图、是全局概念模式的子集,该层直接与用户或应用程序交互
全局概念模式 # 定义分布式数据库中数据的整体逻辑结构,可采用传统集中式数据库的方法进行定义
分片模式 # 将一个关系模式分解为几个数据片
分配模式 # 定义数据片段的存放节点
局部概念模式 # 局部数据库的概念模式
局部内模式 # 局部数据库的内模式
这种体系结构适用于同构型分布式数据库系统,也适用于异构型分布式数据库系统
分片模式:
水平分片 # 将表中水平的记录存放在不同的地方
垂直分片 # 将表中垂直的列存放在不同的地方
分布透明性:
分片透明性 # 用户或应用程序不需要知道访问的表是如何分块存储的
位置透明性 # 用户或应用程序不需要知道数据存储的位置
逻辑透明性 # 用户或应用程序不需要知道使用的是哪种数据模型
复制透明性 # 用户或应用程序不需要知道复制的数据从何而来
分布式数据库的特点:
共享性 # 不同节点的数据共享
自治性 # 每个节点对本地数据都能独立管理
可用性 # 某地故障时,可使用其他地方的而不至于整个系统瘫痪
分布性 # 数据分布在不同场地上存储
分布式数据库两阶段提交
# 二阶段提交(Two-phaseCommit)是指,在计算机网络以及数据库领域内,
# 为了使基于分布式系统架构下的所有节点在进行事务提交时保持一致性而设计的一种算法(Algorithm)。
# 通常,二阶段提交也被称为是一种协议(Protocol))。
# 在分布式系统中,每个节点虽然可以知晓自己操作是成功或失败,却无法知道其他节点的操作的成功或失败。
# 当一个事务跨越多个节点时,为了保持事务的 ACID 特性需要引入协调者来统一掌控所有节点的操作结果,
# 并最终指示这些节点是否要把操作结果进行真正的提交。
# 因此,二阶段提交的算法思路可以概括为:
# 参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报决定各参与者是否要提交还是中止。
# 所谓的两个阶段是指:第一阶段:准备阶段(表决阶段)和第二阶段:提交阶段(执行阶段)。
# 准备阶段:事务协调者给每个参与者发送Prepare消息,每个参与者要么直接返回失败,要么在本地执行事务,
# 写本地的redo和undo日志,但不提交,到达一种“万事俱备,只欠东风”的状态。
# 提交阶段:如果协调者收到了参与者的失败消息,直接给每个参与者发送回滚消息;否则发送提交消息;
# 参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中使用的锁资源。
# 数据库优化技术
- 集中式数据库性能优化最常见的方法就是反规范化,数据库设计者希望牺牲部分规范化来提高性能
好处 # 降低连接操作的需求、降低外码和索引数目、减少表的数目、提高查询效率
坏处 # 数据重复存储,浪费磁盘空间;可能出现数据完整性问题;增加了数据维护复杂度,降低修改速度
# 具体方法:
增加冗余列 # 在多个表中保留相同列
增加派生列 # 在表中增加由本表或其他表中数据计算生成的列
重新组表 # 把经常需要查看的两个表合并成一个表来减少连接提高性能
水平分割表 # 针对表数据量大、表中数据相对独立的,把数据放到多个独立的表中
垂直分割表 # 将主键与部分列放到一个表,主键与另一部分列放到另一个表,查询时减少I/O次数
- 分布式数据库的性能优化可以采用主从复制、读写分离、分库分表
主从复制:
# 建立一个和主数据库完全一样的数据库环境,称为从数据库,好处是:
做数据的热备 # 主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失
架构的扩展 # 业务量越大I/O访问频率越高,多库存储可以降低磁盘I/O访问频率,提高单个机器的I/O性能
读写分离 # 主从数据库同步的模式有全同步、半同步、异步三种方式,主从数据库间通过binlog进行数据同步
binlog日志有3种模式:
基于SQL语句的复制 # 每更新一条SQL语句都会记录在binlog中,从而同步到从库的relaylog中
基于行的复制 # 不记录SQL语句,只记录更新前和更新后的数据,可以保证主从数据绝对相同
混合复制 # 以上两种模式的混合
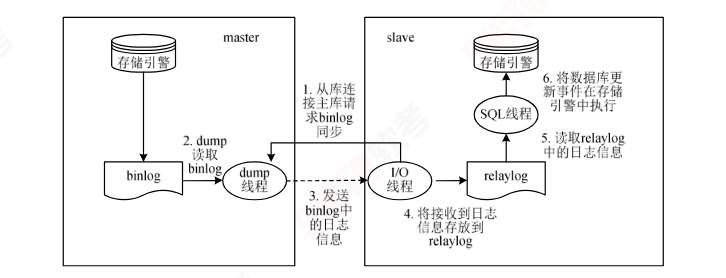
读写分离:
# 设置不同的主、从数据库分别负责不同的操作,让主数据库负责写数据,让从数据库负责读数据
分表(分片):
# 在单个实例内部,将一张大表分成若干小表,可以提升数据库并发及I/O的性能。分为:垂直切片、水平切片
分库:
