# 模型微调
# 全量微调可对模型的能力进行深度改造,但要带入全部参数进行训练,消耗大量的算力且有一定的技术门槛
# 相比之下,在绝大多数场景中,如果我们只想提升模型某个具体领域的能力,那高效微调会更加合适
# 2020年前后,深度学习领域诞生了很多高效微调的方法,但现在最主流的高效微调方法只有一种——LORA
# LORA 与 QLORA
- LORA(Low-Rank Adaptation)微调 Github地址 (opens new window)
# 旨在通过引入低秩矩阵来减少微调时需要调整的参数数量,从而显著降低显存和计算资源的消耗
# 具体来说,LoRA微调并不直接调整原始模型的所有参数,而是通过在某些层中插入低秩的适配器层来进行训练
- LORA的原理
# 在标准微调中,我们会修改模型的所有权重,而在LoRA中,只有某些低秩矩阵(适配器)被训练和调整
# 这意味着原始模型的参数保持不变,只是通过少量的新参数来调整模型的输出
# 低秩矩阵的引入可以在显存和计算能力有限的情况下,依然有效地对大型预训练模型进行微调
# 从而让LoRA成为显存较小的设备上的理想选择
- LORA的优势
# 显存优化:只需要调整少量的参数(适配器),显著减少了显存需求,适合显存有限的GPU
# 计算效率:微调过程中的计算负担也更轻,因为减少了需要调整的参数量
# 灵活性:可以与现有的预训练模型轻松结合使用,适用于多种任务,如文本生成、分类、问答等
- QLoRA(Quantized Low-Rank Adaptation)
# 是LoRA的一个扩展版本,它结合了LoRA的低秩适配器和量化技术,进一步优化了计算效率和存储需求
# 与LoRA不同的是,QLoRA会将插入的低秩适配器层的部分权重进行量化(通常量化为INT4或INT8)
# 在保持性能的同时显著降低模型的存储和计算需求
# 核心思想: 在LoRA的基础上加入量化技术,减少权重表示的位数,从而降低显存和计算需求
# 主流微调工具
- unsloth GitHub (opens new window)
# unsloth是一个专为大型语言模型(LLM)设计的微调框架,旨在提高微调效率并减少显存占用
# 它通过手动推导计算密集型数学步骤并手写GPU内核,实现了无需硬件更改即可显著加快训练速度
# unsloth 与 HuggingFace 生态兼容,可以很容易地与 transformers、peft、tr 等库结合
# 以实现模型的监督微调(SFT)和直接偏好优化(DPO),仅需型的加载方式,无需对现有训练代码进行修改
- LLaMA-Factory GitHub (opens new window)
# LLaMA-Factory 是一个统一且高效的微调框架
# 旨在为超过 100种大型语言模型(LLMS)和视觉语言模型(VLMS)提供便捷的微调支持
# 用户能够灵活地定制型以适应各种下游任务,封装程度没有unsloth高
- ms-swift GitHub (opens new window)
# 由魔搭社区开发的高效微调和部署框架,主要针对Qwen系列
# 旨在提供一站式的大模型与多模态大模型的训练、推理、评测、量化和部署方案
# 支持超过450种大型模型(LLMS)和150多种多模态大模型(MLLMs)的训练和部署
# 包括最新的模型版本,如 Qwen2.5、InternLM3、GLM4、Llama3.3、DeepSeek-R1、Yi1.5 等
# 以及多模态模型如 Qwen2.5-VL、Qwen2-Audio、Llama3.2Vision、Llava、InternVL2.5 等
# 操作系统选择
由于绝大多数工业场景下微调会涉及多卡微调,目前只有Linux系统对Deepspeed和其他多卡并行加速库支持较好,因此绝大多数工业场景下都会使用Ubuntu操作系统或CentOS操作系统,若想体验更加真实的工业场景下的微调流程,也可以考虑在AutoDL (opens new window)上租赁显卡。
# 使用 unsloth 微调过程
- 安装部署 unsloth
# 安装部署
pip install unsloth
pip install --force-reinstall --no-cache-dir --no-deps /
git+https://github.com/unslothai/unsloth.git
若是AutoDL (opens new window)服务器,且Github网速不稳,则可以使用如下命令开启AutoDL学术加速:
source /etc/network_turbo
- wandb 安装与注册 官网 (opens new window)
# 在大规模模型训练中,我们往往需要监控和分析大量的训练数据,而WandB可以帮助我们实现这一目标
# 实时可视化:
# WandB可以实时展示训练过程中关键指标的变化,如损失函数、学习率、训练时间等
# 通过这些可视化数据,我们能够直观地了解模型的训练进展,快速发现训练中的异常或瓶颈
# 自动记录与日志管理:
# WandB会自动记录每次实验的参数、代码、输出结果,确保实验结果的可追溯性
# 无论是超参数的设置,还是型的架构调整,WandB都能够帮助我们完整保留实验记录,方便后期对比与调优
# 支持中断与恢复训练:
# 在长时间的预训练任务中,系统中断或需要暂停是常见的情况
# 通过WandB的checkpoint功能,我们可以随时恢复训练,从上次中断的地方继续进行,避免数据和时问的浪费
# 多实验对比:
# 当我们尝试不同的模型配置或超参数时
# WandB允许我们在多个实验之间轻松进行对比分析,帮助我们选择最优的模型配置
# 团队协作:
# WandB还支持团队协作,多个成员可以共同查看实验结果,协同调试模型
# unsloth 和 wandb 已高度集成,只需提供 wandb key即可
# 安装部署
pip install wandb
- DeepSeek-R1-Distill-Llama-8B-GGUF 模型下载
# 安装 modelscope,下载的模型为 Safetensor 格式
pip install modelscope
# 下载 Safetensor 格式的模型
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Llama-8B \
--local_dir D:\DeepSeek\Model\modelscope\8B
- 使用 unsloth 加载本地模型
# 查看显卡信息
nvidia-smi
# 一定要安装支持cuda的pytorch
pip install torch==2.3.0+cu121 torchvision==0.18.0+cu121 torchaudio==2.3.0+cu121 /
-f https://mirror.sjtu.edu.cn/pytorch-wheels/torch_stable.html
# windows上通过whl文件安装triton模块,whl文件:
# whl文件下载:https://hf-mirror.com/madbuda/triton-windows-builds
pip install triton-3.0.0-cp310-cp310-win_amd64.whl
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
# 若显存不足,则可以load in_4bit=True,运行4 bit量化版
# 设置为false,则使用模型原本的精度进行推理
load_in_4bit = False
# 加载模型和分词器(文本和数字的转换)
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "./DeepSeek-R1-Distill-Llama-8B",
# 模型会将输入文本按此长度进行截断或补齐操作
max_seq_length = max_seq_length,
dtype = dtype,
# 计算机通常使用 32 位(float32)或 16 位(float16)来表示浮点数以进行计算和存储数据
# 而load_in_4bit意味着将模型的参数从原本较高的精度(如 32 位)量化为 4 位来进行存储和计算
load_in_4bit = load_in_4bit,
# 如果使用Hugging Face 则设置其 token,model_name为其地址
# token = hf_token
)
# 将模型调整为推理模式
FastLanguageModel.for_inference(model) # 推理模式
# FastLanguageModel.for_training(model) # 训练模式
# 定义一个系统提示,并在其中包含问题和回答生成的占位符
prompt_style = """请写出一个恰当的回答来完成当前对话任务。
### Instruction:
你是一个爱助人为乐的好同志.
