# 环境搭建
# 环境搭建
下载安装 Go (opens new window) Goland下载 (opens new window)
go version # 查看版本
go env # 查看环境
# 修改下载包的位置
go env -w GOMODCACHE=D:\GoLand\pkg
go env GOMODCACHE # 验证修改是否成功
# 包管理工具 go mod
go mod init example.com/yourproject # 初始化项目 会创建一个 go.mod 文件
go get github.com/gin-gonic/gin # 安装 gin 框架最新版本
go get github.com/gin-gonic/gin@v1.9.1 # 安装 gin 框架指定版本
go get -u # 升级所有依赖
go get -u github.com/gin-gonic/gin@v1.8.1 # 升级指定的包
# 配置代理加速
go env -w GOPROXY=https://mirrors.aliyun.com/goproxy/,direct
go env -w GOPROXY=https://goproxy.cn,direct # 七牛云
# 清理缓存
go clean -modcache
# 整理依赖,自动移除 go.mod 中不再需要的依赖,并添加代码中导入但未记录的依赖,保持go.mod的整洁
go mod tidy
# 下载 go.mod 文件中列出的所有依赖到本地缓存,但不会编译代码
go mod download
# 将依赖复制到当前项目的 vendor 下 (本项目)
go mod vendor
# 列出当前模块的所有直接和间接依赖
go list -m all
# 编译成 exe
go build main.go
# 编译时看看程序有没有竞争关系
go build -race main.go
# 查找第三方包:https://pkg.go.dev/
# 一个文件夹下面直接包含的文件只能归属一个 package
# 包名为 main 的包为应用程序的入口包,这种包编译后会得到一个可执行文件
# 而编译不包含 main 包的源代码则不会得到可执行文件
# 这种方式引用包,仅执行包的初始化函数,即使包没有init 初始化函数,也不会引发报错
import _ "包的路径"
# 使用 replace 替换无法直接获取的 package:
replace golang.org/x/crypto => github.com/golang/crypto
# 变量常量
# 定义变量
- 变量声明
var name string
var age int
var isOk bool
var username string
var username = "张三"
var age int = 20
// 一次定义多个变量
var username, sex string
username = "张三"
sex = "男"
// 申明变量的时候赋值
var a, b, c, d = 1, 2, 3, false
注意
- 没用到的变量不要声明
- 代码每一行结束后不用写分号 ;
- 批量声明变量的时候指定类型
var (
a string
b int
c bool
)
a = "张三"
b = 10
c = true
// 批量声明变量并赋值
var (
a string = "张三"
b int = 20
c bool = true
)
var (
IoTDeviceStatusuninstalled = int(0)
IoTDeviceStatusdeleted = int(1)
IoTDeviceStatusinstalled = int(2)
)
- 短变量声明法
func main() {
n := 10
m := 200 // 此处声明局部变量 m
fmt.Println(m, n)
// 使用变量一次声明多个变量,并初始化变量
m1, m2, m3 := 10, 20, 30
// 声明不同类型多个变量
m1, m2, m3 := 10, 20, "30"
// 在多个短变量声明和赋值中,至少有一个新声明的变量出现在左值中
// 即便其他变量名可能是重复声明的,编译器也不会报错
conn, err := net.Dial("tcp", "127.0.0.1:8080")
conn1, err := net.Dial("tcp", "127.0.0.1:8080") // err 可重复申明
fmt.Println(conn)
fmt.Println(conn1)
}
注意
短变量只能用于声明局部变量,不能用于全局变量的声明(:=不能使用在函数外)
- 匿名变量,用一个下划线_表示
func getInfo() (int, string) {
return 10, "张三"
}
func main() {
_, username := getInfo()
fmt.Println(username) // 张三
}
注意
- _多用于占位,表示忽略值
- 匿名变量不占用命名空间,不会分配内存
# 定义常量 const
const pi = 3.1415
const e = 2.7182
// 多个常量也可以一起声明
const (
pi = 3.1415
e = 2.7182
)
// const 同时声明多个常量时,如果省略了值则表示和上面一行的值相同
const (
n1 = 100
n2
n3
)
# 整型类型
- 整型分类
# 有符号的整形:int8、int16、int32、int64
# 无符号的整型:uint8、uint16、uint32、uint64
# 特殊整型
int # 32 位操作系统上就是 int32,64 位操作系统上就是 int64
uint # 32 位操作系统上就是 uint32,64 位操作系统上就是 uint64
uintptr # 无符号整型,用于存放一个指针
# 为了保持文件的结构不会受到不同编译目标平台字节长度的影响,不要使用 int 和 uint
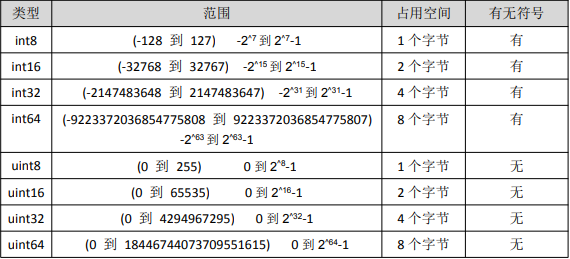
// 不同长度直接的转换
var num1 int8
num1 = 127
num2 := int32(num1)
fmt.Println(unsafe.Sizeof(num2)) // 变量占用的字节数 4;需要import "unsafe"
- 数字字面量语法
v := 0b00101101 // 代表二进制的 101101,相当于十进制的 45
v := 0o377 // 代表八进制的 377,相当于十进制的 255
v := 0x1p-2 // 代表十六进制的 1 除以2²,也就是0.25
// 还允许我们用 _ 来分隔数字
v := 123_456 // 等于 123456
var c int
c = 0xff
fmt.Printf("%x \n", c) // ff
fmt.Printf("%X \n", c) // FF
fmt.Printf("%d \n", c) // 255
# 浮点类型
float32 # 最大范围约为 3.4e38(3.4*10的38次方),可以使用常量定义:math.MaxFloat32
float64 # 最大范围约为 1.8e308(1.8*10的308次方),可以使用一个常量定义:math.MaxFloat64
- Go 语言中64位系统浮点数默认是 float64
package main
import (
"fmt"
"math"
"unsafe"
)
func main() {
fmt.Printf("%f\n", math.Pi) // 默认保留 6 位小数
fmt.Printf("%.2f\n", math.Pi) // 保留 2 位小数
fmt.Printf("类型:%T\n", math.Pi) // float64
fmt.Printf("大小:%d 个字节\n", unsafe.Sizeof(math.Pi)) // 8个字节
// 转换
a := 10
b := float32(a) // 10.0
c := 3.14 // 默认被推导为 float64 类型
d := float64(c) // 3.14
e := int(c) // 3
}
- Golang 中 float 精度丢失问题
m1 := 8.2
m2 := 3.8
fmt.Println(m1 - m2) // 期望是 4.4,结果打印出了 4.399999999999999
// 使用第三方包来解决精度损失问题 github.com/shopspring/decimal
a := decimal.NewFromInt(3) // 3
b := decimal.NewFromFloat(1) // 1
price, err := decimal.NewFromString("136.02")
# 布尔类型
var b bool // 布尔类型变量的默认值为 false
fmt.Println(b, "占用字节:", unsafe.Sizeof(b)) // 1个字节
# 字符串类型
# 字符串的内部实现使用 UTF-8 编码
# 字符串转义符:\' 单引号 \" 双引号 \\ 反斜杠
# 多行字符串 a := `第一行
第二行
`
- 字符串的常用操作
len(str) // 求长度
+或 fmt.Sprintf // 拼接字符串 fmt.Sprintf("%s:%d", host, port)
strings.Split // 分割
strings.contains // 判断是否包含
strings.HasPrefix/strings.HasSuffix // 前缀/后缀判断
strings.Index()/strings.LastIndex() // 子串出现的位置
strings.Join(a[]string, sep string) // join 操作
- byte 和 rune 类型
# 字符串是字节的定长数组,byte和rune都是字符类型,若多个字符放在一起,就组成了字符串
byte
# 或者叫 uint8类型,代表了ASCIl码的一个字符
rune
# 等价于 int32,1个中文占3个字节,代表一个UTF-8字符
# 当需要处理中文、日文或者其他复合字符时,则需要用到rune类型
# UTF-8 是Unicode的一种具体的实现方案
a := 'a' // 用单引号(’)包裹起来
b := '国'
//当我们直接输出 byte(字符)的时候输出的是这个字符对应的码值
fmt.Println(a) // 97
fmt.Println(b) // 22269
//如果我们要输出这个字符,需要格式化输出
fmt.Printf("%c--%c", a, b) //%c 相应 Unicode 码点所表示的字符
s := "hello 我的码神""
sLength := utf8.RuneCountInString(s) // 10 获取中文的长度
sSize := len(s) // 18 获取字节数
- 拼接字符串除了“+”还有以下方式
var stringBuilder bytes.Buffer
stringBuilder.WriteString(s1)
stringBuilder.WriteString(s2)
fmt.Printf(format: "拼后的字符串:%s",stringBuilder.String())
- 遍历一个包含中文的字符串
// UTF8 编码下一个中文汉字由 3 个字节组成,所以我们不能简单的按照字节去遍历一个包含中文的字符串
s := "hello 张三"
for i := 0; i < len(s); i++ { // byte
fmt.Printf("%v(%c) ", s[i], s[i])
// 104(h) 101(e) 108(l) 108(l) 111(o) 32( ) 229(å) 188(¼) 160( ) 228(ä) 184(¸) 137()