# 将不同分类的数据表,分别存放到不同实例上,有利于差异化管理
# 分布式缓存技术 Redis
Redis作为缓存组件时,基于内存的读写特性。比基于磁盘的性能高很多,适合缓存高频热点的数据
数据类型包括:
string类型 # 基本类型,可用于计数
hash类型 # 代替string类型,节省空间,描述用户信息比较方便
set类型 # 无序集合,每个值不能重复
list类型 # 双向链表结构,可以模拟栈、队列等
zset类型 # 有序集合,每个元素有一个分数
由于一份数据存放在多个位置,所以需要考虑数据一致性的问题。读写数据的基本步骤为:
读数据 # 根据key读缓存,读取成功则直接返回,若key不在缓存中,则根据key读数据库,读取成功后写缓存
写数据 # 根据key值写数据库,成功后跟新缓存key值
对于设置了过期时间的数据有两种方式淘汰这些数据
定期删除 # 每隔一段时间会随机抽取一些设置了过期时间的key进行删除,无法全部删除
惰性删除 # 查询key的时候会检测key是否到期,如果到期则删除,也无法全部删除
数据持久化有两种方式:
RDB # 默认方式,不需要配置,在一定的时间间隔中,检测key的变化,然后持久化数据
AOF # 日志记录的方式,可以记录每一条命令的操作
| 类型 | RDB | AOF |
|---|---|---|
| 恢复方式 | 将快照文件直接读到内存 | 每次操作后持久化数据,恢复时需要从头开始回放 |
| 磁盘刷新频率 | 低 | 高 |
| 文件大小 | 小 | 大 |
| 数据恢复效率 | 高 | 低 |
| 数据安全 | 低 | 高 |
缓存异常问题及解决方案
缓存穿透 # 大量数据访问了没有缓存的key,直接访问数据库,造成数据库压力增大
问题原因1 # 恶意攻击
解决办法 # 针对比较少的请求来源IP,主动限制其访问次数,或者拉入黑名单
# 应用程序来检查key的合法性,提前拒绝不合法的请求
# 使用布隆过滤器
问题原因2 # 新业务刚上线,此时Redis是空的
解决办法 # 预热Redis,将大量访问的数据预先加载到Redis
# 在最前端进行流量控制,让Redis逐步加载
# 在数据库里也没有的key,需要在Redis中使其值设置为null或空
缓存雪崩 # 大量数据访问到缓存中的key,但是key到期了,直接访问数据库,造成数据库压力增大
问题原因1 # Redis故障
解决办法 # 使用主从复制提高可用性,使用cluster集群方案降低故障时影响的范围
# 如果出现故障,则可以采取服务降级、熔断、限流等措施
问题原因2 # 大量的key使用了相同的过期时间
解决办法 # 过期时间上设置随机值,设置不同的过期时间
缓存击穿 # 少量热点的key缓存时间失效了,直接访问数据库,造成数据库压力增大
解决办法 # 将key过期时间设置的长一些
# 使用分布式锁,只允许一个请求去访问数据库,取出key放到redis,其他请求必须等待
Redis可以采用集群的方式部署
# 主从复制集群、哨兵集群、Cluster集群
# 集群的切片方式主要分为:客户端分片、代理分片、服务器端分片三种方式
# 嵌入式技术
# 嵌入式微处理器分类
嵌入式微处理器的字长宽度,可分为4位、8位、16位、32位和64位,一般把16位及以下的称为嵌入式微控制器,32位及以上的称为嵌入式微处理器
根据用途分类:
嵌入式微控制器MCU
# 典型代表是单片机,内部集成ROM/RAM、总线、I/O等各种必要功能和外设
# 特点是单片化、体积小、成本低、可靠性高,是嵌入式系统工业的主流
嵌入式微处理器MPU
# 由通用计算机中的CPU演变而来,特征是具有32位以上的处理器
# 与计算机处理器不同的是只保留和嵌入式紧密相关的功能硬件,去除冗余功能,常见的有ARM/MIPS/POWER PC等
嵌入式数字信号处理器DSP
# 专门用于信号处理,其在系统结构和指令算法方面进行了特殊设计,具有很高的编译效率和指令执行速度
# 采用哈佛结构,流水线处理,处理速度比最快的CPU还快10-50倍,在数字滤波、波普分析等仪器上大规模应用
# 适用于运算量较大的智能系统
嵌入式片上系统SOC
# 是追求产品系统最大包容的集成器件,特点是实现了软硬件的无缝结合,直接在处理器内嵌入操作系统的代码
# 是一个专用目标的集成电路,其中包含完整系统并有嵌入软件的全部内容
# 多核处理器
- 指多个微处理器内核,是将两个或更多的微处理器封装在一起,集成在一个电路中