### Question:
{}
### Response:
<think>{}"""
# 和模型对话
question = "你还好吗,好久不见了" # 可以设置多个 question
# 首先需要借助分词器,将输入的问题转化为标记索引:
inputs = tokenizer([prompt_style.format(question,"")], return_tensors="pt").to("cuda")
# 再带入inputs进行对话
outputs = model.generate(
input_ids = inputs.input_ids,
max_new_tokens = 1200,
use_cache = True,
)
# 此时得到的回复也是词索引,同样需要分词器将其转化为文本
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0]
print(response.split("### Response:")[1])
- 推理模型微调数据集下载
# DeepseekR1 模型组回复结构与微调数据集结构要求:
# DeepSeekR1及其蒸馏模型,推理过程的具体体现就是在回复内容中,会同时包含推理部分<think>和回复部分
# 因此,在微调的时候,微调数据集的回复部分文本也需要是包含推理和最终回复两部分内容(COT数据集)
# 使用 datasets 进行数据集下载
pip install datasets
# medical-o1-reasoning-SFT 医学推理数据集
# 该数据集专为微调 HuatuoGPT-o1 这一医学大语言模型而设计,旨在提升其在复杂医学推理任务中的表现
# 直接从huggingface上下载medical-o1-reasoning-SFT数据集
https://huggingface.co/datasets/Freedomintelligence/medical-o1-reasoning-SFT
由于huggingface网络受限,若是AutoDL服务器,可以按照如下方式开启学术加速:
# 学术资源加速 https://www.autodl.com/docs/network_turbo/
import subprocess
import os
result = subprocess.run('bash -c "source /etc/network_turbo && env | grep proxy"',
shell=True, capture_output=True, text=True)
output = result.stdout
for line in output.splitlines():
if '=' in line:
var, value = line.split('=', 1)
os.environ[var] = value
或者通过魔塔社区 modelscope 下载
modelscope download --dataset FreedomIntelligence/medical-o1-reasoning-SFT --local_dir ./dir
默认情况下数据集保存在主目录下.cache文件夹中,数据文件格式如下所示:
/root/.cache/huggingface/datasets/autodl-tmp/en/0.0.0/8883d72e8b332269

- 小数据量微调
import wandb
from unsloth import FastLanguageModel
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
max_seq_length = 2048
dtype = None
load_in_4bit = True
# 读取模型和分词器
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "D:/DeepSeek/Model/ModelScope/8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
# 定义一个系统提示,并在其中包含问题和回答生成的占位符。该提示将引导模型逐步思考,并提供一个逻辑严谨、准确的回答。
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""
# 设置文本生成结束的标记
EOS_TOKEN = tokenizer.eos_token # <|end_of_sentence|>
# 用于对medical-o1-reasoning-SFT数据集(Question、Complex_CoT、Response)进行修改
# 将Complex_CoT列和Response列进行拼接,并加上文本结束标记
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts, # "text" 列包含了系统提示、指令、思维链和答案
}
# 将从 Hugging Face Hub 加载 FreedomIntelligence/medical-o1-reasoning-SFT 数据集的前 500个 样本
from datasets import load_dataset
dataset = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT","en", split="train[0:500]",trust_remote_code=True)
# 或者通过魔塔社区 modelscope 下载后加载
# dataset = load_dataset("/root/autodl-tmp","en", split="train[0:500]",trust_remote_code=True)
# 进行结构化处理,处理后的数据集默认保存再主目录下的 .cache 文件夹中
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
print(dataset["text"][0])
# 微调模式,通过使用目标模块,我们将通过向模型中添加低秩适配器(low-rank adopter)来设置模型
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407,
use_rslora=False,
loftq_config=None,
)
# 设置训练参数和训练器,通过提供模型、tokenizer、数据集以及其他重要的训练参数,来优化我们的微调过程。
# 使用 SFTTrainer 进行监督微调,适用于transformers 和 Unsloth 生态中的模型微调
trainer = SFTTrainer(
model=model, # 需要进行微调的预训练模型
tokenizer=tokenizer, # 用于将文本转换为模型可以理解的标记索引的分词器
train_dataset=dataset, # 用于训练的数据集
dataset_text_field="text", # 用于训练的文本字段
max_seq_length=max_seq_length, # 输入序列的最大长度
dataset_num_proc=2, # 用于预处理数据集的进程数
# 用于定义训练超参数
args=TrainingArguments(
per_device_train_batch_size=2, # 每次训练几条数据
gradient_accumulation_steps=4, # 梯度累积几个后更新一次
# num_train_epochs = 1, # 训练几轮,训练所有数据
warmup_steps=5, # 学习率预热步数
max_steps=60, # 训练步数,总共使用 max_steps * per_device_train_batch_size * gradient_accumulation_steps 480步
learning_rate=2e-4, # 学习率(2e-4=0.0002 控制权重更新幅度)
fp16=not is_bfloat16_supported(), # 如果GPU不支持bfloat16,则使用fp16
bf16=is_bfloat16_supported(), # 如果支持bfloat16,则启用bfloat16(训练更稳定)
logging_steps=10, # 每10步打印一次训练日志
optim="adamw_8bit", # 使用8位Adam优化器,减少显存占用
weight_decay=0.01, # 权重衰减系数,用于防止过拟合
lr_scheduler_type="linear", # 学习率调度器类型(线性衰减)
seed=3407, # 随机种子,用于保证结果可重复性
output_dir="outputs", # 输出目录,用于保存训练结果
),
)
wandb.login(key="121212121212")
# 开始训练
trainer_stats = trainer.train()
# 使用微调后的模型推理,model是参与完训练的模型
FastLanguageModel.for_inference(model) # 将模型调整为推理模式
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
# 首先需要借助分词器,将输入的问题转化为标记索引:
inputs = tokenizer([train_prompt_style.format(question,"")], return_tensors="pt").to("cuda")
# 再带入inputs进行对话
outputs = model.generate(
input_ids = inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens = 1200,
use_cache = True,
)
# 此时得到的回复也是词索引,同样需要分词器将其转化为文本
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0]
print(response.split("### Response:")[1])
- 模型合并,此时本地保存的模型在 outputs 文件夹中
new_model_local = "DeepSeek-R1-Medical-COT-Tiny" # 创建保存的地址
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
model.save_pretrained_merged(new_model_local, tokenizer, save_method = "merged_16bit",)
训练后的模型文件,如果使用unsloth继续推理调用需要删除 adapter 的2个文件
- 将模型推送到 Hugging Face Hub
new_model_online = "sylone/DeepSeek-R1-Medical-COT" # Hugging Face Hub地址
model.push_to_hub(new_model_online)
tokenizer.push_to_hub(new_model_online)
model.push_to_hub_merged(new_model_online, tokenizer, save_method = "merged_16bit")
# 将其推送到huggingface上并保存为GGUF格式文件并进行调用
model.save_pretrained_gguf("dir", tokenizer,quantization_method="g4km")
# prompt 提示词
# Prompt Engineering 提示词工程
通过设计结构化输入(指令/示例/上下文)引导模型生成目标输出,合适的格式能显著提升模型的理解能力和输出质量。以下是几种高效且常用的格式方案:
- 基础推荐格式(清晰分段式)
# 角色与目标
你是一位[资深营养师],需要为用户设计健康食谱。
# 背景与上下文
用户是一位[素食主义者,有乳糖不耐症],目标是[减重5公斤],时间周期为[1个月]。
# 任务要求
1. 生成一份[7天]的晚餐食谱清单
2. 每餐热量<500卡路里
3. 标注主要营养素比例
4. 避免使用豆制品(用户过敏)
# 输出规范
- 使用表格形式呈现
- 附采购清单(按食材分类)
- 添加烹饪难度提示(⭐~⭐⭐⭐)
- 技术型任务(代码生成专用)
## 系统指令
你是一位Python数据科学家,使用pandas和sklearn。
## 用户需求
请编写代码完成以下任务:
1. 从CSV文件`data.csv`加载数据
2. 对`price`列进行Z-score标准化
3. 用KMeans将数据聚为3类
4. 可视化聚类结果(使用matplotlib)
## 约束条件
- 代码必须包含异常处理
- 添加详细注释
- 输出保存为PNG格式
## 示例格式
···python
# 你的代码从这里开始...
···
- 创意生成(多元素控制)
<creative-brief>
<genre>科幻悬疑短篇小说</genre>
<protagonist>
<name>埃利亚斯</name>
<traits>记忆删除症患者、前神经黑客</traits>
</protagonist>
<setting>2097年上海悬浮城邦</setting>
<key-elements>
<element>量子记忆黑市</element>
<element>会说话的机械乌鸦</element>
</key-elements>
<tone>冷峻中带黑色幽默</tone>
<constraints>
<constraint>包含三次剧情反转</constraint>
<constraint>结尾留悬疑</constraint>
</constraints>
</creative-brief>
- 复杂任务(思维链CoT增强)只需要在末尾添加”让我们逐步思考”即可
## 问题分析
用户查询:“比较光伏发电与风电在青藏高原的适用性”
### 需要覆盖维度:
1. 地理条件适配性(海拔/日照/风力)
2. 基础设施挑战(输电/维护)
3. 环境影响对比
4. 投资回报周期
## 执行步骤
[Step 1] 提取青藏高原气象数据特征 →
[Step 2] 计算两种能源效率公式 →
[Step 3] 对比衰减率曲线 →
[Step 4] 生成风险矩阵图
## 输出要求
- 用Markdown表格呈现核心参数
- 绘制决策树结论图(文字描述)
- 标注数据来源可信度
最佳实践原则:
分层结构化 # 用标题/符号分割:角色 → 任务 → 约束 → 输出格式
关键元素显性化 # [重要变量]用方括号标注,避免歧义
示例驱动 #(Few-shot)
防御性提示 # 追加:如遇信息缺失,请明确说明而非猜测
核心缺陷:
脆弱性 # 微调措辞导致输出剧变
扩展瓶颈 # 难以应对高并发场景
无状态性 # 无法处理多轮对话