}
for _, r := range s { // rune Unicode 类型
fmt.Printf("%v(%c) ", r, r)
// 104(h) 101(e) 108(l) 108(l) 111(o) 32( ) 24352(张) 19977(三)
}
- 修改字符串中的字符
s1 := "big"
// 强制类型转换
byteS1 := []byte(s1)
byteS1[0] = 'p'
fmt.Println(string(byteS1)) // pig
s2 := "白萝卜"
runeS2 := []rune(s2)
runeS2[0] = '红'
fmt.Println(string(runeS2)) // 红萝卜
# 基本数据类型转换
- 数值类型之间的相互转换
// 要转换成相同类型才能运行
var a int8 = 20
var b int16 = 40
var c = int16(a) + b
// 建议从低位转换成高位
var a float32 = 3.2
var b int16 = 6
var c = a + float32(b)
// 切片转字符串
addressIds := make([]string, 0)
strings.Join(addressIds, ",")
- 其他类型转换成 String 类型
var i int = 20
var f float64 = 12.456
var t bool = true
var b byte = 'a'
var strs string
strs = fmt.Sprintf("%d", i) // int转换
strs = fmt.Sprintf("%f", f) // float转换
strs = fmt.Sprintf("%t", t) // bool转换
strs = fmt.Sprintf("%c", b) // byte转换
- 使用 strconv 包里面的几种转换方法转换成 String 类型
// 1、int 转换成 string
var num1 int = 20
// s1 := strconv.Itoa(num1)
// 或者
s1 := strconv.FormatInt(int64(num1), 10)
// 2、int64 转 string
var num3 int64 = 20
// 第二个参数为 进制
s4 := strconv.FormatInt(num3, 10)
// 3、float 转 string
var num2 float64 = 20.113123
/* 参数 1:要转换的值
参数 2:格式化类型
'f'(-ddd.dddd)、
'b'(-ddddp±ddd,指数为二进制)、
'e'(-d.dddde±dd,十进制指数)、
'E'(-d.ddddE±dd,十进制指数)、
'g'(指数很大时用'e'格式,否则'f'格式)、
'G'(指数很大时用'E'格式,否则'f'格式)。
参数 3: 保留的小数点 -1(不对小数点格式化)
参数 4:格式化的类型
*/
s2 := strconv.FormatFloat(num2, 'f', 2, 64)
// 4、bool 转 string
s3 := strconv.FormatBool(true)
- String 类型转换成数值类型
// string 类型转换成 int 类型
var s = "1234"
i64, _ := strconv.ParseInt(s, 10, 64)
// string 类型转换成 float 类型
str := "3.1415926535"
v1, _ := strconv.ParseFloat(str, 32)
v2, _ := strconv.ParseFloat(str, 64)
// string 转字符(rune)类型
ss := "hello 张三"
for _, r := range ss {
fmt.Printf("%v(%c) ", r, r)
}
- 使用 cast 进行类型转换
import (
"fmt"
"github.com/spf13/cast"
)
func main() {
// 转换为 string
fmt.Println(cast.ToString(100)) // 输出: "100"
fmt.Println(cast.ToString(true)) // 输出: "true"
fmt.Println(cast.ToString(nil)) // 输出: "" (空字符串)
fmt.Println(cast.ToString(3.14)) // 输出: "3.14"
// 转换为 int
fmt.Println(cast.ToInt("123")) // 输出: 123
fmt.Println(cast.ToInt(10.5)) // 输出: 10
fmt.Println(cast.ToInt(false)) // 输出: 0 (转换失败,返回零值)
fmt.Println(cast.ToInt("invalid")) // 输出: 0 (转换失败,返回零值)
// 转换为 bool
fmt.Println(cast.ToBool("true")) // 输出: true
fmt.Println(cast.ToBool(1)) // 输出: true
fmt.Println(cast.ToBool("false")) // 输出: false
fmt.Println(cast.ToBool(0)) // 输出: false
fmt.Println(cast.ToBool("anything")) // 输出: false (转换失败,返回零值)
// 转换为 float64
fmt.Println(cast.ToFloat64("3.14")) // 输出: 3.14
fmt.Println(cast.ToFloat64(123)) // 输出: 123.0
fmt.Println(cast.ToFloat64("abc")) // 输出: 0.0 (转换失败,返回零值)
// 带错误处理的转换,可以区分转换失败和零值
val, err := cast.ToIntE("123")
if err != nil {
fmt.Println("转换失败:", err)
} else {
fmt.Println("转换成功:", val) // 输出: 转换成功: 123
}
val, err = cast.ToIntE("invalid")
if err != nil {
fmt.Println("转换失败:", err) // 输出: 转换失败: ...
}
}
# 运算符
// 在 golang 中,++ 和 -- 只能独立使用
var i int = 8
var a int
a = i++ //错误,i++只能独立使用
a = i-- //错误, i--只能独立使用
// 没有前++ --
var i int = 1
++i // 错误,在 golang 没有 前++
--i // 错误,在 golang 没有 前--
// 正确写法
var i int = 1
i++
- 位运算符
/* & 两位均为 1 才为 1
| 两位有一个为 1 就为 1
^ 相异或 两位不一样则为 1
<< 左移 n 位就是乘以 2 的 n 次方。a<<b 把 a 的各二进位全部左移b位,高位丢弃,低位补0
>> 右移 n 位就是除以 2 的 n 次方。
*/
var a int = 5 // 101
var b int = 2 // 010
fmt.Println("a&b=", a&b) // 000 值 0
fmt.Println("a|b=", a|b) // 111 值 7
fmt.Println("a^b=", a^b) // 111 值 7
fmt.Println("5>>2=", a>>b) // 5 右移 2 位 1 5/2的2次方
fmt.Println("5<<2=", a<<b) // 5 左移 2 位 10100 5*2的2次方
fmt.Println("5<<1=", 5<<1) // 1010
fmt.Println("5>>1=", 5>>1) // 2
fmt.Println("7>>2=", 7>>2) // 1
# 流程控制
- if 条件判断特殊写法
// 在 if 表达式之前添加一个执行语句,再根据变量值进行判断
// 这里的 score 是局部作用域
if score := 56; score >= 90 {
fmt.Println("A")
} else if score > 75 {
fmt.Println("B")
} else {
fmt.Println("C")
}
注意
go 语言中没有三目运算
- for(循环结构)
for i := 0; i < 10; i++ {
fmt.Println(i)
}
// for 循环的初始语句可以被忽略,但是初始语句后的分号必须要写
i := 0
for ; i < 10; i++ {
fmt.Println(i)
}
// for 循环的初始语句和结束语句都可以省略 类似while
i := 0
for i < 10 {
fmt.Println(i)
i++
}
// for 无限循环
k := 1
for { // 这里也等价 for ; ;
if k <= 10 {
fmt.Println("ok~~", k)
} else {
break //break 就是跳出这个 for 循环
}
k++
}
注意
Go 语言中是没有 while 语句的,我们可以通过 for 代替
- for range(键值循环)
# 数组、切片、字符串返回索引和值
# map 返回键和值
# 通道(channel)只返回通道内的值
str1 := "ab 上海"
for index, val := range str1 {
fmt.Printf("index=%d, val=%c", index, val)
// index=0, val=a index=1, val=b index=2, val= index=3, val=上 index=6, val=海
}
str2 := "ab 上海"
for _, val := range str2 {
fmt.Printf("val=%c", val)
// val=a val=b val= val=上 val=海
}
- switch case
// 每个 case 语句中可以不写 break,不加 break 也不会出现穿透的现象
extname := ".a"
switch extname {
// switch n := 7; n { 这种写法注意作用域
case ".html":
fmt.Println("text/html")
case ".css":
fmt.Println("text/css")
case ".js":
fmt.Println("text/javascript")
default:
fmt.Println("格式错误")
}
// 一个分支可以有多个值,多个 case 值中间使用英文逗号分隔
n := 2
switch n {
case 1, 3, 5, 7, 9:
fmt.Println("奇数")
case 2, 4, 6, 8:
fmt.Println("偶数")
default:
fmt.Println(n)
}
- switch 的穿透 fallthrought,可以执行满足条件的 case 的下一个 case
func switchDemo5() {
s := "a"
switch {
case s == "a":
fmt.Println("a")
fallthrough
case s == "b":
fmt.Println("b")
case s == "c":
fmt.Println("c")
default:
fmt.Println("...")