- 多核处理器是单枚芯片,能直接插入单一的处理器插槽中
- 多核与多CPU(多个芯片)相比,很好的降低了计算机系统的功耗和体积
- 在多核技术中,由操作系统软件进行调度,多进程,多线程并发都可以
2个或多个内核工作协调实现方式:
对称多处理技术SMP # 将2颗完全一样的处理器封装在一个芯片中,达到或接近双倍的处理性能,节省运算资源
非对称处理技术AMP # 2个处理器内核不同,各自处理和执行特定功能,在软件的协调下分担不同的计算任务
多核CPU的调度算法:多核CPU环境下进程的调度算法一般有全局队列调度和局部队列调度两种
全局队列调度
# 操作系统维护一个全局的任务等待队列
# 当系统中有CPU空闲时,操作系统就从全局任务等待队列中选取就绪任务开始执行
# 优点是CPU核心利用率高
局部队列调度
# 操作系统为每个CPU内核维护一个局部的任务等待队列
# 当系统中有CPU空闲时,就从该核心的任务等待队列中选取适当的任务执行
# 优点是无需在多个CPU间切换
# 板级支持包(BSP)
# 位于主板硬件和操作系统驱动层程序之间的一层,属于操作系统的一部分,实现对操作系统的支持
# 为上层的驱动程序提供访问硬件设备寄存器的函数包,使之能够更好的运行于硬件主板
具体功能包括:
# 1、单板硬件初始化,主要是CPU初始化,为整个软件系统提供底层硬件支持
# 2、为操作系统提供设备驱动程序和系统终端服务程序
# 3、定制操作系统的功能,为软件系统提供一个实时多任务的运行环境
# 4、初始化操作系统,为操作系统的正常运行做好准备
主要具有以下两个特点:
硬件相关性
# 嵌入式实时系统的硬件环境具有应用相关性,BSP作为上层软件与硬件平台之间的接口
# 需要为操作系统提供操作和控制硬件的方法
操作系统相关性
# 不同的操作系统具有各自的软件层次结构,因此不同的操作系统具有特定的硬件接口形式
BSP主要包括两个方面的内容:引导加载程序BootLoader和设备驱动程序
- BootLoader是嵌入式系统加电后运行的第一段软件代码,是在操作系统内核运行之前运行的一小段程序,通过这段程序,可以初始化硬件设备、建立内存空间的映射图,从而将系统的软硬件环境设置到一个合适的状态,以便为最终调用操作系统内核做好准备。一般包括以下功能:
片级初始化
# 主要完成微处理器的初始化
# 包括设置微处理器的核心寄存器和控制寄存器、微处理器的核心工作模式及其局部总线模式等
# 片级初始化把微处理器从上电时的默认状态逐步设置成系统所要求的工作状态。这是一个纯硬件的初始化过程
板级初始化
# 通过正确地设置各种寄存器的内容来完成微处理器以外的其他硬件设备的初始化
# 在此过程中,除了要设置各种硬件寄存器以外,还要设置某些软件的数据结构和参数
# 因此,这是一个同时包含有软件和硬件在内的初始化过程
加载内核(系统级初始化)
# 将操作系统和应用程序的映像从Flash存储器复制到系统的内存中
# 然后跳转到系统内核的第一条指令处继续执行
- 设备驱动程序:嵌入式系统中,操作系统是可有可无的。但设备驱动程序是必不可少的。设备驱动程序就是一组库函数,用来初始化和管理硬件设备,并向上层软件提供访问接口。设备驱动程序一般具备以下功能:
硬件启动 # 在开机上电或系统重启的时候,对硬件进行初始化
硬件关闭 # 将硬件设置为关机状态
硬件停用 # 暂停使用这个硬件
硬件启用 # 重新启用这个硬件
读操作 # 从硬件中读取数据
写操作 # 往硬件中写入数据
# 嵌入式数据库系统EDBMS
使用环境的特点:
设备随时移动性
网络频繁断接
网络条件多样化
通信能力不对称
嵌入式数据库系统的组成:(远端)主数据库、同步服务器、(本地)嵌入式数据库和连接网络等几个子系统
注意
嵌入式移动数据库在实际应用中必须解决好数据的一致性(复制性)、高效的事务处理和数据的安全性等关键问题
# 嵌入式系统
嵌入式系统是以特定应用为中心、以计算机技术为基础,并将可配置与可裁剪的软、硬件集成于一体的专用计算机系统。嵌入式系统的组成结构是:
嵌入式处理器、相关支撑硬件、嵌入式操作系统、支撑软件、及应用软件组成
- 嵌入式系统特性:
专用性强 # 嵌入式系统面向特定应用需求,任务集成在芯片内部,从而有利于嵌入式系统的小型化
技术融合 # 嵌入式系统将先进的计算机技术、通信技术、半导体技术和电子技术与各个行业的具体应用相结合
软硬一体软件为主 # 软件是嵌入式系统的主体,硬件为软件服务,根据软件需要进行裁剪
比通用计算机资源少 # 由于嵌入式系统通常只完成少数几个任务。管理的资源少,成本低,结构更简单