# Context Engineering 上下文工程
动态上下文构建(RAG)、工作流编排(LangGraph)、资源优化(向量数据库)
# Ollama 的使用
官网 (opens new window) 国内镜像 (opens new window)
# 常用命令
# 查看版本
ollama -v
ollama --version
# 下载模型
ollama pull qwen3:4b
# 运行模型
ollama run qwen3:4b
# 从魔搭(modelscope)拉取GGUF框架的模型
ollama run modelscope.cn/Qwen/Qwen3-8B-GGUF
# 查看运行的大模型是用的cpu还是gpu,还是混合的
ollama ps
# 查看已安装模型
ollama list
# 查看模型信息
ollama show qwen3:4b
# 删除指定模型
ollama rm qwen3:4b
# 启动服务
systemctl start ollama
# 关闭服务
systemctl stop ollama
# 重启服务(如果模型下载失败可重启服务,ollama会自动清理垃圾数据,否则一直下载失败)
systemctl restart ollama
# 开机启动
systemctl enable ollama
# 禁止开机启动
systemctl disable ollama
# 重载配置
systemctl daemon-reload
# 会话管理
# 加载会话或模型
/load <model>:加载一个特定的模型或会话。可以指定一个模型的名称或路径来加载它
# 保存会话
/save <model>:保存当前的会话状态或模型。可以将当前会话或模型的配置保存为一个文件,以便以后使用
# 清除会话上下文
/clear:清除会话上下文。这将删除当前会话中的所有历史记录或对话内容
# 退出会话
/bye:退出会话。这个命令将结束当前与模型的对话,并退出程序
# 修改默认模型下载位置
可以通过设置环境变量OLLAMA_MODELS来修改模型存储位置
Windows系统:
# 默认位置:C:\Users\<用户名>\.ollama/models
# 设置环境变量OLLAMA_MODELS,例如E:\ollama\models。重启Ollama或PowerShell,使设置生效
Linux系统:
# 默认位置:/usr/share/ollama/.ollama/models
# 创建新目录并设置权限,例如sudo mkdir /path/to/ollama/models
# 编辑ollama.service文件,添加环境变量OLLAMA_MODELS。重启ollama服务
# 此路径需要有对应的权限:(例如我的路径是/home/ollama/models/)
sudo chown -R ollama:ollama /home/ollama/models/
sudo chmod -R 777 /home/ollama/models/
# windows 安装
# 如果需要将 Ollama 安装到非默认路径,可以在安装时通过命令行指定路径,例如:
OllamaSetup.exe /DIR="d:\some\location"
# Linux 离线安装
- 下载脚本 install.sh
# 浏览器打开直接打开 https://ollama.com/install.sh下载脚本,或者复制粘贴
# 对应版本的 install.sh 脚本在 github -> Source code(tar.gz) -> ollama-0.6.8 -> scripts 中
- 修改脚本 install.sh
# 1、把脚本中所有的这几行都注释掉。注释掉的地方是不需要下载安装包的代码,因为下载的过程会很慢。
# curl --fail --show-error --location --progress-bar \
# "https://ollama.com/download/ollama-linux-${ARCH}.tgz${VER_PARAM}" | \
# $SUDO tar -xzf - -C "$OLLAMA_INSTALL_DIR"
#curl --fail --show-error --location --progress-bar \
# "https://ollama.com/download/ollama-linux-${ARCH}-jetpack6.tgz${VER_PARAM}" | \
# $SUDO tar -xzf - -C "$OLLAMA_INSTALL_DIR"
#curl --fail --show-error --location --progress-bar \
# "https://ollama.com/download/ollama-linux-${ARCH}-jetpack5.tgz${VER_PARAM}" | \
# $SUDO tar -xzf - -C "$OLLAMA_INSTALL_DIR"
#curl --fail --show-error --location --progress-bar \
# "https://ollama.com/download/ollama-linux-${ARCH}-rocm.tgz${VER_PARAM}" | \
# $SUDO tar -xzf - -C "$OLLAMA_INSTALL_DIR"
# 2、在install_success()函数的上面添加一个命令:
$SUDO tar -xzf ollama-linux-amd64.tgz -C "$OLLAMA_INSTALL_DIR"
# tgz文件是在github上下载的,需要按照自己的操作系统找到对应的
- 运行安装脚本
# 修改权限
chmod +x ./install.sh
# 运行脚本
./install.sh
- 启动文件:/etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=root
Group=root
Restart=always
RestartSec=3
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin"
Environment="OLLAMA_HOST=0.0.0.0:11434" # 默认绑定在127.0.0.1上,远程就没法访问
Environment="OLLAMA_MODELS=/mnt/data/ollama/models"
Environment="OLLAMA_CONTEXT_LENGTH=8192" # 0.5.13版本后新增
[Install]
WantedBy=default.target
- 重载配置
systemctl daemon-reload
systemctl restart ollama
# 导入本地模型
# 创建模型配置文件 Modelfile,不要添加注释
FROM ./模型名称.gguf
# 模型导入
ollama create 自定义模型名称 -f ./Modelfile
# 导入后执行
ollama list
# 运行模型
ollama run model-name
# 默认参数
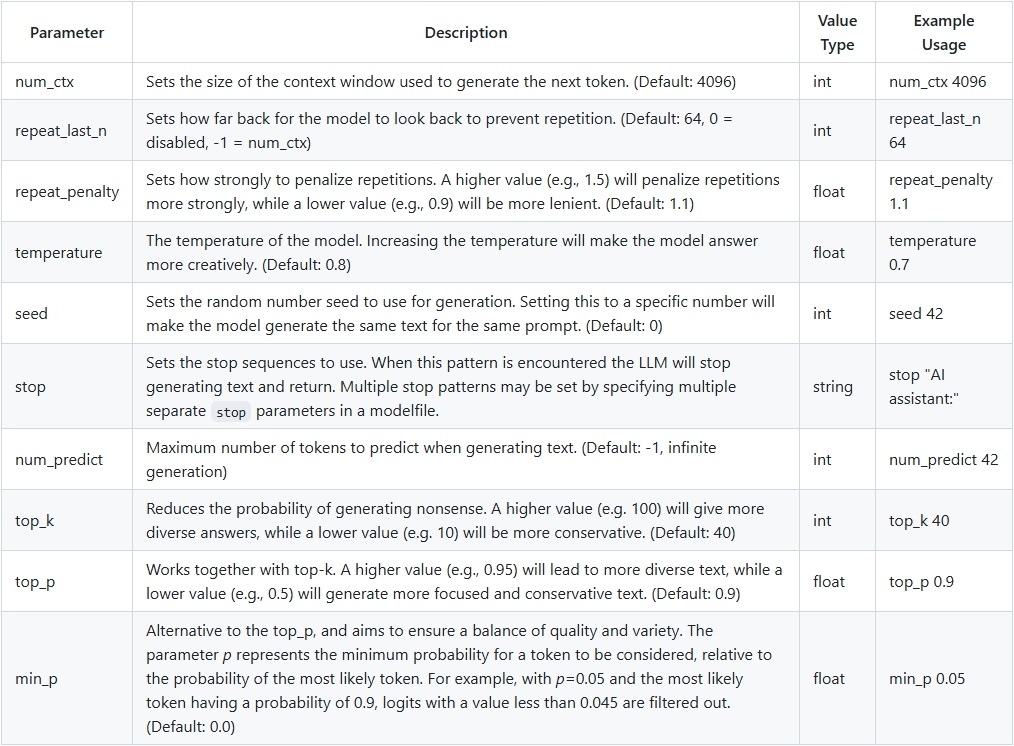
num_ctx
# 模型可以一次记住的最大 token 数量,默认配置 2048
# 相当于一次只能向模型输入 2k token,超过 2k 模型就无法记住。当 prompt 特别长时往往会出现问题
num_predict
# 模型最大可以生成的 token 数量,默认配置 128
# 相当于每次模型只能生成小于 128 token 回复。无法生成长回复
# 配置优化
当我们使用 ollama 安装本地大模型,并且使用 openai 的 api 去调用本地大模型的时候,发现无论我们的输入多长的内容,最终返回的提示词 prompt_tokens 长度只有2048。
- 方法一:修改模型配置参数
# 1、获取模型默认 Modelfile 配置
ollama show llama3.1:8b --modelfile
# 2、将其中默认的 Modelfile 内容复制出来,在本地创建一个 Modelfile 文件,将内容粘贴进去
# 3、查询模型 context length:131072,相当于 128k token
ollama show llama3.1:8b
# 4、在本地 Modelfile 最后,插入两行配置
PARAMETER num_ctx 131072
PARAMETER num_predict -1
# 5、创建新模型,新模型命名 xxxx-max-context
ollama create llama3.1:8b-max-context -f Modelfile
注意
ollama 在0.5.13版本后可以直接在配置文件中启动设置:OLLAMA_CONTEXT_LENGTH=8192
- 方法二:修改请求配置参数
调用ollama自己的的api(/api/chat),不使用openai的api(/v1)去调用时可以在请求配置中调整
import requests
# ollama的api,而非openai的请求方式
url = "http://localhost:11434/api/chat"
payload = {
"model": "deepseek-r1:1.5b",
"stream": False,
"messages": [
{"role": "user", "content": content + "\n\n小说讲了什么内容"},
],
"options": {"num_ctx": 8192} # 上下文参数
}
response = requests.post(url, json=payload)
print(response.text)
# 模型转换
大部分模型不提供 GGUF 格式的模型文件,需要将 safetensors 格式的模型文件转换为 GGUF 格式
# 1、从 https://github.com/ggml-org/llama.cpp/releases 下载对应自己系统的包,并解压到特定目录
# 2、下载 https://github.com/ggml-org/llama.cpp 源代,并和上面下载的编译好的文件放到同一目录中
# 3、进入 llama.cpp 目录下,执行命令安装所有依赖库:pip install -r requirements.txt
# 4、执行命令模型转换:python convert_hf_to_gguf.py [模型文件夹位置]
# API 说明
/api/generate
# 用途: 用于生成单个文本片段。通常不考虑历史消息历史或对话上下文
# 功能: 用于各种生成任务,如文章创作、代码生成、故事编写等,每次请求不依赖前一次请求的结果
/api/chat
# 用途: 用于对话式的交互。通常需要一个消息列表作为输入,以维护对话的历史和上下文
# 功能: 适合创建聊天机器人、问答系统或任何需要多轮对话的应用场景
基于ollama 的流式聊天:
import json
import requests
# NOTE: ollama must be running for this to work, start the ollama app or run `ollama serve`
model = "qwen2:latest" # TODO: update this for whatever model you wish to use
def chat(messages):
r = requests.post(
# "http://127.0.0.1:11434/api/generate",
"http://127.0.0.1:11434/api/chat",
json={"model": model, "messages": messages, "stream": True},
)
r.raise_for_status()
output = ""
for line in r.iter_lines():
body = json.loads(line)
if "error" in body:
raise Exception(body["error"])
if body.get("done") is False:
message = body.get("message", "")
content = message.get("content", "")
output += content
# the response streams one token at a time, print that as we receive it
print(content, end="", flush=True)
if body.get("done", False):
message["content"] = output
return message
def main():
messages = []
while True:
user_input = input("Enter a prompt: ")
if not user_input:
exit()
messages.append({"role": "user", "content": user_input})
message = chat(messages)
messages.append(message)
print("\n\n")
if __name__ == "__main__":
main()
# OpenAI 介绍
# OpenAI API
- Chat Completions 接口,适用于多轮对话,需构造 messages 列表
from openai import OpenAI
client = OpenAI(api_key="YOUR_API_KEY")
# 定义对话历史(包含系统指令、用户和AI的过往消息)
messages = [
{"role": "system", "content": "你是一个专业的技术助手,用简洁的语言回答。"},
{"role": "user", "content": "解释一下递归函数"},
{"role": "assistant", "content": "递归函数是调用自身的函数,需有终止条件防止无限循环。"},
{"role": "user", "content": "举一个Python例子"}
]
# 调用Chat接口
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
temperature=0.7
)
# 提取最新回复
reply = response.choices[0].message.content
print(reply)
- Completions (Generate) 接口,适用于单次文本生成
from openai import OpenAI
client = OpenAI(api_key="YOUR_API_KEY")
# 直接输入prompt
prompt = "将以下英文翻译成中文:\n\n'Artificial intelligence is transforming the world.'"