}
} // 输出:a b
- break(跳出循环):在多重循环中,可以用标号 label 标出想 break 的循环
// 执行 break lable2,直接跳出由标签 lable2 标记的外层 for 循环,整个程序结束
func main() {
lable2:
for i := 0; i < 2; i++ {
for j := 0; j < 10; j++ {
if j == 2 {
break lable2 // 和上面定义的lable2一致
}
fmt.Println("i j 的值", i, "-", j)
}
}
}
// 输出:
// i j 的值 0 - 0
// i j 的值 0 - 1
- goto(跳转到指定标签)
func main() {
var n int = 30
fmt.Println("ok1")
if n > 20 {
goto label1
}
fmt.Println("ok2")
fmt.Println("ok3")
fmt.Println("ok4")
label1:
fmt.Println("ok5")
fmt.Println("ok6")
fmt.Println("ok7")
// ok1
// ok5
// ok6
// ok7
}
# 数组 Array
- 数组的初始化
// 方法一:定义长度
var testArray [3]int // 数组会初始化为int 类型的零值 [0 0 0]
var numArray = [3]int{1, 2} // 最后一位是0 [1 2 0]
var cityArray = [3]string{"北京", "上海"} // 最后一位是空值 [北京 上海 ]
// 方法二:让编译器根据初始值的个数自行推断数组的长度
var numArray = [...]int{1, 2}
var cityArray = [...]string{"北京", "上海"}
// 方法三:指定索引值
a := [...]int{1: 1, 3: 5}
b := [...]string{1: "北京", 3: "上海"}
fmt.Println(a) // [0 1 0 5] 未显式赋值的索引(0 和 2)会默认填充为0
fmt.Printf("type of a:%T\n", a) // type of a:[4]int 长度是4
fmt.Println(b) // [ 北京 上海]
注意
- var a [5]int, 数组的长度必须是常量,并且长度是数组类型的一部分
- 一旦定义,长度不能变。 [5]int 和[4]int 是不同的类型。a := [4]int b := [5]int a!=b
- 数组的遍历
var a = [...]string{"北京", "上海", "深圳"}
// 方法 1:for 循环遍历
for i := 0; i < len(a); i++ {
fmt.Println(a[i])
}
// 方法 2:for range 遍历
for index, value := range a {
fmt.Println(index, value)
}
- 数组是值类型
a := [3]int{10, 20, 30}
b := a
a[0] = 100
fmt.Println(a) // [100 20 30]
fmt.Println(b) // [10 20 30]
注意
- 基本数据类型 和 数组都是值类型
- 值类型:改变副本或原对象的值,不会影响所有引用
- 引用类型:改变副本或原对象的值,会影响所有引用
- 多维数组
aa := [3][2]string{{"北京", "上海"}, {"广州", "深圳"}, {"成都", "重庆"}}
fmt.Println(aa) // [[北京 上海] [广州 深圳] [成都 重庆]]
fmt.Println(aa[2][1]) // 支持索引取值:重庆
# 切片 Slice
# 因为数组的长度是固定的并且数组长度属于类型的一部分,所以数组有很多的局限性
# 切片(Slice)是一个拥有相同类型元素的可变长度的序列
# 切片是一个引用类型,它的内部结构包含地址、长度和容量
- 切片的声明初始化
var a []string // nil 切片
var b = []int{} // 空切片,底层数组已分配(但长度0)
var c = []bool{false, true} // 布尔切片
var d = []int{1:100, 2:200} // 整形切片 [0 100 200]
// 数组切片,每个元素是一个包含 2 个 string 的数组
var e = [][2]string{
{"a", "100"},
{"b", "200"},
{"c", "300"},
}
// 结构体切片
var f = []Person{
{Name: "Alice", Age: 30},
{Name: "Bob", Age: 25},
}
fmt.Println(a) // []
fmt.Println(b) // []
fmt.Println(c) // [false true]
fmt.Println(a == nil) // true
fmt.Println(b == nil) // false
fmt.Println(c == nil) // false
// make: 用于 slice,map,和 channel 的初始化
e := make([]int, 2, 10) // 切片的元素类型,数量,容量
// make()函数构造切片时只能指定长度和容量,不能直接指定元素的值
e := make([]int, 2, 10){100, 200} // 错误
- 关于 nil 的认识
# 当你声明了一个变量 , 但却还并没有赋值时 , golang 中会自动给你的变量赋值一个默认值
bool -> false
numbers -> 0
string-> ""
pointers -> nil
slices -> nil
maps -> nil
channels -> nil
functions -> nil
interfaces -> nil
注意
数组(Array)、结构体(struct)没有“结构体级别的默认值”,而是其内部的每个字段都有各自类型的“零值”
- 基于数组定义切片
a := [5]int{55, 56, 57, 58, 59}
b := a[1:4] // 左闭右开
c := a[:] // 数组中所有切片
fmt.Println(b) // [56 57 58]
fmt.Printf("type of b:%T\n", b) // type of b:[]int
- 切片再切片
a := [...]string{"北京", "上海", "广州", "深圳", "成都", "重庆"}
fmt.Printf("a:%v 类型:%T 长度:%d 容量:%d\n", a, a, len(a), cap(a))
// a:[北京 上海 广州 深圳 成都 重庆] 类型:[6]string 长度:6 容量:6
b := a[1:3]
fmt.Printf("b:%v 类型:%T 长度:%d 容量:%d\n", b, b, len(b), cap(b))
// b:[上海 广州] 类型:[]string 长度:2 容量:5
c := b[1:5]
fmt.Printf("c:%v 类型:%T 长度:%d 容量:%d\n", c, c, len(c), cap(c))
// c:[广州 深圳 成都 重庆] 类型:[]string 长度:4 容量:4
注意
- 切片的容量是从它的第一个元素开始数,到其底层数组元素末尾的个数
- 对切片进行再切片时,索引不能超过原数组的容量,否则会出现索引越界的错误
- 切片不能直接比较
// 要判断一个切片是否是空的,要是用 len(s) == 0 来判断,不应该使用s == nil 来判断
var s1 []int // len(s1)=0 cap(s1)=0 s1==nil
s2 := []int{} // len(s2)=0 cap(s2)=0 s2!=nil
s3 := make([]int, 0) // len(s3)=0 cap(s3)=0 s3!=nil
// s2和s3的两种定义方式在绝大多数场景下行为完全一致
- append()方法为切片添加元素
var citySlice []string
// 追加一个元素
citySlice = append(citySlice, "北京")
fmt.Println(citySlice) // [北京]
// 追加多个元素
citySlice = append(citySlice, "上海", "广州", "深圳")
fmt.Println(citySlice) // [北京 上海 广州 深圳]
// 追加切片
a := []string{"成都", "重庆"}
citySlice = append(citySlice, a...)