程序代码固化在非易失存储器中 # 嵌入式系统中的软件一般都固化在存储器芯片或单片机本身中,不是磁盘中
需专门开发工具和环境 # 嵌入式系统本身不具备开发能力,必须有一套开发工具和环境才能进行开发
体积小、价格低、工艺先进、性能价格比高、系统配置要求低、实时性强
对安全性和可靠性的要求高
- 嵌入式系统分类:
根据不同用途分为嵌入式实时系统和嵌入式非实时系统两种
而实时系统又可分为强实时系统和弱实时系统
从安全性要求看,嵌入式系统还可分为安全攸关系统和非安全攸关系统
安全攸关系统是指其不正确的功能或者失效会导致人员伤亡、财产+损失等严重后果的计算机系统
# 嵌入式实时操作系统RTOS
# 计算机对外来的信息以足够快的速度进行处理并在被控对象允许的时间内做出响应
# 并控制所有实时任务协调一致运行,因此,提供及时响应和高可靠性是其主要特点
# 完全嵌入受控器件内部,为特定应用而设计的专用计算机系统
- 嵌入式实时操作系统的特征:
可预测性 # 是指系统在运行之前,其功能、响应特性和执行结果是可预测的
确定性 # 是指系统在给定的初始状态和输入条件下,在确定的时间内给出确定的结果
高精度计时系统 # 需要精确的实时的操作某个设备或执行某个任务
多级中断机制 # 对紧急程度较高的实时事件及时进行响应和处理
实时调度机制 # 包括两个方面:
# 一是在调度策略和算法上保证优先调度实时任务;二是建立更多"安全切换"时间点,保证及时调度实时任务
# 嵌入式软件
指应用在嵌入式系统当中的软件,除了具有通用软件的一般特性,还有一些个嵌入式系统相关的特点
规模较小、开发难度大、实时性和可靠性要求高、要求固化存储
- 嵌入式软件的分类:
系统软件
# 控制和管理嵌入式系统资源,为嵌入式应用提供各种支持软件
# 如设备驱动程序、嵌入式操作系统、嵌入式中间件等
应用软件
# 嵌入式系统中的上层软件,定义了嵌入式设备的主要功能和用户,并负责与用户交互
# 一般面型特定的应用领域,如飞行控制软件、手机软件、地图等
支撑软件
# 辅助软件开发的工具软件,如系统分析设计工具、在线仿真工具、交叉编译器等
- 嵌入式软件的组成架构:
硬件层 # 硬件层主要是为嵌入式系统提供运行支撑的硬件环境
抽象层 # 硬件层和软件层之间的为抽象层
# 主要实现对硬件层的硬件进行抽象,为上层应用(操作系统)提供虚拟的硬件资源
# 板级支持包(BSP):
# 是一种硬件驱动软件,面向硬件层的硬件芯片或电路进行驱动,为上层操作系统提供对硬件的管理支持
操作系统层 # 主要由嵌入式操作系统、文件系统、图形用户接口、网络系统和通用组件等可配置模块组成
中间件层 # 一般位于操作系统之上,管理计算机资源和网络通信,中间件层是连接两个独立应用的桥梁
应用层 # 应用层是指嵌入式系统的具体应用,主要包括不同的应用软件
- 嵌入式软件的主要特点:
可剪裁性
# 根据系统功能需求,通过工具对适应性功能进行加减,删掉不需要的模块,使系统更加紧凑
# 常用的方法包括:静态编译、动态库和控制函数流程
可配置性
# 可以根据系统的功能或性能,对软件工作状况进行能力扩展、变更和增量服务
# 常用的方法包括:静态编译、配置表、数据驱动
强实时性
# 要求任务必须在规定的时间内处理完成,因此,嵌入式软件采用的算法优劣是影响实时性的主要原因
# 常用的方法包括:动/静态结合、表驱动、配置、汇编语言
高确定性
# 嵌入式系统运行的时间、状态和行为是预先设计好的,不随时间、状态的变化而变化
# 常用的方法包括:静态分配资源、状态机、越界检查、静态任务调度
安全性
# 是指系统在规定的条件下和规定的时间内不发生事故的能力,是评价系统性能的重要指标
# 常用的方法包括:编码标准、安全保障机制、FMECA
可靠性
# 是指系统在规定的条件下和规定的时间内程序执行所需功能的能力,也是评价系统性能的重要指标
# 常用的方法包括:容错技术、余度技术、鲁棒性设计
# 余度技术:也称冗余技术,是指采用两个或两个以上的同样部件或系统,正确、协调地完成同一任务
# 鲁棒性设计:Robust的音译,健壮和强壮的意思。它是指在异常和危险情况下系统生存的能力
# 嵌入式软件设计
一个典型的交叉平台开发环境,包含三个高度集成的部分:
# 运行在宿主机和目标机上的强有力的交叉开发工具和实用程序
# 运行在目标机上的高性能、可裁剪的实时操作系统
# 连接宿主机和目标机的多种通信方式,例如,以太网、USB、串口等
交叉编译