response = client.completions.create(
model="text-davinci-003", # 经典文本生成模型
prompt=prompt,
max_tokens=50,
temperature=0
)
result = response.choices[0].text.strip()
print(result)
- Batch 接口,支持以文件方式批量提交任务并异步执行
import os
from pathlib import Path
from openai import OpenAI
import time
# 初始化客户端
# 阿里百炼平台介绍:
# https://help.aliyun.com/zh/model-studio/batch-interfaces-compatible-with-openai
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 阿里云百炼服务的base_url
)
def upload_file(file_path):
print(f"正在上传包含请求信息的JSONL文件...")
file_object = client.files.create(file=Path(file_path), purpose="batch")
print(f"文件上传成功。得到文件ID: {file_object.id}\n")
return file_object.id
def create_batch_job(input_file_id):
print(f"正在基于文件ID,创建Batch任务...")
# 请注意:此处endpoint参数值需和输入文件中的url字段保持一致
# 测试模型(batch-test-model)填写/v1/chat/ds-test
# Embedding文本向量模型填写/v1/embeddings,其他模型填写/v1/chat/completions
batch = client.batches.create(input_file_id=input_file_id,
endpoint="/v1/chat/ds-test",
completion_window="24h")
print(f"Batch任务创建完成。 得到Batch任务ID: {batch.id}\n")
return batch.id
def check_job_status(batch_id):
print(f"正在检查Batch任务状态...")
batch = client.batches.retrieve(batch_id=batch_id)
print(f"Batch任务状态: {batch.status}\n")
return batch.status
def get_output_id(batch_id):
print(f"正在获取Batch任务中执行成功请求的输出文件ID...")
batch = client.batches.retrieve(batch_id=batch_id)
print(f"输出文件ID: {batch.output_file_id}\n")
return batch.output_file_id
def get_error_id(batch_id):
print(f"正在获取Batch任务中执行错误请求的输出文件ID...")
batch = client.batches.retrieve(batch_id=batch_id)
print(f"错误文件ID: {batch.error_file_id}\n")
return batch.error_file_id
def download_results(output_file_id, output_file_path):
print(f"正在打印并下载Batch任务的请求成功结果...")
content = client.files.content(output_file_id)
# 打印部分内容以供测试
print(f"打印请求成功结果的前1000个字符内容: {content.text[:1000]}...\n")
# 保存结果文件至本地
content.write_to_file(output_file_path)
print(f"完整的输出结果已保存至本地输出文件result.jsonl\n")
def download_errors(error_file_id, error_file_path):
print(f"正在打印并下载Batch任务的请求失败信息...")
content = client.files.content(error_file_id)
# 打印部分内容以供测试
print(f"打印请求失败信息的前1000个字符内容: {content.text[:1000]}...\n")
# 保存错误信息文件至本地
content.write_to_file(error_file_path)
print(f"完整的请求失败信息已保存至本地错误文件error.jsonl\n")
def main():
# 文件路径
input_file_path = "test_model.jsonl" # 可替换为您的输入文件路径
output_file_path = "result.jsonl" # 可替换为您的输出文件路径
error_file_path = "error.jsonl" # 可替换为您的错误文件路径
try:
# Step 1: 上传包含请求信息的JSONL文件,得到输入文件ID
# 如果您需要输入OSS文件,可将下行替换为:input_file_id ="实际的OSS文件URL或资源标识符"
input_file_id = upload_file(input_file_path)
# Step 2: 基于输入文件ID,创建Batch任务
batch_id = create_batch_job(input_file_id)
# Step 3: 检查Batch任务状态直到结束
status = ""
while status not in ["completed", "failed", "expired", "cancelled"]:
status = check_job_status(batch_id)
print(f"等待任务完成...")
time.sleep(10) # 等待10秒后再次查询状态
# 如果任务失败,则打印错误信息并退出
if status == "failed":
batch = client.batches.retrieve(batch_id)
# 错误码文档:
# https://help.aliyun.com/zh/model-studio/developer-reference/error-code
print(f"Batch任务失败。错误信息为:{batch.errors}\n")
return
# Step 4: 下载结果:如果输出文件ID不为空,则打印请求成功结果的前1000个字符内容
# 并下载完整的请求成功结果到本地输出文件;
# 如果错误文件ID不为空,则打印请求失败信息的前1000个字符内容
# 并下载完整的请求失败信息到本地错误文件
output_file_id = get_output_id(batch_id)
if output_file_id:
download_results(output_file_id, output_file_path)
error_file_id = get_error_id(batch_id)
if error_file_id:
download_errors(error_file_id, error_file_path)
except Exception as e:
print(f"An error occurred: {e}")
if __name__ == "__main__":
main()
# 参数说明
max_tokens
# 指令生成的回答中包含的最大token数。如果设置为100,那么模型中生成的回答中token数不会超过100个
temperature
# 控制文本生成的随机性和创意性。在0到1之间。值越大生成文本越随机;值越小生成文本越确定,一般0.7-1
n # 生成多个回答供选择。返回的数组结果
top_p(控制采样)
# 通过概率控制生成内容的多样性。确定生成本文时考虑的token累计概率。值在0-1之间,常用来替代温度设置
presence_penalty(出现惩罚\阻止调整)
# 鼓励生成新内容,避免出现重复内容。影响模型生成新主题内容的倾向,值在-2.0到2.0之间。
# 较高的值鼓励模型生成前面未出现过的新内容
frequency_penalty(频率惩罚、短语效应)
# 减少重复词语,提高输出的流畅度和多样性。值在-2.0到2.0之间
# 较高的值会减少模型重复使用某些词或短语的频率
stream
# 用于控制参数是否以流式方式接收生成的文本,流式输出意味着生成的文本会逐步发送,而不是一次性发送
# SSE 流式数据
- FastAPI 流式数据返回
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
import json
import time
from typing import Generator
app = FastAPI()
def generate_json_data() -> Generator[str, None, None]:
# 模拟生成大量数据的过程
for i in range(10):
# 每次返回一个 JSON 对象作为字符串
data = {"index": i, "message": f"Data chunk {i}"}
yield json.dumps(data) + "\n"
time.sleep(1) # 模拟延迟,表示流式数据的生成过程
@app.get("/stream-data")
async def stream_data():
return StreamingResponse(generate_json_data(), media_type="application/json")
注意
不要开启中间件压缩功能:add_gzip_middleware(app)
- 前端使用 Fetch
try {
let response = await fetch('/api/admin/common/testStream');
console.log(response);
if (!response.ok) {
throw new Error('Network response was not ok');
}
const reader = response.body.getReader();
const textDecoder = new TextDecoder();
let result = true;
let output = ''
while (result) {
const { done, value } = await reader.read();
if (done) {
console.log('Stream ended');
result = false;
break;
}
const chunkText = textDecoder.decode(value);
output += chunkText;
console.log('Received chunk:', chunkText);
}
} catch (e) {
console.log(e);
}
- 前端使用 Axios
try {
await service.post('/abc', input, {
responseType: 'stream',
adapter: 'fetch',
}).then(async(response)=>{
// 经过响应拦截器service.interceptors.response后返回的 response是 response.data
const reader = response.getReader();
const textDecoder = new TextDecoder();
let result = true;
let output = ''
while (result) {
const { done, value } = await reader.read();
if (done) {
console.log('Stream ended');
result = false;
break;
}
const chunkText = textDecoder.decode(value);
output += chunkText;
console.log('Received chunk:', chunkText);
}
}
} catch (e) {
console.log(e);
}
# RAG 的介绍
在大模型中,RAG 即检索增强生成,是一种将检索技术与语言模型生成能力相结合的技术
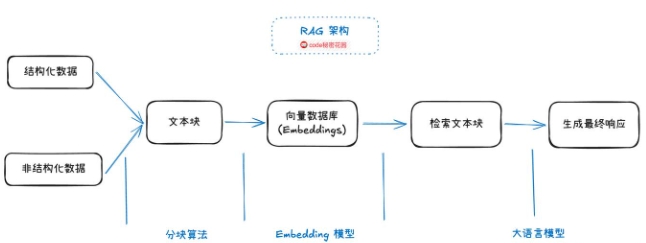
- 原理
# 检索:RAG 首先会根据输入的问题或提示,从一个庞大的外部知识数据库或语料库中检索相关的信息片段
# 融合:将检索到的相关信息与语言模型已有的知识和上下文信息进行融合
# 生成:利用融合后的信息,语言模型生成更加准确、丰富和有针对性的回答或文本内容
# Embedding模型:核心作用是将文本、图像、音频等非结构化数据,转化为计算机可理解的向量数据,
# 这些向量能保留原始数据的语义信息或特征关系
- 优点