fmt.Println(citySlice) // [北京 上海 广州 深圳 成都 重庆]
- 从切片中删除元素
// Go语言中并没有删除切片元素的专用方法,我们可以使用切片本身的特性来删除元素
func main(){
//从切片中删除元素
a :=[]int{30, 31, 32, 33, 34, 35, 36, 37} // 要删除索引为2的元素
a = append(a[:2], a[3:]...)
fmt.Println(a) // [30 31 33 34 35 36 37]
}
- 使用 copy()函数复制切片
a := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
c := make([]int, 5, 5)
copy(c, a) // 使用 copy()函数将切片 a 中的元素复制到切片c
fmt.Println(a) // [1 2 3 4 5 6 7 8 9 10]
fmt.Println(c) // [1 2 3 4 5]
c[0] = 1000 // 改变副本或原对象的值,不会影响所有引用
fmt.Println(a) // [1 2 3 4 5 6 7 8 9 10]
fmt.Println(c) // [1000 2 3 4 5]
- 内置 Sort 包对切片进行排序
intList := []int{2, 4, 3, 5, 7, 6, 9, 8, 1, 0}
float8List := []float64{4.2, 5.9, 12.4, 10.2, 50.7, 99.9, 31.4, 27.81828, 3.14}
stringList := []string{"a", "c", "b", "z", "x", "w", "y", "d", "f", "i"}
sort.Ints(intList) // 对 int 进行升序排序
sort.Float64s(float8List) // 对 float 进行升序排序
sort.Strings(stringList) // 对 string 进行升序排序
sort.Sort(sort.Reverse(sort.IntSlice(intList))) // 对 int 进行降序排序
sort.Sort(sort.Reverse(sort.Float64Slice(float8List))) // 对 float 进行降序排序
sort.Sort(sort.Reverse(sort.StringSlice(stringList))) // 对 string 进行降序排序
# 映射 map
- map 的声明初始化
// 初始化方式一
scoreMap := make(map[string]int, 8)
scoreMap["张三"] = 90
scoreMap["小明"] = 100
// 初始化方式二,可以不用 make
userInfo := map[string]string{"username": "sylone", "password": "123456"}
func main() {
r := rand.New(rand.NewSource(time.Now().UnixNano())) // 创建随机数实例
var scoreMap = make(map[string]int, 200)
for i := 0; i < 100; i++ {
key := fmt.Sprintf("stu%02d", i) //生成 stu 开头的字符串 stu01 stu02
value := r.Intn(100) //生成 0~99 的随机整数
scoreMap[key] = value
}
fmt.Println(scoreMap)
}
- 判断某个键是否存在
//如果 key 存在 ok 为 true,v 为对应的值;不存在 ok 为 false,v 为该类型的默认值
v, ok := userInfo["username"]
if ok {
fmt.Println(v) // 输出: sylone
} else {
fmt.Println(v) // 输出:
}
- map 的遍历
for k, v := range userInfo {
fmt.Println(k, v)
}
for k := range userInfo {
fmt.Println(k, userInfo[k])
}
- 使用 delete()函数删除键值对
delete(scoreMap, "小明") // 将 小明:100 从 map 中删除
- map 类型的切片
var mapSlice = make([]map[string]string, 3)
// 对切片中的 map 元素进行初始化,
mapSlice[0] = make(map[string]string, 10) // 需要先申请容量
mapSlice[0]["name"] = "小王子"
mapSlice[0]["password"] = "123456"
fmt.Println(mapSlice) // [map[name:小王子 password:123456] map[] map[]]
- 值为切片类型的 map
var sliceMap = make(map[string][]string, 3)
key := "中国"
value := make([]string, 0, 2) // 需要先申请容量
value = append(value, "北京", "上海")
sliceMap[key] = value
fmt.Println(sliceMap) // map[中国:[北京 上海]]
# sync.Map 线程安全的map
# 无须初始化,直接声明即可
# 不能使用map的方式进行取值和设置等操作,而是使用Store表示存储,Load表示获取,Delete表示删除
# 使用Range配合一个回调函数进行遍历操作,通过回调函数返回内部遍历出来的值
# Range参数中回调函数的返回值在需要继续迭代遍历时,返回true,终止迭代遍历时,返回false
var scene sync.Map
// 将键值对保存到sync.Map
//sync.Map 将键和值以 interface{}类型进行保存。
scene.Store("greece", 97)
scene.Store("london", 100)
scene.Store("egypt", 200)
//从sync.Map中根据键取值
value, ok := scene.Load("london")
// 根据键删除对应的键值对
scene.Delete("london")
// 遍历所有sync.Map中的键值对
//遍历需要提供一个匿名函数,参数为k、v,类型为interface{}
scene.Range(func(k, v interface{}) bool {
fmt.Println("iterate:", k, v)
return true
})
注意
sync.Map为了保证并发安全有一些性能损失,因此在非并发情况下,使用 map 相比使用 sync.Map会有更好的性能
# 函数 func
- 函数的定义
// 函数的参数和返回值都是可选的
func intSum(x int, y int) int {
return x + y
}
在默认情况下,Go语言使用的是值传递,即在调用过程中不会影响到实际参数
- 无论是值传递,还是引用传递,传递给函数的都是变量的副本,不过值传递是值的拷贝。引用传递是地址的拷贝,地址拷贝更高效。值拷贝取决于拷贝的对象大小,对象越大性能越低。
- map、slice、chan、指针、interface默认以引用的方式传递。
- 函数参数
// 类型简写
func intSum(x, y int) {
return x + y
}
// 可变参数
func intSum2(x ...int) {
fmt.Println(x) // x 是一个切片
}
s := []int{1, 2, 3}
res := intSum2(s...) // slice... 展开slice
// 固定参数搭配可变参数使用时,可变参数要放在固定参数的后面
func intSum3(x int, y ...int) {
fmt.Println(x, y)
}
- 函数返回值
func calc(x, y int) (int, int) {
sum := x + y
sub := x - y
return sum, sub
}
// 可以给返回值命名,并在函数体中直接使用这些变量,最后通过return 关键字返回
func calc(x, y int) (n int, m map[string]int) {
// 如果不使用 make,m 的默认值是 nil,写入数据会引发程序崩溃
m = make(map[string]int)
m["a"] = 10
n = x + y
return
}
- 定义函数类型
// 凡是满足这个条件的函数都是 calculation 类型的函数
type calculation func(int, int) int
// add 和 sub 都能赋值给 calculation 类型的变量
func add(x, y int) int {
return x + y
}
func sub(x, y int) int {
return x - y
}
func main() {
var c calculation // 声明一个 calculation 类型的变量
c = add // 把 add 赋值给 c
fmt.Printf("type of c:%T\n", c) // type of c:main.calculation
fmt.Println(c(1, 2)) // 像调用 add 一样调用 3
f := add // 将函数 add 赋值给变量 f1
fmt.Printf("type of f:%T\n", f) // type of f:func(int, int) int
fmt.Println(f(10, 20)) // 像调用 add 一样调用 f30
}
- 函数作为参数
func add(x, y int) int {
return x + y
}
func calc(x, y int, op func(int, int) int) int {
return op(x, y)
}
func main() {
// add 作为参数时,传递的是函数本身,而不是函数的调用结果
ret2 := calc(10, 20, add)
fmt.Println(ret2) // 30
}
- 函数作为返回值
func add(x, y int) int {
return x + y
}
func sub(x, y int) int {
return x - y
}
func do(s string) func(int, int) int {
switch s {
case "+":
return add
case "-":
return sub
default:
return nil
}
}
func main() {
var a = do("+")
fmt.Println(a(10, 20))
}
- 匿名函数
// 将匿名函数保存到变量
add := func(x, y int) int {
return x + y
}
fmt.Println(add(10, 20))
// 匿名自执行函数:匿名函数定义完加 () 直接执行
func(x, y int) int{
return x + y
}(10, 20)
注意
函数内部不能再定义其他函数,但是可以定义匿名函数
func main() {
func(x, y int) {
return x + y
}(2,3)
}
- defer 语句
// defer 语句会将其后面跟随的语句进行延迟处理
// 先被defer 的语句最后被执行,最后被 defer 的语句,最先被执行
fmt.Println("start")
defer fmt.Println(1)
defer fmt.Println(2)
defer fmt.Println(3)
fmt.Println("end")
// 输出 start end 3 2 1
func f1() int {
x := 5
defer func() {
// 再修改x,无意义
x++
}()
// 先将返回值赋值为x
return x
}
func f2() (x int) {
defer func() {
// 再修改x后返回
x++
}()
// 先将x赋值为5
return 5
}
func f3() (y int) {
x := 5
defer func() {
// 再修改x,无意义
x++
}()
// 先将返回值x赋值给y
return x
}
func f4() (x int) {
// 此处的x和上面的x不是一个
defer func(x int) {
x++
}(x)
return 5
}
func main() {
fmt.Println(f1()) // 5
fmt.Println(f2()) // 6
fmt.Println(f3()) // 5
fmt.Println(f4()) // 5
}
- 内置函数 panic/recover
// Go 语言中目前(Go1.12)是没有异常机制,但是使用 panic/recover 模式来处理错误
// defer 一定要在可能引发 panic 的语句之前定义
// recover()必须搭配 defer 使用
func safeFunction() {
defer func() {
if r := recover(); r != nil {
fmt.Println("捕获到 panic:", r)
fmt.Println("程序已恢复,继续执行")
}
}()
fmt.Println("执行安全函数")
panic("意外错误") // 触发 panic,或者自动触发 panic 10/0
fmt.Println("这行不会执行") // 不会执行!