# 嵌入式软件开发所采用的编译为交叉编译。所谓交叉编译就是在个平台上生成可以在另一个平台上执行的代码
# 编译的最主要的工作是将程序转化成CPU所能识别的机器代码,由于不同的体系结构有不同的指令系统
# 因此,不同的CPU需要有相应的编译器,而交叉编译就可以把程序代码翻译成不同CPU的对应可执行二进制文件
# 嵌入式系统的开发需要借助宿主机(通用计算机)来编译出目标机的可执行代码。
交叉调试
# 嵌入式软件经过编译后即进入调试阶段,和通用软件开发过程中的调试方式有很大的差别
# 调试时采用的是在宿主机和目标机之间进行的交叉调试,调试器仍然运行在宿主机的通用操作系统之上
# 调试的进程却是运行在特定硬件平台的嵌入式操作系统中,调试器和被调试进程通过串口或者网络进行通信
# 调试器可以控制、访问被调试进程,读取被调试进程的当前状态并能够改变被调试进程的运行状态
注意
在嵌入式系统的存储部件中存储速度从快到慢分别是:寄存器组、Cache、内存、Flash
# 计算机网络
# 网络功能和分类
计算机网络的功能 # 数据通信、资源共享、管理集中化、实现分布式处理、负载均衡
网络性能指标 # 速率(比特/秒 b/s)、带宽(频带宽度或传送线路速率)、吞吐量、时延、往返时间、利用率
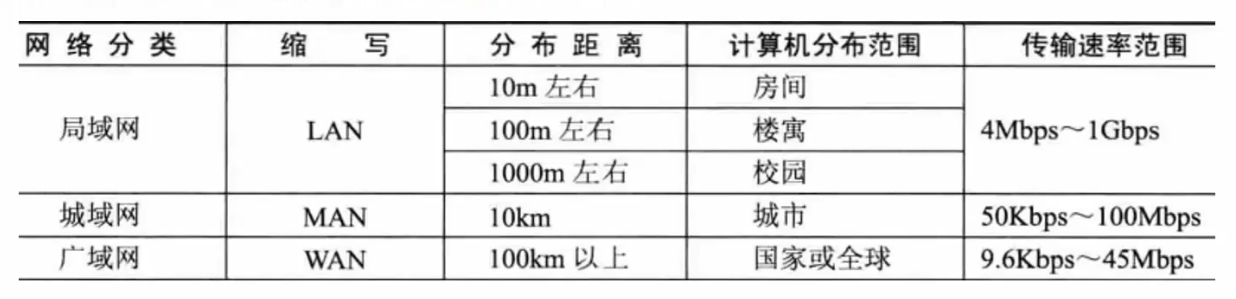
按分布范围划分:
按拓扑结构划分:
总线型 # 利用率低、干扰大、价格低
星型 # 交换机形成的局域网、中央单元负荷大
环型 # 流动方向固定、效率低扩充难
树型 # 总线型的扩充、分级结构
分布式 # 任意节点连接管理难成本高
 新一代的移动通信技术,5G特征体现在以下方面:
新一代的移动通信技术,5G特征体现在以下方面:
# 基于OFDM 优化的波形和多址接入
# 实现可扩展的OFDM 间隔参数配值
# OFDM 加窗提高多路传输效率
# 灵活框架设计
# 大规模MIMO:最多256根天线
# 毫米波:频率大于24GHz 以上的频段
# 频谱共享
# 先进的信道编码设计
# 主要特征:服务化架构、网络切片
# 服务化架构(SBA):可以实现网络功能的灵活定制和按需组合,以及软件快速迭代和升级
# 网络切片:可以在单个物理网络中切分出多个分离的逻辑网络用于不同业务
# OSI七层模型
| 层 | 功能 | 单位 | 协议 | 设备 |
|---|---|---|---|---|
| 物理层 | 在链路(物理传输介质,如网线)上透明地传输位 | 比特 | RS-232=>DB9/485/422/449、RJ-45(双绞线)、FDDI | 中继器、集线器 |
| 数据链路层 | 把不可靠的信道变为可靠信道提供点到点的帧传输 | 帧 | SDLC、HDLC、PPP、IEEE802、ATM | 交换器、网桥 |
| 网络层 | 在源节点和目标节点间进行路由先择、拥塞控制、顺序控制、传送包,保证报文的正确性 | IP分组 | IP、ICMP、IGMP、ARP、RARP | 路由器 |
| 传输层 | 提供端到端的可靠、透明数据传输,保证报文的正确性、完整性 | 报文段 | TCP、UDP | 网关 |
| 会话层 | 建立通信进程的逻辑名和物理名之间的联系 | RPC、SQL、NFS | 网关 | |
| 表示层 | 实现数据转换,提供标准的应用接口 | JPEG、ASCII、MPEG、DES | 网关 | |
| 应用层 | 提供各种服务,如EMail | 数据 | Telnet、FTP、HTTP、SMTP、POP3、DNS、DHCP | 网关 |
- 交换机
# 交换机功能包括集线功能、中继功能、桥接功能、隔离冲突域功能,交换机协议有:
# 生成树协议(STP):可以很好地解决链路环路问题
# 链路聚合协议:提升与相邻接交换设备之间的端口带宽,提高链路可靠性
- 路由器
# 包括异种网络互连、子网协议转换、数据路由、速率适配、隔离网络、报文分片和重组、备份和流量控制
# 路由器协议主要有:
# 内部网关协议(IGP):指在一个自治系统(As)内运行的路由协议
# 外部网关协议(EGP):指在 AS 之间的路由协议。EGP 是为简单的树型拓扑结构设计的
# 边界网关协议(BGP):在 EGP 的经验之上制定了新的网关协议即 BGP,也是 Internet 上唯一的网关协议
# 局域网和广域网协议
# 以太网是一种计算机局域网组网技术。以太网规范IEEE 802.3 是重要的局域网协议
# 以太网数据帧的最小长度 64 字节,最大长度一般是 1518 字节
# 设置最小帧长是为了避免冲突,最小帧长是根据网络中检测冲突的最长时间来定的
# 无线局域网WLAN技术标准:IEEE 802.11
# 在 WLAN 中,通常使用的拓扑结构主要有3种形式:点对点型、HUB型和全分布型
| IEEE 802.3 | 标准以太网 | 10Mb/s | 传输介质为细同轴电缆 |