# 提高准确性:通过引入外部准确的知识,能有效纠正语言模型可能出现的错误,使生成的内容更符合事实
# 增强时效性:可以及时获取最新的信息并融入生成过程,让生成的文本能够反映最新的事件和知识
# 减少幻觉问题:语言模型有时会生成一些看似合理但实际上错误或无根据的内容
- 应用
# 信息检索与问答系统:用户提问时 RAG 可以快速检索相关知识并生成准确回答,提供更优质的服务
# 内容创作:辅助写作者获取相关资料并生成更有深度和广度的文章、报告等,提高创作效率和质量
# 智能客服:使客服系统能够结合最新的产品信息、常见问题等知识,为用户提供更精准、有效的服务
- 缺点
检索精度不足
# 首先,RAG 最核心的就是先将知识转换成"向量",导入"向量数据库"
# 然后在将用户输入的信息也转换成"向量",然后再去向量数据库匹配出相似的"向量"
# 最后再由大模型去总结检索到的内容
# 大模型仅仅起到了总结的作用,而检索到信息的精准度大部分情况下取决于向量的相似度匹配
# 检索结果可能包含无关内容(低精确率)或遗漏关键信息(低召回率)
生成内容不完整
# 由于 RAG 处理的是文档的切片,而切片的局部性注定了它无法看到整篇文档的信息
# 因此在回答诸如"列举XXX"、"总结XXX"等问题时,一般回答是不完整的
缺乏大局观
# RAG 无法判断需要多少个切片才能回答问题,也无法判断文档间的联系
# 例如,在法律条文中,新的解释可能覆盖旧的解释,但 RAG 无法判断哪个是最新的
多轮检索能力弱
# RAG 缺乏执行多轮、多查询检索的能力,而这对推理任务来说是必不可少的
注意
deepseek 不支持向量搜索(RAG),需要使用单独的向量模型
# RAG 的五种分块策略
- 固定大小分块 (Fixed-size chunking)
# 基于预定义数量的字符、单词或 token 将文本分割成统一的片段
# 通常会中断句子(或观点),重要信息很可能会分散在不同的块中
- 语义分块 (Semantic chunking)
# 根据有意义的单元(如句子、段落或主题部分)对文档进行分段
# 如果第一个片段的 embedding 与第二个片段的 embedding 具有高的余弦相似度,则这两个片段形成一个块
# 这个过程一直持续到余弦相似度显著下降为止。一旦相似度下降,我们就开始一个新的块并重复上述过程
# 由于每个块的内容更丰富,它提高了检索准确性,从而使 LLM 能够生成更连贯和相关的响应
# 一个小问题是,它依赖于一个阈值来确定余弦相似度是否显著下降
- 递归分块 (Recursive chunking)
# 根据段落或章节等固有分隔符进行分块
# 如果块的大小超过预定义的分块大小限制,则将每个块分割成更小的块
# 但是,如果块符合分块大小限制,则不进行进一步分割
# 与固定大小分块不同,这种方法也保持了语言的自然流畅性并保留了完整的语义
- 基于文档结构的分块 (Document structure-based chunking)
# 它利用文档的固有结构,如标题、章节或段落,来定义分块边界
# 通过这种方式,它与文档的逻辑部分对齐,从而保持结构完整性
# 这种方法假设文档具有清晰的结构,但这可能并非总是如此
# 此外,块的长度可能会有所不同,可能会超出模型的 token 限制
- 基于 LLM 的分块 (LLM-based chunking)
# 提示 LLM 生成语义上独立且有意义的块
# 这种方法确保了高语义准确性,因为 LLM 能够理解上下文和含义
# 但这也是所有五种技术中对计算需求最高的分块技术
# GraphRAG
GraphRAG是一种结合知识图谱与检索增强生成(RAG) 的先进技术,旨在通过结构化知识增强大型语言模型(LLM)的推理能力,解决传统RAG在复杂查询和多跳推理中的局限性。
- 关键技术包括:
构建或使用已有知识图谱 # 将实体与实体之间的关系以图的形式表示
图检索(Graph-based Retrieval) # 根据用户问题,在知识图谱中查找相关的实体和关系
图增强生成(Graph-enhanced Generation)# 结合图中检索到的路径或子图信息,生成更准确、连贯的回答
向量库(vector_store_type)# 默认是lancedb,除此之外还支持azure_ai_search
核心在于其处理流程,包含2个阶段 # Indexing和Querying
- 提供的实体类型:
Document # 输入的文档,csv或txt中的单个行
TextUnit # 要分析的文本块,Document与TextUnit关系为1:N关系
Entity # 从TextUnit中提取的实体
Relationship # 两个实体之间的关系,关系由Covariate(协变量)生成
Covariate # 协变量,提取声明信息,包含实体的声明
CommunityReport # 社群报告,实体生成后对其执行分层社群检测,并为该分层中的每个社群生成报告
Node # 节点,实体和文档渲染图的布局信息
# 索引 Indexing
# GraphRAG将输入文本分割为多个可分析单元(称为TextUnits)
# 使用LLM提取实体、关系和关键声明
# 然后通过层次聚类技术(例如Leiden算法)对图谱进行社区划分,并生成每个社区的摘要
- 共经历了14个workflow,6个阶段
14个workflow:
# create_base_documents
# create_final_documents
# create_base_text_units
# join_text_units_to_entity_ids
# join_text_units_to_relationship_ids
# create_final_text_units
# create_base_extracted_entities
# create_summarized_entities
# create_base_entity_graph
# create_final_entities
# create_final_relationships
# create_final_nodes
# create_final_communities
# create_final_community_reports
6个阶段:
# 文档切片(chunk),做Embedding,生成Text Units
# 从文本中提取entities、relationships和claims
# 在entities中执行community detection
# 在多个粒度级别生成community summaries和reports
# 将entities嵌入到graph vector space
# 将text chunk嵌入到textual vector space
# 查询 Querying
- 本地搜索(Local Search):基于实体的推理,用于处理具体的、相对关注细节的问题
# 本地搜索方法将知识图谱中的结构化数据与输入文档中的非结构化数据结合起来
# 在查询时用相关实体信息增强 LLM 上下文
# 这种方法非常适合回答需要了解输入文档中提到的特定实体的问题
# local查询需要的数据来自以下6个文件:
# create_final_nodes.parquet(节点数据)
# create_final_covariates.parquet(协变量或特征数据)
# create_final_entities.parquet(相关联的实体)
# create_final_relationships.parquet(实体相关的关系信息)
# create_final_text_units.parquet(关联的原始文本)
# create_final_community_reports.parquet(社区检测结果报告)
- 全局搜索(Global Search):基于全数据集推理,用于处理摘要总结类、相对抽象的问题
# 根据LLM生成的知识图谱结构能知道整个数据集的结构(以及主题)
# 这样就可以将私有数据集组织成有意义的语义集群,并预先加以总结
# LLM在响应用户查询时会使用这些聚类来总结这些主题
# global查询相比local需要的数据源更少:
# create_final_community_reports.parquet
# create_final_entities.parquet
# create_final_nodes.parquet
# 操作步骤
- 创建虚拟环境,安装项目依赖
pip install -r requirements.txt
- 初始化一个GraphRAG项目的工作目录和配置文件
# python -m graphrag.index 以模块方式运行GraphRAG的索引功能主程序
# --root ./ 指定当前目录 (./) 作为GraphRAG项目的根目录
python -m graphrag.index --init --root ./
- 文件及目录
input # GraphRAG处理的文本文件(如 .txt 文件)放入这个目录
output # 构建索引后,生成的知识图谱、社区报告等结果会保存在这里
cache # 用于缓存中间结果,以加速后续的索引构建过程
prompts # 存储GraphRAG使用的提示词模板
settings.yaml # 可以在这里配置参数等
.env # 用于安全地存放你的API密钥
- 准备测试文档,将文件直接放入ragtest/input文件夹下
- 配置参数,设置.env和settings.yaml
- 优化提示词,提示词调优。选择一条适合的运行
python -m graphrag.prompt_tune # 运行GraphRAG库中的prompt_tune模块
--config ./settings.yaml # 指定配置文件路径为当前目录下的settings.yaml
--root ./ # 设置工作根目录为当前目录
--no-entity-types # 禁用实体类型识别功能,简化处理流程,不进行实体分类
--language Chinese # 指定处理语言为中文
--output ./prompts # 设置输出提示词模板目录为当前目录下的prompts文件夹
# --root:(可选)数据项目根目录,包括配置文件(YML、JSON 或 .env)。默认为当前目录
# --domain:(可选)与输入数据相关的域,如 “空间科学”、“微生物学 ”。默认将从输入数据中推断出来
# --method:(可选)选择文档的方法。选项包括全部(all)、随机(random)或顶部(top)。默认为随机
# --limit:(可选)使用随机或顶部选择时加载文本单位的限制。默认为 15
# --language:(可选)用于处理输入的语言。默认值为“”,表示将从输入中自动检测
# --max-tokens:(可选)生成提示符的最大token数。默认值为 2000
# --chunk-size:(可选)从输入文档生成文本单元时使用的标记大小。默认值为 20
# --no-entity-types:(可选)使用无类型实体提取生成。建议在数据涵盖大量主题或高度随机化时使用
# --output:(可选)保存生成的提示信息的文件夹。默认为 “prompts”
- 构建索引
python -m graphrag.index --root ./
# 查看文件.parquet数据,可以安装插件 Avro and Parquet Viewer,安装后在Pycharm左下侧会有其图标
# Parquet文件常用于大数据处理,能高效存储和读取结构化数据,适用于Spark、Pandas等数据处理框架中
- 执行查询
# 本地搜索
python -m graphrag.query -root ./ragtest --method local "hello,what's your name"
# 全局搜索
python -m graphrag.query -root ./ragtest --method global "hello,what's your name"
# tiktoken
- tiktoken 是 OpenAI 开发的开源的快速 token 切分器
- cl100k_base 是 tiktoken 中一种编码方式
# GPT等大模型,并不是直接将字符串输入大模型,第一步需要做的就是token切分编码
# 文本切分编码是十分有用的,因为GPT都是以token的形式来阅读文本的
# 了解文本中的token数量,可以告诉你字符串是否太长而超出了模型处理能力
import tiktoken
encoder = tiktoken.get_encoding("cl100k_base") # 加载 cl100k_base 编码器
tokens = encoder.encode("Hello, 世界!") # 输出: [9906, 11, 244, 168, 102, 123]
# OpenSPG
# 知识图谱(Knowledge Graph)
是一种以图结构形式组织和表示知识的技术,它将现实世界中的实体(如人、地点、事件、概念等)以及它们之间的复杂关系以节点(实体)和边(关系)的形式构建成网络化的知识库。其核心目标是让机器能够理解和推理人类知识。
- 核心组成
实体(Entities)
# 表示现实中的具体对象或抽象概念,例如“爱因斯坦”“北京”“量子力学”
关系(Relationships)
# 描述实体之间的联系,例如“爱因斯坦-出生地-德国”“北京-是-中国首都”
属性(Attributes)
# 实体的附加信息,例如“爱因斯坦-出生日期-1879年3月14日”
- 典型应用
搜索引擎 # 直接展示答案而非链接,例如搜索“马斯克的公司”会显示特斯拉、SpaceX等
智能问答 # 通过图谱关系回答“姚明的妻子是谁?”