}
func main() {
fmt.Println("main 开始")
safeFunction()
fmt.Println("main 继续执行") // 会执行!
}
// 输出
// main 开始
// 执行安全函数
// 捕获到 panic: 意外错误
// 程序已恢复,继续执行
// main 继续执行
- 闭包
# 闭包可以理解成 "函数里面嵌套一个函数,最后返回里面的函数"
# 在本质上,闭包是将函数内部和函数外部连接起来的桥梁
# 闭包中的变量是局部变量,但可以常驻内存,不污染全局
# 由于闭包里作用域返回的局部变量资源不会被立刻销毁回收,所以可能会占用更多的内存
# 过度使用闭包会导致性能下降,建议在非常有必要的时候才使用闭包
func adder() func(int) int {
var x int
return func(y int) int {
x += y
return x
}
}
func main() {
// 变量 f 是一个函数并且它引用了其外部作用域中的 x 变量,此时 f 就是一个闭包
var f = adder()
fmt.Println(f(10)) //10
// 在f 的生命周期内,变量 x 一直有效
fmt.Println(f(20)) //30
fmt.Println(f(30)) //60
f1 := adder()
fmt.Println(f1(40)) //40
fmt.Println(f1(50)) //90
}
- init() 初始化函数
// Go 初始化顺序:包级变量声明初始化(apis),然后init() 函数执行
var apis = make([]string, 0)
// init() 函数没有参数也没有返回值。在程序运行时自动被调用执行,不能在代码中主动调用它
func init() {
fmt.Println("main init...")
}
- 构造函数
// 如果一个函数用于创建并初始化某个类型的实例,它的名字通常以 New 开头
// 通常构造函数会返回指针,因为这样可以直接修改实例的字段,并且避免拷贝大结构体
// Person 结构体,首字母大写表示公开
type Person struct {
Name string
Age int
}
// NewPerson 是 Person 的构造函数
// 按照约定,函数名以 New 开头,返回 Person 的指针
func NewPerson(name string, age int) *Person {
// 可以在这里进行初始化、校验等逻辑
if age < 0 {
age = 0
}
return &Person{
Name: name,
Age: age,
}
}
# 指针 pointer
指针是一种特殊的变量,它存储的数据不是一个普通的值,而是另一个变量的内存地址
- 指针地址、指针类型、指针取值
# &:取地址操作符,用于获取一个变量的内存地址
# *:解引用操作符,用于从指针变量中取出它指向的值;同时也用于在参数中声明指针类型
# 指针类型:int、float、bool、string、array、struct都有对应的指针类型,如*int、*int64、*string
# 使用指针类型传递参数的主要好处确实可以理解为:
# 允许函数内部直接修改原始变量,而不是操作它的副本。
# 这是因为 Go 的所有传参都是值传递,但指针本身也是一个值(地址)
# 传递指针的副本后,函数内通过该地址操作的是同一块内存数据
a := 10
b := &a // 指针地址,b 是 a 的指针
fmt.Printf("b: %v, type of b:%T\n", b, b) // 输出: b: 0xc0000140a8, type of b:*int
c := *b // 指针取值
fmt.Printf("c: %v, type of c:%T\n", c, c) // 输出: c: 10, type of c:int
func modify1(x int) {
x = 100
}
func modify2(x *int) {
*x = 100
}
func main() {
a := 10
modify1(a)
fmt.Println(a) // 10
modify2(&a) // 改变了内存地址
fmt.Println(a) // 100
}
- new()函数可以创建一个对应类型的指针,创建过程会分配内存,被创建的指针指向默认值
// 使用 new 关键字对类型(包括结构体、整型、浮点数、字符串等)进行实例化后会形成该类型的指针类型
p := new(int) // 创建 int 指针
fmt.Println(*p) // 0(零值)
*p = 100
fmt.Println(*p) // 100
var b = *int
*b = 100 // 错误
// 创建结构体指针
type Person struct {
Name string
Age int
}
personPtr := new(Person)
fmt.Println(personPtr.Name) // ""(空值)
fmt.Println(personPtr.Age) // 0
// 修改字段
personPtr.Name = "Alice"
personPtr.Age = 30
fmt.Println(personPtr) // &{Alice 30}
# 结构体 struct
Golang 中没有“类”的概念,Golang 中的结构体和其他语言中的类有点相似
- type 关键词自定义类型和类型别名
// 自定义类型(新类型):需要类型安全、自定义方法
type newInt int
// 定义类型别名,不改变类型的行为
type myInt = int
// 二者的区别
func main() {
var a newInt
var b myInt
fmt.Printf("type of a:%T\n", a) // type of a:main.newInt
fmt.Printf("type of b:%T\n", b) // type of b:int
var a newInt = 10
var b int = 20
// a = b // 编译错误:cannot use b (type int) as type newInt
a = newInt(b) // 需要显式转换
fmt.Println(a.Double()) // 20
var a myInt = 10
var b int = 20
a = b // 可以直接赋值,完全等价
}
- 结构体的定义
type person struct {
name string
city string
age int8
}
// 同样类型的字段也可以写在一行
type person struct {
name, city string
age int8
}
注意
- 结构体首字母可以大写也可以小写
- 大写表示这个结构体是公有的,在其他的包里面可以使用
- 小写表示这个结构体是私有的,只有这个包里面才能使用
- 匿名结构体
// 匿名结构体没有类型名称,无须通过type关键字定义
// 在声明变量的同时定义其结构
var user struct {
Name string
Age int
}
user.Name = "Alice"
user.Age = 30
// 省略名称,在声明变量的同时赋值
point := &struct {
X, Y int
}{
X: 10,
Y: 20,
}
- 结构体实例化
// 第一种方法
var p1 person
p1.name = "张三"
p1.city = "北京"
p1.age = 18
// 第二种方法:键值对初始化
p4 := person{
name: "zhangsan",
city: "北京",
age: 18, // 最后一个属性的,要加上
}
fmt.printf("值:%#v 类型:%T", person, person) // %#v
// 输出:值:main.Person{name: "zhangsan", city:"北京", age:18)
// 第三种方法
// 使用 new 关键字对结构体进行实例化,得到的是结构体的地址
var p2 = new(person)
p2.name = "张三" // 其实在底层是(*p2).name = "张三"
p2.age = 20
p2.city = "北京"
fmt.Printf("%T\n", p2) // *main.person
// 第四种方法
// 使用&对结构体进行取地址操作相当于对该结构体类型进行了一次 new 实例化操作
p3 := &person{}
p3.name = "zhangsan"
p3.age = 30
p3.city = "深圳"
(*p3).age = 40 //这样也是可以的
注意
- 以上四种方式中如果p11 := p1,修改 p11 不影响 p1。p22 := p2 修改任意一个都会影响另一个
- 结构体本身是值类型,但是 p2 存储的是该结构体的内存地址
- 结构体方法
# 方法的定义格式如下:
func (接收者变量 接收者类型) 方法名(参数列表) (返回参数) {
函数体
}
# 接收者变量:官方建议使用接收者类型名的第一个小写字母 Person p
# 接收者类型:接收者类型和参数类似,可以是指针类型和值类型
# 方法名、参数列表、返回参数:具体格式与函数定义相同
// 值类型接受者
// 值类型接收者的方法中可以获取接收者的成员值,但修改操作只是针对副本,无法修改接收者变量本身
func (p person) printInfo() {
fmt.Printf("姓名:%v 年龄:%v", p.name, p.age)
}
// 以下方法是错误的,无法修改值类型的值
func (p person) setInfo(name string, age int) {
p.name = name
p.age = age
}
// 指针类型接收者
// 修改接收者指针的任意成员变量,在方法结束后,修改都是有效的
func (p *Person) setInfo(name string, age int) {
p.name = name
p.age = age
}
func main() {
p1 := person{
name: "小王子", age: 25, city: "北京",
}
p1.printInfo()
p1.setInfo("张三", 20)
p1.printInfo()
}
- 给任意类型添加方法
// 接收者的类型可以是任何类型,不仅仅是结构体,任何类型都可以拥有方法