| IEEE802.3u | 快速以太网 | 100Mb/s | 双绞线 |
| IEEE 802.3z | 千兆以太网 | 1000Mb/s | 光纤或双绞线 |
| IEEE 802.3ae | 万兆以太网 | 10Gb/s | 光纤 |
广域网由通信子网与资源子网组成。广域网可以分为公共传输网络、专用传输网络和无线传输网络3类。广域网相关技术:
同步光网络 # SONET,利用光纤进行数字化信息通信
数字数据网 # DDN,利用数字信道提供半永久性连接电路以传输数据
帧中继 # FR,数据包交换技术
异步传输技术 # ATM,以信元为基础的面向连接的一种分组交换和复用技术
# TCP/IP协议
网络协议三要素:语法、语义、时序
语法 # 规定传输数据的格式
语义 # 规定所要完成的功能
时序 # 规定执行各种操作的条件、顺序关系等
TCP/IP四层协议:
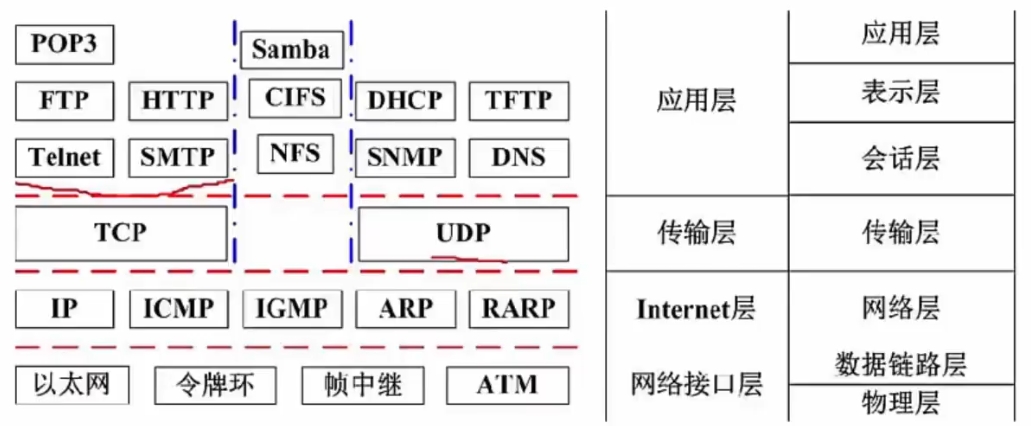 网络层协议:
网络层协议:
IP # 网络层最重要的核心协议,在源地址和目的地址之间传送数据报,无连接、不可靠
ICMP # 因特网控制报文协议,用于在IP主机、路由器之间传递控制消息
# 控制消息是指网络通不通、主机是否可达、路由是否可用等网络本身的消息
ARP和RARP # 地址解析协议,ARP是将IP地址转换为物理地址,RARP将物理地址转换为IP地址
IGMP # 网络组管理协议,允许因特网中的计算机参加多播,支持组播
传输层协议:
TCP # 为应用程序提供了一个可靠的、面向连接的、全双工的数据传输服务
# 一般用于传输数据量比较少,且对可靠性要求高的场合
# 三次握手,四次挥手
UDP # 是一种不可靠、无连接的协议,有助于提高传输速率
# 一般用于传输数据量大,对可靠性要求不高,但要求速度快的场合
应用层协议:
基于TCP的传输:
FTP # 可靠的文件传输协议,用于因特网上的控制文件的双向传输
HTTP # 超文本传输协议。使用SSL加密后的安全网页协议为HTTPS
SMTP和POP3 # 简单邮件传输协议,邮件报文采用ASCI1格式表示
TeInet # 远程连接协议,是因特网远程登录服务的标准协议和主要方式
基于UCP的传输:
TFTP # 不可靠的、开销不大的小文件传输协议
SNMP # 简单网络管理协议,能够支持网络管理系统,用于监测连接到网络上的设备是否有任何异常
DHCP # 动态主机配置协议,为主机动态分配IP地址,有三种方式:固定分配、动态分配、自动分配
DNS # 域名解析协议,通过域名解析出IP地址
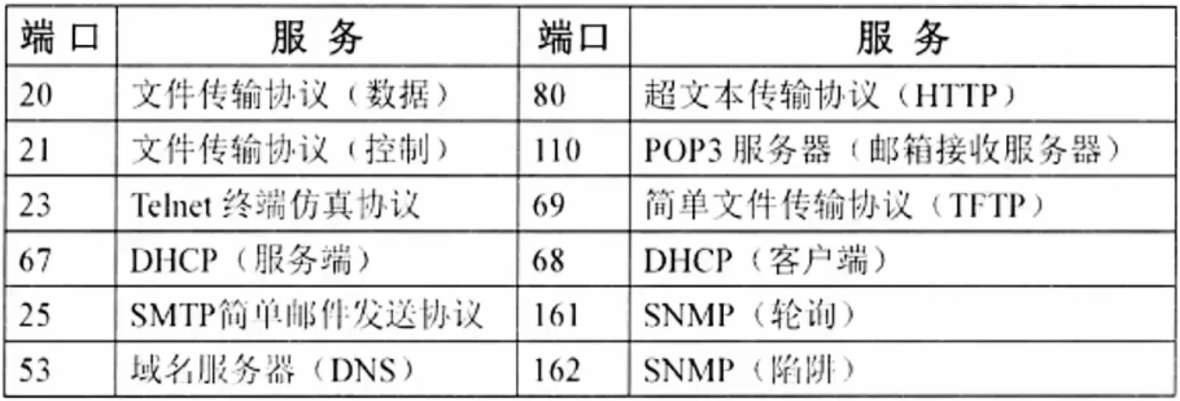
协议端口号对照表:
# 传输介质
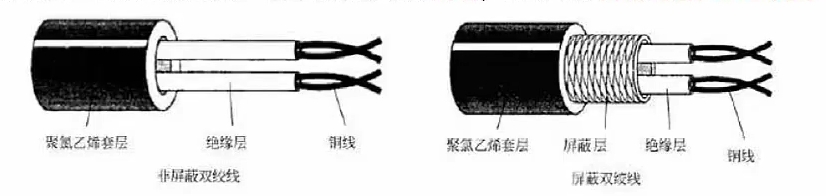
双绞线 # 即网线,将多根铜线按规则缠绕在一起,能够减少干扰,传输电信号
# 分为无屏蔽双绞线UTP和屏蔽双绞线STP,屏蔽层的作用是抗干扰,价格高
# 双绞线的传输距离在100m以内
网线有两种安装标准接口:
T568A # 白绿绿、白橙蓝、白蓝橙、白棕棕
T568B # 白橙橙、白绿蓝、白蓝绿、白棕棕
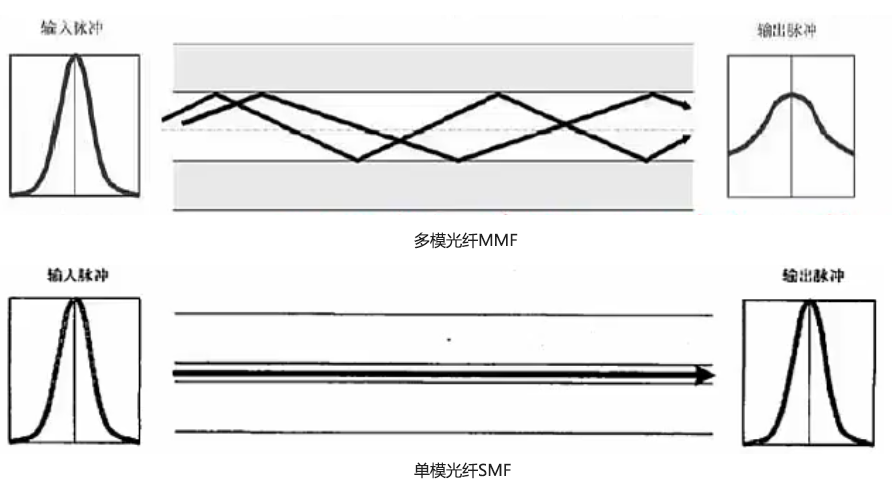
光纤 # 由纤芯和包层组成,传输光信号
# 然而从PC端出来的信号都是电信号,要经过光纤传输的话,就必须将电信号转换为光信号
多模光纤MMF # 纤芯半径较大,可以同时传输多种不同的信号,光信号在光纤中以全反射的形式传输
# 采用发光二极管LED为光源,成本低,传输的效率和可靠性都较低,适合于短距离传输
# 其传输距离与传输速率相关,速率为100Mbps时为2KM,速率为1000Mbps时为550m
单模光纤SMF # 纤芯半径很小,只能传输一种信号,采用激光二极管LD作为光源,并且只支持激光信号的传播
# 同样是以全反射形式传播,只不过反射角很大,看起来像一条直线
# 成本高,传输距离远,可靠性高。传输距离可达5KM
无线信道 # 分为无线电波和红外光波
# 通信技术
数据与信道