推荐系统 # 利用用户、商品、兴趣的关系网络实现精准推荐(如电商、影视平台)
金融风控 # 分析企业股权关系、担保网络识别风险
医疗诊断 # 链接疾病、症状、药物等知识辅助医生决策
- 常见的知识图谱分类:
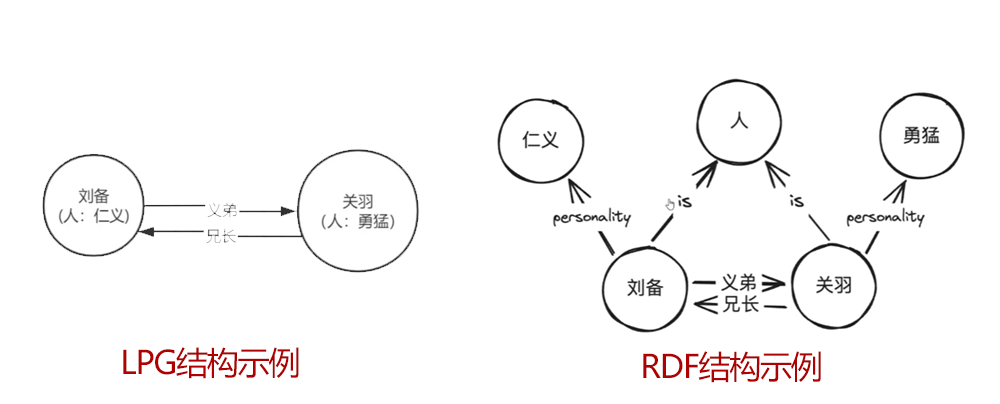
Labeled Property Graph(LPG)
# 是一种带有标签和属性的图结构,用于描述实体及其之间的关系
# 适合需要高性能图分析的长景
# 支持高效的查询和计算
包含的结构:
# 节点:表示实体或概念。如:刘备、关羽
# 边:表示实体间的关系。如:兄长、义弟
# 标签:实体或关系的分类。如:人
# 属性:描述实体或关系的特征。如:仁义、勇猛
Rsource Description Framework(RDF)
# 由节点和边组成。节点可以表示实体或属性,而边便是实体与实体之间的关系,以及实体与属性之间的关系。
# 适合丰富语义表达和推理的应用
# 使用三元组(主语、谓语、宾语)表示知识
包含的结构:
# 节点:表示实体或概念、属性
# 边:表示实体与实体之间、实体与属性之间的关系
# OpenSPG 简介
OpenSPG (opens new window) 是蚂蚁集团与 OpenKG 联合推出的一款基于 SPG(Semantic-enhanced Programmable Graph,语义增强可编程图) 框架的知识图谱引擎。它融合了 LPG(Labeled Property Graph,带标签属性图) 的结构化优势和 RDF(Resource Description Framework,资源描述框架) 的语义表达能力,旨在解决传统知识图谱技术在工业级应用中的不足。
- 工作原理
知识抽取 # KAG模块连接的各种数据源(CSV、API等),使用预定义的提示(prompts)和大模型(LLM)进行抽取
图构建 # 抽取的知识通过SPG-Schema定义的模式进行结构化,构建为图数据库中的节点和关系
推理与查询 # Reasoner模块支持基于图的逻辑推理和查询,用户可通过ISO GQL等查询语言进行复杂的图查询
# KAG
逻辑驱动 + 知识增强 的新一代RAG框架,很适合专业领域的知识服务场景
# MCP 的介绍
# Function Call 函数调用
# 以前的大模型像一个知识丰富但被困在屋里的人,只能靠已有知识回答问题,无法获取实时数据或与外界交互
# 比如不能直接访问数据库里的最新信息,也不能使用一些外部工具来完成特定任务
# Function Call 本质上就是提供了大模型与外部系统交互的能力,类似于给大模型安装一个 “外挂工具箱”
# 当大模型遇到自己无法回答的问题时,它会主动调用预设的函数(如查询天气、计算数据、访问数据库等)
# 获取实时或精准信息后再生成回答
# 虽然后续很多模型也支持了 Function Call 的调用,但是各自实现的方式都不太一样
# 如果要发开一个 Function Call 工具,需要对不同的模型进行适配,比如参数格式、触发逻辑、返回结构等
# MCP 模型上下文协议 Model Context Protocol
是由 Anthropic 公司(也就是开发 Claude 模型的公司)推出的一个开放标准协议,目的就是为了解决 AI 模型与外部数据源、工具交互的难题。
# MCP Host,比如 Claude Desktop、Cursor 这些工具,在内部实现了 MCP Client
# 然后 MCP Client 通过标准的 MCP 协议和 MCP Server 进行交互
# 由第三方开发者提供 MCP Server 负责实现各种资源交互的逻辑,比如访问数据库、浏览器、本地文件
# 最终再通过 标准的 MCP 协议返回给 MCP Client,最终在 MCP Host 上展示

# MCP 客户端(client)
从支持了 MCP 协议的一些客户端/工具列表 (opens new window)里我们可以看到,MCP 对支持的客户端划分了五大能力
Tools # 服务器暴露可执行功能,供 LLM 调用以与外部系统交互
Resources # 服务器暴露数据和内容,供客户端读取并作为 LLM 上下文
Prompts # 服务器定义可复用的提示模板,引导 LLM 交互
Sampling # 让服务器借助客户端向 LLM 发起完成请求,实现复杂的智能行为
Roots # 客户端给服务器指定的一些地址,用来告诉服务器该关注哪些资源和去哪里找这些资源
目前最常用,并且被支持最广泛的就是 Tools 工具调用
# MCP Server
就是通过标准化协议与客户端交互,能够让模型调用特定的数据源或工具功能,常见的 MCP Server 有:
文件和数据访问类 # 让大模型能够操作、访问本地文件或数据库,如 File System MCP Server
Web 自动化类 # 让大模型能够操作浏览器,如 Pupteer MCP Server
三方工具集成类 # 让大模型能够调用三方平台暴露的 API,如 高德地图 MCP Server
查找 MCP Server 的途径:
- 官方的 MCP Server 集合 Github 仓库 (opens new window)
- MCP.so (opens new window) 一个三方的 MCP Server 聚合平台,提供了友好的展示方式,都有具体的配置示例
- MCP Market (opens new window) 访问速度不错,可以按工具类型筛选
# 服务器通信机制
标准输入输出 stdio:# 用于 Server 和 Client 在同一台服务器,不支持远程连接
基于HTTP的服务器推送事件 SSE:# 用于 Server 和 Client 不在同一台服务器,支持远程连接
# 在 Cline 中测试使用
- 内置的 MCP Server # 点击上方工具栏的 MCP Server 图标
- 自己安装 MCP Server
# 点击 installed 按钮,然后点击下方的 Configure MCP Servers
# 打开了一个 JSON 文件,这就是 Cline 用于存放 MCP 配置的地方,里面只有一个空对象
# 每个 MCP Server 都会提供这份配置的写法,比如我们选择的 mcp-mongo-server
# 这里所说的在 Claude Desktop 中使用,其实在任何支持了 MCP 的客户端中都可以这样配置
{
"mcpServers": {
"mongodb": {
"command": "npx",
"args": [
"-y",
"mcp-mongo-server",
"mongodb://muhammed:kilic@mongodb.localhost/sample_namespace"
]
},
"mongodb-readonly": {
"command": "npx",
"args": [
"-y",
"mcp-mongo-server",
"mongodb://muhammed:kilic@mongodb.localhost/sample_namespace",
"--read-only"
]
},
"mongodb-github": {
"command": "npx",
"args": [
"-y",
"github:kiliczsh/mcp-mongo-server",
"mongodb://muhammed:kilic@mongodb.localhost/sample_namespace",
"--read-only"
]
}
}
}
- 配置看着挺复杂的,但实际上它提供了三种配置不同的写法,其实每个配置中只包含两个关键参数:
command # 指定在命令行中通过什么命令进行执行,此例中所有配置都使用 npx 命令,也就是 Node.js 环境
args # 是一个数组,包含传递给 command 的参数
# 这三个配置的意思分别是:
mongodb # 运行 mcp-mongo-server npm 包,并且使用指定的 MongoDB 连接字符串,默认是读写模式
mongodb-readonly # 同样使用相同的 MongoDB 连接字符串,但这个配置会以只读模式运行
mongodb-github # 从 GitHub 上获取包来运行,而不是 npm 包,使用相同的连接字符串,并且也设置了只读
- 我们使用其最简单的配置,本地 mongo 一般不会设置用户名密码,可以直接到客户端查看这个数据库的连接地址:
{
"mongodb": {
"command": "npx",
"args": [
"mcp-mongo-server",
"mongodb://localhost:27017/studentManagement?authSource=admin"
]
}
}
}
- 这个配置粘贴到 Cline 的 MCP 配置文件,然后我们发现左侧的 mongodb 绿灯亮起,说明配置成功
- 最后测试使用,提问问题
# 通过 Prompt 优化查询效果
# MCP Server 为模型提供了访问数据库的能力,但是数据库的表结构对于模型还是完全黑盒的,模型只能靠猜
# 或者去先获取一下表结构,再进行后续操作,多获取一次表结构也会让回答速度变慢,以及消耗更多的 Token
# 所以这里有个优化技巧,我们直接在全局提示词里将表结构的关键信息,和我们的明确要求告诉模型
# 就能让模型更准确、高效的响应了,关于表结构的说明大家可以去用 DeepSeek 来生成
# 目前的局限性
# 切忌让 AI 检索过大的数据,因为这种方式不像 RAG,每次只检索一小部分需要的内容
# 它是真正的会执行 SQL,你要多少数据,就查多少数据
# 如果一次查询数据量过大,会让你消耗大量 Token,甚至让 MCP 客户端卡死
# 很多 MCP 客户端是依靠大量系统提示词来实现与 MCP 工具的通信
# 所以一旦使用 MCP,Token 的消耗量一定会大幅增长
# oneAPI 的使用
oneAPI (opens new window) 是 OpenAI 接口的管理、分发系统。支持 Azure、Anthropic Ciaude、Google PaLM2& Gemini、智谱 ChatGLM、百度文心一言、讯飞星火认知、阿里通义千问、360 智脑以及腾讯混元。