type myInt int
func (m myInt) SayHello() {
fmt.Println("我是自定义类型里面的自定义方法")
}
注意
非本地类型不能定义方法,也就是说我们不能给别的包的类型定义方法
- 结构体的匿名字段,允许其成员字段在声明时没有字段名而只有类型
type Person struct {
string
int
}
func main() {
p1 := Person{"小王子", 18}
fmt.Println(p1) // {小王子 18}
fmt.Println(p1.string, p1.int) // 小王子 18
}
注意
匿名字段默认采用类型名作为字段名,结构体要求字段名称必须唯一,因此一个结构体中同种类型的匿名字段只能有一个
- 嵌套结构体
type Address struct {
Province string
City string
}
type User struct {
Name string
Address []Address
C types.B
// 内嵌结构体:自动获得该结构体的所有方法
types.B
// 内嵌接口:自动获得了ontext.Context接口的所有方法,如 Deadline()、Done()、Err()、Value()
context.Context
}
// 在 types 包下
type B struct {
Id int64
}
func main() {
user := User{
Name: "小王子",
Address: make([]Address,0),
}
user.Address = append(user.Address, Address{
Province: "北京",
City: "西城",
})
fmt.Println(user) // { 小王子 {北京 西城} {0} {0} <nil> }
// jsoniter "github.com/json-iterator/go"
// 嵌套的匿名字段名是去掉包名的部分
jsoniter.Marshal(&Person{B: types.B{Id: 100}}) // {"Id":100} — 匿名字段被提升到父级
jsoniter.Marshal(&Person{B: {Id: 100}}) // {"B":{"Id":100}} — 嵌套在 "B" 下
}
- 结构体的继承
type Animal struct {
Name string
}
func (a *Animal) run() {
fmt.Printf("%s 会运动!\n", a.Name)
}
type Dog struct {
Age int8
*Animal //通过嵌套匿名结构体实现继承,自动拥有 Animal 的方法
}
func (d *Dog) wang() {
fmt.Printf("%s 会汪汪汪~\n", d.Name)
}
func main() {
d1 := &Dog{
Age: 4,
Animal: &Animal{ //注意嵌套的是结构体指针
Name: "阿奇",
},
}
d1.wang() // 阿奇会汪汪汪~
d1.run() // 阿奇会动!
}
- 结构体和 Json 相互转换,序列化反序列化
import (
"encoding/json"
"fmt"
)
type Student struct {
ID int
Gender string
name string // 私有属性不能被 json 包访问
}
func main() {
var s1 = Student{
ID: 1, Gender: "男", name: "李四",
}
// 结构体对象转化成 Json 字符串
var s, _ = json.Marshal(s1)
jsonStr1 := string(s)
fmt.Println(jsonStr1) // {"ID":1,"Gender":"男"}
var jsonStr2 = `{"ID":1,"Gender":"男","name":"李四"}`
var student Student
err := json.Unmarshal([]byte(jsonStr2), &student)
if err != nil {
fmt.Printf("unmarshal err=%v\n", err)
}
fmt.Printf("student=%#v\n", student) // student=main.Student{ID:1, Gender:"男", name:""}
}
- 结构体标签 Tag,通过指定 tag 实现 json 序列化该字段时的key
type Student struct {
ID int `json:"id"` // 注意格式
Gender string `json:"gender"` // 注意格式
}
func main() {
var s1 = Student{
ID: 1, Gender: "男",
}
var s, _ = json.Marshal(s1)
jsonStr1 := string(s)
fmt.Println(jsonStr1) // {"id":1,"gender":"男"}
var jsonStr2 = `{"id":2,"gender":"女"}`
var student Student
err := json.Unmarshal([]byte(jsonStr2), &student)
if err != nil {
fmt.Printf("unmarshal err=%v\n", err)
}
fmt.Printf("student=%#v\n", student) // student=main.Student{ID:2, Gender:"女"}
}
# 接口 interface
- 接口的定义格式
type 接口名 interface{
方法名 1( 参数列表 1 ) 返回值列表 1
方法名 2( 参数列表 2 ) 返回值列表 2
…
}
# 方法名首字母大写且接口类型名首字母也是大写时,这个方法可以被接口所在的包之外的代码访问
type Usber interface {
Start()
Stop()
}
type Phone struct {
Name string
}
func (p Phone) Start() {
fmt.Println(p.Name, "开始工作")
}
func (p Phone) Stop() {
fmt.Println("phone 停止")
}
// 电脑的结构体
type Computer struct {
Name string
}
// 电脑的 Work 方法要求必须传入 Usb 接口类型数据
func (c Computer) Work(usb Usber) {
usb.Start()
usb.Stop()
}
func main() {
phone := Phone{
Name: "小米手机",
}
var p Usber = phone // phone 实现了 Usb 接口
p.Start()
computer := Computer{}
computer.Work(phone)
}
- 空接口
# 接口可以不定义任何方法,没有定义任何方法的接口就是空接口
# 空接口表示没有任何约束,因此任何类型变量都可以实现空接口
# 空接口可以表示任意数据类型
// 1、空接口变量可以接收任意的数据类型
var x interface{}
s := "你好 golang"
x = s
fmt.Printf("type:%T value:%v\n", x, x) // type:string value:你好 golang
i := 100
x = i
fmt.Printf("type:%T value:%v\n", x, x) // type:int value:100
b := true
x = b
fmt.Printf("type:%T value:%v\n", x, x) // type:bool value:true
// 2、空接口作为函数参数
func show(a interface{}) {
fmt.Printf("type:%T value:%v\n", a, a)
}
// 3、空接口作为 map 值
var studentInfo = make(map[string]interface{})
studentInfo["name"] = "张三"
studentInfo["age"] = 18
studentInfo["married"] = false
// 4、切片实现空接口
var slice = []interface{}{"张三", 20, true, 32.2}
注意
any{} 等同于 interface{}
- 类型断言
# 语法格式:
x.(T)
# x : 表示类型为 interface{}的变量
# T : 表示断言 x 可能是的类型
type Person interface {
Speak() string
Walk() string
}
type User struct {
Name string `json:"name"`
}
func (u User) Speak() string {
return "Hello, my name is " + u.Name
}
func (u User) Walk() string {
return "I am walking"
}
func main() {
var a interface{}
a = User{Name: "Alice"}
// 如果 T 是接口类型:断言会检查 x 的动态类型是否 实现了 T 接口所定义的所有方法
user, ok := a.(Person)
fmt.Printf("type:%T\n", user) // type:main.User
fmt.Println(user, ok) // {Alice} true
}
// 类型.(type)只能结合 switch 语句使用
func justifyType(x interface{}) {
switch v := x.(type) { // switch 形式:批量判断多种类型
case string:
fmt.Printf("x is a string,value is %v\n", v)
case int:
fmt.Printf("x is a int is %v\n", v)
case bool:
fmt.Printf("x is a bool is %v\n", v)
default:
fmt.Println("unsupport type!")