# 通信中的数据包括模拟信号和数字信号,通过信道来传输,信息传输就是信源和信宿通过信道收发信息的过程
# 信道可分为逻辑信道和物理信道
# 逻辑信道:在数据发送端和接收端之间存在的一条虚拟线路,可以是有连接的或无连接的,以物理信道为载体
# 信号在信源端和信宿端都需要经过信号变换,中间经过编码、交织、调制和解码等过程
复用技术
# 是指在一条信道上同时传输多路数据的技术,如TDM 时分复用、FDM 频分复用和 CDM 码分复用等
# 即一条路上行驶多辆货车
多址技术
# 是指在一条线上同时传输多个用户数据的技术,在接收端把多个用户的数据分离
# 如TDMA时分多址、FDMA 频分多址和 CDMA 码分多址等,即一辆车上的货物属于不同用户
5G通信网络
# 作为新一代的移动通信技术,网络结构、网络能力和应用场景等都与过去有很大不同
# 具有高速率、低时延、接入用户数高等优点
# 通信方式
单工 # 只能由设备A发给设备B,即数据流只能单向流动
半双工 # 设备A和设备B可以互相通信,但是同一时刻数据流只能单向流动
全双工 # 设备A和设备B在任意时刻都能互相通信
# 交换方式
电路交换 #发送方和接收方之间会建立专用电路,面向连接、实时性高、链路利用率低,一般用于视频语音通信
报文交换 #以报文为单位的存储转发模式,接收数据后先存储再校验,因此会有延时,但可靠性高,面向无连接
分组交换 #以分组为单位,也是存储转发模式,但分组的长度比报文小,所以时延小于报文交换,可分三种:
数据报 # 是主流的交换方式,各分组携带地址信息,自由选择接收方,是面向无连接的,但是不可靠的
虚电路 # 发送方和接收方之间建立一个虚拟的通信线路,空闲时也可以传输其他数据,是面向连接的,可靠的
信元交换 # 异步传输技术ATM采用的交换方式,本质是按照虚电路方式进行转发,也是面向连接的,可靠的
# 只不过信元是固定长度的分组,共53B,其中5B为头部,48B为数据域
# IP地址表示
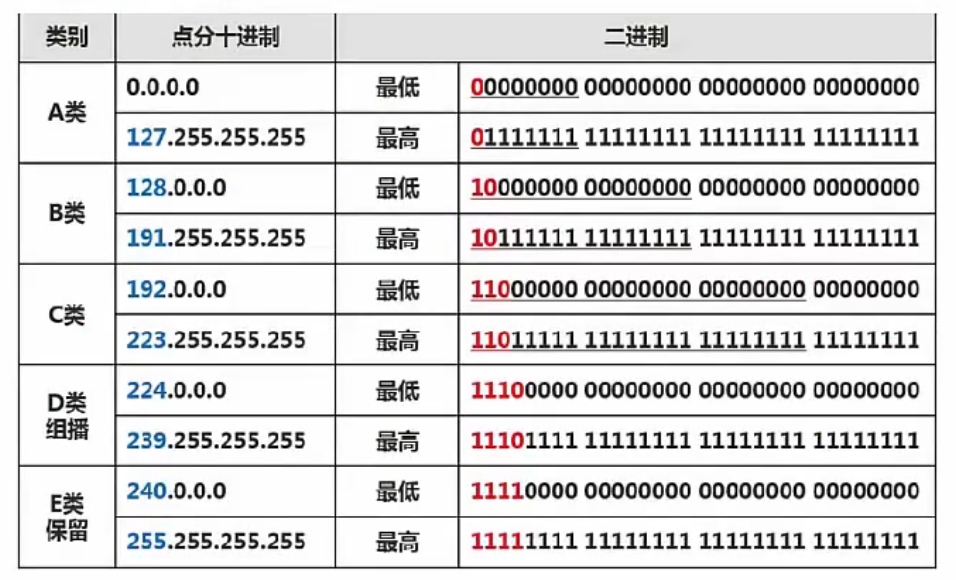
# IP地址是32位的二进制代码,每隔8位插入一个空格,因此每个十进制数的取值范围为0-255

分类编址 # 在逻辑上,这32位IP地址分为网络号和主机号,依据网络号位数的不同,可以将IP地址分为
# 带下划线的为网络号,标红色的为固定前缀,如A类可以表示2的24次方-2个主机
# 同一个网段就是网络号相同的IP地址
网络掩码 # 用来表示IP地址中的哪一部分是被用来表示主机地址的
# A类:255.0.0.0 B类:255.255.0.0 C类:255.255.255.0
无分类编址 # 即不按照A BC类规则,自动规定网络号,无分类编址格式为:IP地址/网络号
# 如 128.168.0.11/20表示IP地址为128.168.0.11,网络号占20位,主机号占32-20=12位
# 也可以划分子网
公有地址 # 通过它直接访问因特网。是全网唯一的IP地址
私有地址 # 属于非注册地址,专门为组织机构内部使用,不能直接访问因特网,下表所示为私有地址范围:

# 子网划分
子网划分
# IP地址按标准划分为ABC类后,再一步的划分主机号,拿出几位作为子网号,就可以划分出多个子网
# 此时IP地址组成为:网络号+子网号+主机号
# 例如:一个C类IP地址,网络号(24位)+子网号(3位)+主机号(5位),共有2^3个子网,每个子网有2^5个主机
子网掩码 # 网络号和子网号都为1,主机号都为0,这样的地址为
# 上面例子的子网掩码为:255.255.255.224(11100000)
聚合网络为超网 # 划分子网的逆过程,将网络号取出几位作为主机号
# 这样网络内的主机数量就变多了,成为一个更大的网络
注意
- 子网号可以为全0和全1,主机号不能为全0或全1,因此,主机数需要-2
- 同一个子网就是网络号相同的IP地址

# IPV6
IPv6具有以下特性:
# IPv6地址长度为128位
# 灵活的IP报文头部格式,使用一系列固定格式的扩展头部取代了IPv4中可变长度的选项字段
# IPv6简化了报文头部格式,加快报文转发,提高了吞吐量
# 提高安全性,身份认证和隐私权是IPv6的关键特性
# 支持更多的服务类型
# 允许协议继续演变,增加新的功能,使之适应未来技术的发展
IPv4和IPv6的过渡期间主要采用三种基本技术:
双协议栈
# 主机同时运行IPv4和IPv6两套协议栈,同时支持两套协议
# IPv4和IPv6地址之间存在某种转换关系,IPv6的低32位可以直接转换为IPv4地址,实现互相通信
隧道技术