# 安装、部署
# 使用官方提供的release软件包进行安装部署,详情参考中的手动部署
# 下载OneAPI可执行文件one-api并上传到服务器中然后,执行如下命令后台运行
nohup ./one-api --port 3000 --log-dir ./logs > output.log 2>&1 &
# 运行成功后,浏览器打开如下地址进入one-api页面,默认账号密码为:root 123456
# 创建渠道和令牌
创建渠道 # 大模型类型(通义千问)、APIKey(通义千问申请的真实有效的APIKey)
创建令牌 # 创建OneAPI的APIKey,后续代码中直接调用此APIKey
# Unstructured
非结构化数据预处理工具 (opens new window)提供了开源组件来预处理像 PDF、HTML 和word文档这些文本文档。需要额外安装系统依赖(如libmagic)
# easy-dataset
easy-dataset (opens new window) 可以将领域知识转化为结构化数据集,使数据集构造过程变得简单高效
# zvec 阿里开源向量数据库
阿里开源zvec (opens new window),像SQLite一样轻量的向量数据库,pip装上就能给App做RAG检索,笔记本和手机都能跑
# Milvus
Milvus (opens new window) 是一个开源的、高性能的向量数据库,专为海量向量数据的快速检索而设计
# 核心特性
- 高效向量相似度搜索
# 支持多种向量索引类型,如IVF_FLAT、IVF_PQ、HNSW、ANNOY等,通过近似最近邻算法 ANN 实现毫秒级检索
# 其性能优势在大规模数据集(如 100 万+ 向量)中尤为显著,相比传统数据库可提升搜索效率 10-100 倍
- 混合数据管理能力
# 还支持存储 JSON、字符串等标量数据,提供基于 SQL 的混合查询能力。例如:
# SELECT * FROM collection WHERE vector_similar(emb, [1.2,3.5,...]) AND category = "AI"
- 分布式架构与弹性扩展
# 采用微服务架构,包含以下核心组件:
# Proxy 节点:请求入口与负载均衡
# Meta 节点:元数据管理(如集合schema)
# Data 节点:向量数据存储与索引构建
# Query 节点:查询调度与结果聚合支持横向扩展,可轻松应对 PB 级数据量和高并发查询场景
- 支持各种类型的搜索功能
# ANN 搜索:查找最接近查询向量的前 K 个向量
# 过滤搜索:在指定的过滤条件下执行 ANN 搜索
# 范围搜索:查找查询向量指定半径范围内的向量
# 混合搜索:基于多个向量场进行 ANN 搜索
# 全文搜索:基于 BM25 的全文搜索
# Rerankers:根据附加标准或辅助算法调整搜索结果顺序,完善初始 ANN 搜索结果
# 获取:根据主键检索数据
# 查询使用特定表达式检索数据
# 安装使用
- 安装Milvus向量数据库 下载yml文件 (opens new window),下载完成后,修改文件名成docker-compose.yml
docker-compose up -d # 进入到目录cmd窗口执行
- 安装完成后执行docker compose ps查看是否启动成功
docker compose ps
- 安装Attu可视化工具
# 192.168.100.115为本机的IP,19530为Milvus向量数据库的端口
docker run -p 3000:3000 -e MILVUS_URL=192.168.100.115:19530 zilliz/attu:v2.5
# 出现Attu server started: http://172.17.0.2:3000表示启动成功
# 浏览器访问http://localhost:3000
# 向量字段
FLOAT_VECTOR # 表示向量字段持有32位浮点数列表,通常用于表示反比例
FLOAT16_VECTOR # 表示16位半精度浮点数列表,通常适用于内存或带宽受限的深度学习或基于GPU的计算场景
BFLOAT16_VECTOR # 表示16位浮点数列表,精度有所降低,但指数范围与 Float32 相同
# 这种类型的数据常用于深度学习场景,因为它能在不明显影响精度的情况下减少内存使用量
BINARY_VECTOR # 表示一个0和1的列表。在图像处理和信息检索场景中,它们是表示数据的紧凑特征
SPARSE_FLOAT_VECTOR # 该类型的向量场可保存非零数字及其序列号列表,用于表示稀疏向量嵌入
# 客户端 pymilvus 的使用
pymilvus 是 Milvus 的官方 Python SDK,用于与 Milvus 向量数据库进行交互
- 安装 python接口库
pip install pymilvus
- 连接到 Milvus,使用 connections.connect 方法连接到 Milvus 实例
rom pymilvus import connections
# 连接到本地 Milvus 实例
connections.connect(alias="default", host="localhost", port="19530")
- 创建集合,创建一个新的集合,包括定义集合的名称和字段(例如,向量字段和 id 字段)
from pymilvus import Collection, FieldSchema, CollectionSchema, DataType
# 定义字段
id_field = FieldSchema(name="id", dtype=DataType.INT64, is_primary=True)
vector_field = FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=128)
# 定义集合的 Schema
schema = CollectionSchema(fields=[id_field, vector_field], description="example collection")
# 创建集合
collection = Collection(name="example_collection", schema=schema)
- 插入数据,向集合中插入数据
import numpy as np
# 生成一些示例数据
ids = [i for i in range(10)]
vectors = np.random.random((10, 128)).tolist()
# 插入数据
collection.insert([ids, vectors])
- 构建索引,为向量字段构建索引以加速查询
# 定义索引参数
index_params = {
"metric_type": "L2",
"index_type": "IVF_FLAT",
"params": {
"nlist": 128
}
}
# 创建索引
collection.create_index(field_name="vector", index_params=index_params)
- 执行查询,执行向量检索查询
# 加载集合到内存
collection.load()
# 生成查询向量
query_vectors = np.random.random((1, 128)).tolist()
# 定义搜索参数
search_params = {
"metric_type": "L2",
"params": {
"nprobe": 10
}
}
# 执行搜索
results = collection.search(
data=query_vectors,
anns_field="vector",
param=search_params,
limit=3,
expr=None
)
# 输出结果
for result in results:
for hit in result:
print(f"ID: {hit.id}, Distance: {hit.distance}")
- 管理集合
import numpy as np
# 生成一些示例数据
ids = [i for i in range(10)]
vectors = np.random.random((10, 128)).tolist()
# 插入数据
collection.insert([ids, vectors])
- 管理集合
# 获取集合信息
print(collection.num_entities) # 显示集合中的实体数
# 删除集合
collection.drop()
- 断开连接
connections.disconnect(alias="default")
# AgentScope
gentScope (opens new window) 是以开发者为中心的多智能体平台,能够更轻松地构建基于大模型的多智能体应用程序。
AgentScope
├── src
│ ├── agentscope
│ | ├── agents # 与智能体相关的核心组件和实现。
│ | ├── memory # 智能体记忆相关的结构。
│ | ├── models # 用于集成不同模型API的接口。
│ | ├── pipelines # 基础组件和实现,用于运行工作流。
│ | ├── rpc # Rpc模块,用于智能体分布式部署。
│ | ├── service # 为智能体提供各种功能的服务。
| | ├── web # 基于网页的用户交互界面。
│ | ├── utils # 辅助工具和帮助函数。
│ | ├── prompt.py # 提示工程模块。
│ | ├── message.py # 智能体之间消息传递的定义和实现。
│ | ├── ... ..
│ | ├── ... ..
├── scripts # 用于启动本地模型API的脚本。
├── examples # 不同应用程序的预构建示例。
├── docs # 教程和API参考文档。
├── tests # 单元测试模块,用于持续集成。
├── LICENSE # AgentScope使用的官方许可协议。
└── setup.py # 用于安装的设置脚本。
├── ... ..
└── ... ..