}
}
- 结构体值接收者和指针接收者实现接口的区别
type Usb interface {
Start()
}
type Phone struct {
Name string
}
// 值接收者:实例化后的结构体值类型和结构体指针类型都可以赋值给接口变量
func (p Phone) Start() {
fmt.Println(p.Name, "开始工作")
}
func main() {
phone1 := Phone{
Name: "小米手机",
}
var p1 Usb = phone1 // phone1 实现了 Usb 接口 phone1 是结构体值类型
p1.Start() // 小米手机 开始工作
phone2 := &Phone{
Name: "苹果手机",
}
var p2 Usb = phone2 // phone2 实现了 Usb 接口 phone2 是结构体指针类型
p2.Start() // 苹果手机 开始工作
}
// 指针接收者:实例化后结构体指针类型可以赋值给接口变量,结构体值类型没法赋值给接口变量
func (p *Phone) Start() {
fmt.Println(p.Name, "开始工作")
}
func main() {
/*
错误的写法
phone1 := Phone{
Name: "小米手机",
}
var p1 Usb = phone1
p1.Start()
*/
//正确写法
phone2 := &Phone{
Name: "苹果手机",
}
var p2 Usb = phone2 // phone2 实现了 Usb 接口 phone2 是结构体指针类型
p2.Start() // 苹果手机 开始工作
}
- 一个结构体实现多个接口
type AInterface interface {
GetInfo() string
}
type BInterface interface {
SetInfo(string, int)
}
type People struct {
Name string
Age int
}
func (p People) GetInfo() string {
return fmt.Sprintf("姓名:%v 年龄:%d", p.Name, p.Age)
}
func (p *People) SetInfo(name string, age int) {
p.Name = name
p.Age = age
}
func main() {
var people = &People{
Name: "张三", Age: 20,
}
// people 实现了 AInterface 和 BInterface
var p1 AInterface = people
var p2 BInterface = people
fmt.Println(p1.GetInfo())
p2.SetInfo("李四", 30)
fmt.Println(p1.GetInfo())
}
- 接口嵌套
type SayInterface interface {
say()
}
type MoveInterface interface {
move()
}
// 接口嵌套
type Animal interface {
SayInterface
MoveInterface
}
type Cat struct {
name string
}
func (c Cat) say() {
fmt.Println("喵喵喵")
}
func (c Cat) move() {
fmt.Println("猫会动")
}
func main() {
var x Animal
x = Cat{name: "花花"}
x.move()
x.say()
}
- 接口作为参数
import (
"gorm.io/gorm/logger"
)
type DBLogger struct{}
func (*DBLogger) Printf(format string, v ...any) {
// 实现略
}
func main() {
var w Writer
w = &DBLogger{}
// New方法的第一个参数是实现Printf接口的任意类型
logger.New(w)
// w 的类型如下:
// type Writer interface {
// Printf(string, ...interface{})
// }
}
- 在编译期检查结构体是否实现了要求的接口
type Session interface {
HasAuth(*types.HttpCtx, *Action) (bool, error)
HasPerm(*types.HttpCtx, *Action) (bool, error)
}
type DefaultSession struct { }
// 此代码用于在编译期检查 *DefaultSession 是否实现了 Session 接口
// 若未实现接口则直接编译报错,这是Go中确保接口实现的惯用技巧
var _ Session = (*DefaultSession)(nil)
// 或者
var _ Session = &DefaultSession{}
func (s *DefaultSession) HasAuth(ctx *types.HttpCtx, policy *Action) (bool, error) {
return true, nil
}
func (s *DefaultSession) HasPerm(ctx *types.HttpCtx, policy *Action) (bool, error) {
return true, nil
}
# 协程 goroutine
- 在一个Golang 程序的主线程上可以起多个协程。Golang 中多协程可以实现并行或者并发
- 在函数或者方法前面加 go 关键字就可创建一个协程。可以说 Golang 中的协程就是goroutine
并发 # 多线程程序在单核 CPU 上面运行就是并发
并行 # 多线程程序在多核CUP 上运行就是并行
# 如果线程数大于 CPU 核数,则多线程程序在多个 CPU 上面运行既有并行又有并发
- Goroutine 的使用
func test() {
for i := 1; i <= 10; i++ {
fmt.Println("tesst () hello,world " + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
func main() {
go test() // 开启了一个协程
for i := 1; i <= 10; i++ {
fmt.Println(" main() hello,golang" + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
注意
- 主线程执行完毕后即使协程没有执行完毕程序也会退出
- 协程可以在主线程没有执行完毕前提前退出,协程是否执行完毕不会影响主线程的执行
- sync.WaitGroup 可以实现主线程等待协程执行完毕
var wg sync.WaitGroup // 1、定义全局的 WaitGroup
func test() {
for i := 1; i <= 10; i++ {
fmt.Println("tesst () hello,world " + strconv.Itoa(i))
time.Sleep(time.Second)
}
wg.Done() // 4、goroutine 结束就登记-1
}
func main() {
wg.Add(1) // 2、启动一个 goroutine 就登记+1
go test()
for i := 1; i <= 10; i++ {
fmt.Println(" main() hello,golang" + strconv.Itoa(i))
time.Sleep(time.Second)
}
wg.Wait() // 3、等待所有登记的 goroutine 都结束
}
# runtime包
- runtime.Gosched():它让当前 Goroutine 暂停,让其他 Goroutine 运行,稍后再恢复运行
func say(s string) {
for i := 0; i < 5; i++ {
runtime.Gosched() // 主动让出 CPU,给其他 goroutine 运行机会
fmt.Println(s)
}
}
func main() {
go say("world")
say("hello")
}
// 输出 "hello" 和 "world" 会交替出现,而不是顺序执行
- runtime.Goexit():用于立即终止当前 Goroutine 的函数,但不会影响程序中的其他 Goroutine
func main() {
go func() {
defer fmt.Println("defer in goroutine")
fmt.Println("start")
runtime.Goexit()
fmt.Println("end") // 不会执行
}()
time.Sleep(100 * time.Millisecond)
fmt.Println("main exit")
}
// 输出:
// start
// defer in goroutine
// main exit
- runtime.GOMAXPROCS:在同一时刻,最多能有几个 Goroutine 被并行执行
func main() {
// 获取当前的 GOMAXPROCS 值(参数 n <= 0)
current := runtime.GOMAXPROCS(0)
fmt.Printf("当前 P 的数量: %d\n", current)
// 设置新的 GOMAXPROCS 值(参数 n > 0)
// 返回值是修改前的值
old := runtime.GOMAXPROCS(4)
fmt.Printf("修改前的 P 数量: %d\n", old)
fmt.Printf("修改后的 P 数量: %d\n", runtime.GOMAXPROCS(0))
}
# 管道 Channel
管道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序
# 管道提供了 goroutine 间的通讯方式,可以使用channel 在多个 goroutine 之间传递消息
# 如果说 goroutine 是 Go 程序并发的执行体,channel 就是它们之间的连接
# channel 是可以让一个 goroutine 发送特定值到另一个 goroutine 的通信机制
- channel 类型:引用类型