# 在IPv4网络之上建立一条能够传输IPv6数据报的隧道
# 可以将IPv6数据报当做IPv4数据报的数据部分加以封装,再加一个IPv4的首部,就能在IPv4中传输IPv6报文
翻译技术
# 利用一台专门的翻译设备(如转换网关),在纯IPv4和纯IPv6网络之间转换IP报头的地址
# 同时根据协议不同对分组做相应的语义翻译,从而使纯IPv4和纯IPv6站点之间能够透明通信
# 网络规划与设计
城域网(MAN)采用IEEE 802.6标准。两个模型,一个逻辑模型(三层模型),一个物理模型(建筑物综合布线系统PDS)
三层模型将网络划分为:
核心层 # 提供不同区域之间的最佳路由和高速数据传送(只负责高速的数据转发)
汇聚层 # 将网络业务连接到接入层,并且实施与安全、流量、负载和路由相关的策略
接入层 # 为用户提供在本地网段访问应用系统的能力,还要解决相邻用户之间的互访需要
# 接入层要负责一些用户信息(用户IP地址、MAC地址和访问日志等)的收集工作
# 和用户管理功能(包括认证和计费等)
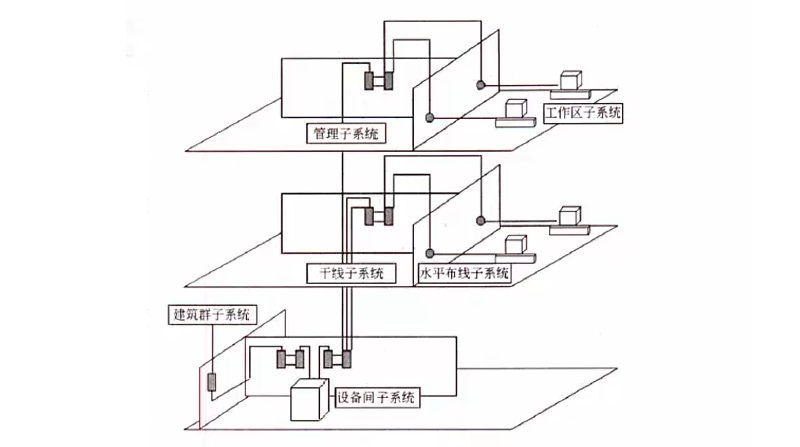
建筑物综合布线系统PDS(结构化布线系统):
工作区子系统 # 实现工作区终端设备和水平布线子系统的信息插座之间的互联
水平布线子系统 # 实现信息插座和管理子系统之间的连接
管理子系统 # 连接各楼层水平布线子系统和垂直干线子系统
垂直干线子系统 # 实现各楼层设备间子系统的互连
设备间子系统 # 实现中央主配线架与各种不同设备之间的连接
建筑群子系统 # 各建筑物通信系统之间的互联
# 网络存储技术
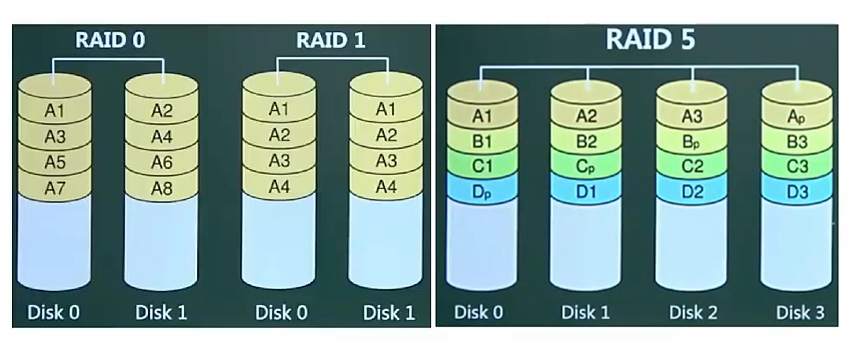
RAID:即磁盘冗余阵列技术:
# 将数据分散存储在不同的磁盘中,可冗余存储,提高磁盘访问速度,保障数据安全性
RAID0 # 将数据分散的存储在不同磁盘中,磁盘利用率100%,访问速度最快,不提供冗余和错误修复技术
RAID1 # 在成对独立磁盘上互为备份的数据,增加存储可靠性,可以纠错,但磁盘利用率只有50%
RAID5 # 在所有磁盘上交叉存储数据及奇偶校验信息(Ap/Bp/Cp/Dp),所有检验信息总量为一个磁盘容量
# 利用率:(n-1)/n,允许一块磁盘坏,读/写指针可同时操作
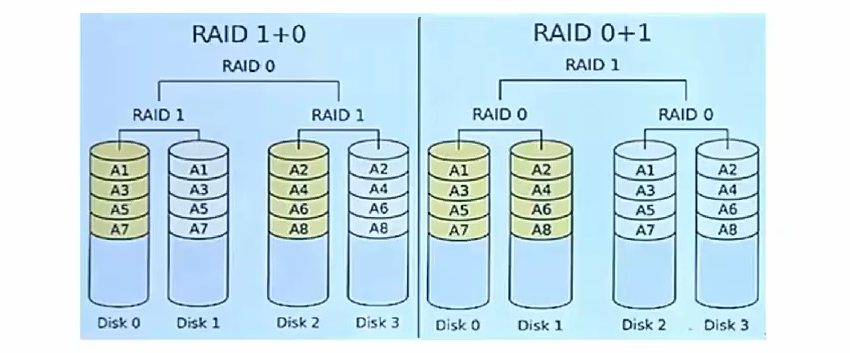
RAID0+1 # 两个RAID0组成一个RAID1,若一个磁盘损坏,则当前RAID0无法工作,即有一半的磁盘无法工作
RAID1+0 # 两个RAID1组成一个RAID0,不允许同组中的两个磁盘同时亏损
# 与RAID1类似,磁盘利用率都只有50%,但安全性更高
 其它网络存储技术:
其它网络存储技术:
直接附加存储(DAS)
# 存储设备通过SCSI接口直接连接到服务器上使用,是硬件的堆叠,存储操作依赖于服务器不带任何存储操作系统
存在问题:
# 在传输距离、传输速率、连接数量等方面都受到限制
# 容量难以扩展升级
# 数据处理和传输能力降低
# 服务器异常会波及存储器
网络附加存储(NAS)
# 通过网络接口直接与网络相连,用户通过网络访问,有独立的存储系统
特点是:
# 进行小文件级的共享存取
# 支持即插即用
# 可以很经济的解决存储容量不足的问题,但难以获得满意的性能
存储区域网(SAN)
# 通过专用交换机将磁盘阵列(一个或多个网络存储设备)与服务器连接起来的高速专用子网
# 没有采用文件共享存取,采用块存储。最大特点是将存储设备从传统以太网中分离出来,成为独立的存储区域网
# 根据数据传输过程采用的协议,其技术划分为FC SAN(光纤通道)、IP SAN(IP网络)和IB SAN(无线带宽)
# 其他考点补充
网络地址翻译NAT # 把公司内私有的地址翻译成外网的共有地址
默认网关 # 一台主机可以有多个网关,默认网关的IP地址与本机IP地址在同一个网段内,即同网络号
冲突域和广播域
# 冲突域是物理层的,广播域是数据链路层的,一个局域网就是一个广播域
# 路由器可以阻断广播域和冲突域,交换机只能阻断冲突域,一个路由器可以划分多个广播域和多个冲突域
# 一个交换机下整体是一个广播域,可以划分多个冲突域,而物理层设备集线器下整体是一个冲突域和广播域
虚拟局域网VLAN
# 是一组逻辑上的设备和用户,不受物理位置的限制,相互之间像在同一个网段中一样
# VLAN工作在OSI模型的第二层和第三层,一个VLAN就是一个广播域,VLAN之间通信是通过第三层路由器来完成
← 韩语学习