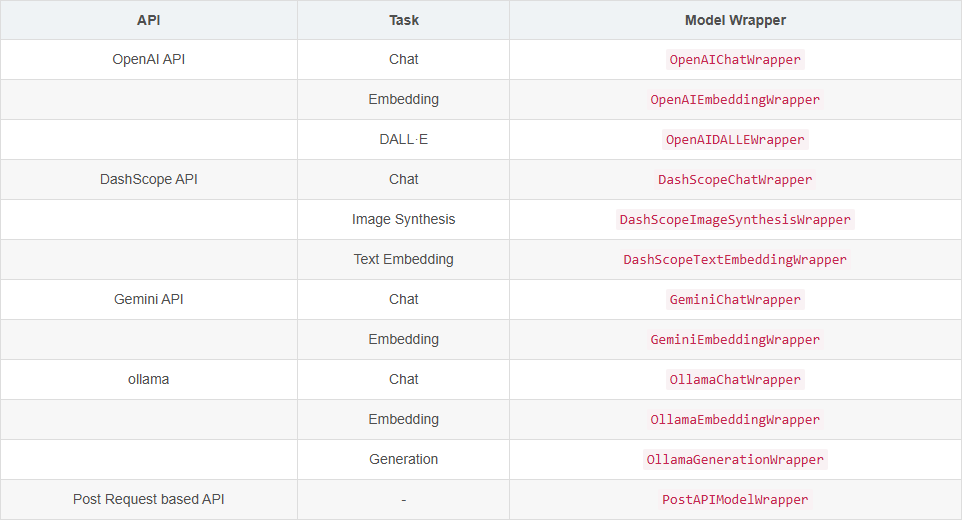
- AgentScope提供了一系列ModelWrapper来支持本地模型服务和第三方模型API
- 支持的服务:
• 网络搜索
• 数据查询
• 数据检索
• 代码执行
• 文件操作
• 文本处理
• 多模态生成
• 维基百科搜索
• TripAdvisor搜索
• 浏览器控制
# 安装使用
# 从GitHub上拉取AgentScope的源代码
git clone https://github.com/modelscope/agentscope.git
cd AgentScope
# 针对本地化的multi-agent应用
pip install -e .
# 为分布式multi-agent应用
pip install -e .[distribute] # 在Mac上使用`pip install -e .\[distribute\]`
注意
[distribute] 选项安装了分布式应用程序所需的额外依赖项。在运行这些命令之前,请激活您的虚拟环境
# skills 的使用
Skill 是一个 Markdown 文件(SKILL.md 名称必须大写),每个Skill是一个文件夹。用于教 Claude 在特定场景下按你的方式做事。
过去我们用提示词(prompt)教 AI 做事,现在用 Agent Skills 可以把提示词 + 资源打包成可复用、可共享的技能包,更高效、更可靠。
# Agent Skills 的关键是渐进式披露,分三层加载:
元数据(Matedata)# 必定加载,类似书的目录
# AI 先读取所有技能的元数据(name 和 description),判断任务是否相关,这些元数据始终在系统提示中
指令(Instruction)# 按需加载,类似书的正文
# 如果相关,AI 自动读取 SKILL.md 的正文内容,获取详细指导
资源(Resource)# 按需加载,类似书的附录
# 只在需要时读取额外文件(如脚本、示例),或通过工具执行脚本
# 标准文件结构
- 一个完整的Skill通常包含:
my-skill/
├── SKILL.md # 核心指令文档(必需)
├── scripts/ # 可执行脚本
│ ├── process.py
│ └── validate.sh
├── reference/ # 参考文档
│ └── api-docs.md
└── assets/ # 资源文件
├── templates/
└── examples/
- SKILL.md示例:
---
name: github-actions-debugger
description: 帮助调试失败的GitHub Actions工作流
---
# GitHub Actions调试专家
## 使用时机
当用户遇到CI/CD失败、构建错误或部署问题时使用
## 工作流程
1. 使用`list_workflow_runs`工具查看最近的运行状态
2. 使用`summarize_job_log_failures`获取失败摘要
3. 分析日志,定位问题根源
4. 提供修复建议和代码示例
## 常见问题检查清单
- [ ] 环境变量和密钥配置
- [ ] 依赖版本兼容性
- [ ] 权限设置
- [ ] 超时配置
# OpenCode 的使用
OpenCode (opens new window)是一个开源的 AI 编程代理。它以多种形式存在,用户可以在终端界面、独立的桌面应用或作为 IDE 扩展来使用它。其核心优势在于开源和模型无关性,为开发者提供了极高的灵活性和可定制性。
# Claude Code
与 OpenCode 不同,它是一个商业化、闭源的产品,需要用户拥有 Claude 订阅才能使用。
# MCP
本地配置值会覆盖远程默认值,配置文件:C:\Users\Administrator.config\opencode\opencode.json
- 本地配置
// 要使用它,可以在提示词中添加 use the mcp_everything tool
{
"$schema": "https://opencode.ai/config.json",
"mcp": {
"my-local-mcp-server": {
"type": "local",
// Or ["bun", "x", "my-mcp-command"]
"command": ["npx", "-y", "my-mcp-command"],
"enabled": true,
"environment": {
"MY_ENV_VAR": "my_env_var_value",
},
},
},
}
- 远程配置
// 要使用它,可以在提示词中添加 use the my-remote-mcp
{
"$schema": "https://opencode.ai/config.json",
"mcp": {
"my-remote-mcp": {
"type": "remote",
"url": "https://my-mcp-server.com",
"enabled": true,
"headers": {
"Authorization": "Bearer MY_API_KEY"
}
}
}
}
# oh-my-opencode 插件
GitHub仓库 (opens new window) 在项目目录下或用户配置目录中创建或编辑 oh-my-opencode.json 文件,配置代理模型
# 是 AI 编程助手开源增强插件,能让 AI (如OpenCode )像真正的开发团队一样高效协作,提升编程体验
# 工具通过集成多种 AI 模型(如 OpenAI、Gemini、Claude 等),为开发者提供强大的编程助手
# 内置多个专家角色(如 oracle、librarian 等),能自动调度任务,支持多模型并行处理
- 安装方式
# 先安装bun
npm install -g bun --registry=https://registry.npmjs.org
# claude、chatgpt、gemini的账号都没有,全写no,由于所有账号都没有,都自动配置成GLM-4.7
npx oh-my-opencode@latest install --no-tui --claude=no --chatgpt=no --gemini=no
- 预置了一支专业的开发团队
| 智能体名称 | 核心模型 (推荐) | 职责描述 |
|---|---|---|
| Sisyphus (Main) | Claude Opus 4.5 | 团队领袖,负责规划、调度和最终代码合并 |
| Oracle | GPT 5.2 | 架构师、Debug 专家。擅长解决“为什么不行”的问题 |
| Librarian | Claude Sonnet 4.5 | 知识渊博的图书馆管理员。负责查阅文档和分析现有实现 |
| Explore | Grok / Gemini 3 Flash | 侦察兵。极速扫描代码库,寻找特定的模式和代码片段 |
| Frontend-UI-UX-Engineer | Gemini 3 Pro | 审美在线的前端工程师。负责 UI 实现、样式调整和交互设计 |
| Document-Writer | Gemini 3 Flash | 技术作家。负责编写 README、API 文档和注释 |
| Multimodal-Looker | Gemini 3 Flash | 视觉专家。能“看懂”你上传的 PDF 需求文档或 UI 设计稿截图 |
- 主要功能
Sisyphus(西西弗斯)主智能体
# 能高效分解和并行处理复杂任务,有多个子代理(如 Oracle、Librarian、Explore 等)
# 支持任务分解(delegate-task)和背景任务(background-task)并行执行,提升任务处理效率
多模型支持与任务分配
# 支持多种模型(如 Claude、GPT、Gemini 等),可根据任务需求动态分配给不同代理,提供丰富的配置选项
# 用户能自定义代理的模型、温度、权限等
代码工具集成
# LSP(Language Server Protocol)工具:通过编程语言的语法和语义,帮助AI快速定位理解代码
# AST 工具:通过代码语法树进行关联搜索
上下文管理与会话管理
# 自动注入项目中的 AGENTS.md 和 README.md 文件内容,为代理提供上下文信息
# 支持会话历史记录和搜索功能,方便代理参考之前的对话内容
多模态支持
# multimodal-looker工具:支持处理多种格式的内容,如 PDF、图像等,通过多模态代理提取信息
扩展性和自定义
# 支持自定义代理、技能和命令,提供丰富的配置文件支持,用户能灵活调整插件的行为满足个性化需求
自动化与辅助功能
# 提供 Ralph Loop 自引用开发循环,能持续执行任务直到完成
# 支持关键词检测(如 ultrawork),激活特定模式以优化任务执行
兼容性与集成
# 兼容 Claude Code 的配置和功能,用户能无缝迁移
# 支持通过 Google Gemini 的 Antigravity OAuth 进行身份验证
预设 MCP
# websearch:使用Exa AI进行实时网络搜索,返回相关内容
# context7:获取代码库或框架的最新官方文档
# grep_app:通过grep.app在公共GitHub仓库中进行超快代码搜索
其他辅助功能
# 提供注释检查、上下文窗口监控、会话恢复等功能,帮助用户优化代码质量和开发流程,提升开发体验
- 应用场景
高效代码开发
# 开发者用 Sisyphus 代理快速生成代码、进行架构设计和代码审查,同时通过背景任务并行处理多个任务
代码库管理和优化
# 工具用 Librarian 和 Explore 代理帮助开发者快速定位问题和优化代码
多模态内容处理
# 在需要处理图像、PDF 或其他多媒体内容时,用多模态代理(如 multimodal-looker)提取信息
前端与后端开发协作
# 分别调用前端工程师代理(如 Gemini 3 Pro)和逻辑设计代理(如 GPT-5.2)协同完成前后端的开发任务
复杂任务自动化
# 通过关键词(如 ultrawork)激活高性能模式,让代理自动分解复杂任务并并行执行,直至任务完成
← 模型介绍