// 声明管道类型的格式如下:
var 变量 chan 元素类型
// 举几个例子:
var ch1 chan int // 声明一个传递整型的管道
var ch2 chan bool // 声明一个传递布尔型的管道
var ch3 chan []int // 声明一个传递 int 切片的管道
- 创建 channel
//创建一个能存储 10 个 int 类型数据的管道
ch1 := make(chan int, 10)
//创建一个能存储 4 个 bool 类型数据的管道
ch2 := make(chan bool, 4)
//创建一个能存储 3 个[]int 切片类型数据的管道
ch3 := make(chan []int, 3)
// Done() 方法返回一个只读的 channel,该 channel 的元素类型是 struct{}(空结构体)
Done() <-chan struct{}
- channel 操作:发送(send)、接收(receive)和关闭(close)
// 发送(将数据放在管道内)
ch <- 10 // 把 10 发送到 ch 中
// 接收(从管道内取值)
x := <- ch // 从 ch 中接收值并赋值给变量 x
<-ch // 从 ch 中接收值,忽略结果
// 关闭管道
close(ch)
// 通道关闭后还可以取数据
注意
- 只有在通知接收方 goroutine 所有的数据都发送完毕的时候才需要关闭管道
- 管道是可以被垃圾回收机制回收的,它和关闭文件是不一样的,但关闭管道不是必须的
# 管道阻塞
// 管道阻塞具体代码如下:
func main() {
ch := make(chan int, 1)
ch <- 10
ch <- 12
fmt.Println("发送成功")
}
// 解决办法:
func main() {
ch := make(chan int, 1)
ch <- 10 //放进去
<-ch //取走
ch <- 12 //放进去
<-ch //取走
ch <- 17 //还可以放进去
fmt.Println("发送成功")
}
- 无缓冲的管道:只有在有人接收值的时候才能发送值
# 如果创建管道的时候没有指定容量,那么我们可以叫这个管道为无缓冲的管道或阻塞的管道
# 作用:
# 同步:强制发送方和接收方同时就绪,实现 goroutine 间的精准同步
# 数据安全传递:保证数据在发送方和接收方之间直接传递,没有中间缓存,避免了数据竞争
# 事件通知:可用于 goroutine 之间的完成信号、停止信号等场景,实现协作式并发
// 下面这段代码能够通过编译,但是执行的时候会出现错误
func main() {
ch := make(chan int)
ch <- 10
fmt.Println("发送成功")
}
// 作用示例1:goroutine 之间的同步与数据传递
// 一个 goroutine 负责发送数据,另一个 goroutine 负责接收数据
// 发送操作会阻塞,直到接收方准备好;接收操作也会阻塞,直到发送方发送数据
// 这保证了数据传递的原子性和同步性
ch := make(chan int)
// 启动一个发送数据的 goroutine
go func() {
fmt.Println("发送方:准备发送数据...")
time.Sleep(2 * time.Second) // 模拟一些准备工作
ch <- 42 // 发送数据,此处会阻塞直到接收方接收
fmt.Println("发送方:数据已发送")
}()
// 主 goroutine 作为接收方
fmt.Println("主 goroutine:准备接收数据...")
value := <-ch // 接收数据,此处会阻塞直到发送方发送
fmt.Println("主 goroutine:接收到数据:", value)
time.Sleep(1 * time.Second)
// 作用示例2:利用无缓冲通道实现 goroutine 的完成通知
// 主 goroutine 执行 <-done 时被阻塞,直到 worker goroutine 向通道发送数据
// worker 完成工作后通过 done <- struct{}{} 发送信号,主 goroutine 收到信号后继续执行
// 这里使用 struct{}{} 是因为我们只关心事件的发生,不需要传递实际数据,体现了无缓冲通道的同步特性
func worker(done chan struct{}) {
fmt.Println("worker:开始工作...")
time.Sleep(2 * time.Second) // 模拟耗时任务
fmt.Println("worker:工作完成")
done <- struct{}{} // 发送完成信号,struct{}{} 是空结构,不占内存
}
func main() {
done := make(chan struct{}) // 创建无缓冲通道,用于信号传递
go worker(done)
// 等待 worker 完成
<-done
fmt.Println("主 goroutine:收到完成信号,退出")
}
- 有缓冲的管道
// 在使用make 函数初始化管道的时候为其指定管道的容量
// 使用带缓冲的通道(例如 make(chan int, 1))确实可以实现类似互斥锁的效果
// 但是性能较重,涉及调度和内存操作,不如sync.Mutex轻量,更快
func main() {
ch := make(chan int, 1) // 创建一个容量为 1 的有缓冲区管道
ch <- 10
fmt.Println("发送成功")
}
// 典型作用:生产者-消费者模式
// 缓冲通道常用于生产者与消费者速度不匹配的场景
// 生产者可以快速生产并放入缓冲区,消费者以自己的节奏消费,双方互不阻塞(除非缓冲区满或空)
func producer(ch chan<- int) {
for i := 0; i < 10; i++ {
fmt.Printf("生产 %d\n", i)
ch <- i // 缓冲区未满时不会阻塞
time.Sleep(100 * time.Millisecond) // 模拟生产耗时
}
close(ch)
}
func consumer(ch <-chan int) {
for num := range ch {
fmt.Printf("消费 %d\n", num)
time.Sleep(300 * time.Millisecond) // 模拟消费耗时(比生产慢)
}
}
func main() {
ch := make(chan int, 5) // 缓冲区大小为5
go producer(ch)
consumer(ch)
}
- 从管道循环取值
// 1、for range 循环遍历管道数据
func main() {
var ch1 = make(chan int, 5)
for i := 0; i < 5; i++ {
ch1 <- i + 1
}
// 关闭管道,如果没有关闭管道就会报错 fatal error: all goroutines are asleep - deadlock!
close(ch1)
// 通过 for range 来遍历管道数据 管道没有 key
for val := range ch1 {
fmt.Println(val)
}
}
// 2、for 循环遍历管道数据,可以不用关闭
func main() {
var ch1 = make(chan int, 5)
for i := 0; i < 5; i++ {
ch1 <- i + 1
}
for i := 0; i < 5; i++ {
fmt.Println(<-ch1)
}
}
- Goroutine 结合 Channel 管道
// 定义两个方法,一个方法给管道里面写数据,一个给管道里面读取数据。要求同步进行
var wg sync.WaitGroup
func fn1(intChan chan int) {
for i := 0; i < 100; i++ {
intChan <- i + 1
fmt.Println("writeData 写入数据-", i+1)
time.Sleep(time.Millisecond * 100)
}
close(intChan)
wg.Done()
}
func fn2(intChan chan int) {
for v := range intChan {
fmt.Printf("readData 读到数据=%v\n", v)
time.Sleep(time.Millisecond * 50)
}
wg.Done()
}
func main() {
allChan := make(chan int, 100)
wg.Add(1)
go fn1(allChan)
wg.Add(1)
go fn2(allChan)
wg.Wait()
fmt.Println("读取完毕...")
}
- 单向管道
// 在默认情况下下,管道是双向
var ch chan int //可读可写
var wg sync.WaitGroup
// 只写通道
func fn1(ch chan<- int) {
for i := 0; i < 5; i++ {
ch <- i
fmt.Println("Sent:", i)
time.Sleep(1 * time.Second)
}
close(ch)
wg.Done()
}
// 只读通道
func fn2(ch <-chan int) {
for v := range ch {
fmt.Println("Received:", v)
time.Sleep(1 * time.Second)
}
wg.Done()
}
func main() {
ch := make(chan int, 3)
wg.Add(1)
go fn1(ch)
wg.Add(1)
go fn2(ch)
wg.Wait()
}
注意
即使写入时间比读取时间慢,也不会出问题,因为管道是现成安全的,会自动等待。
- select 多路复用
// 多路复用可以解决从管道取数据的阻塞问题,传统的方法在遍历管道时,如果不关闭会阻塞而导致 deadlock
// 在实际开发中,可能我们不好确定什么关闭该管道
intChan := make(chan int, 10)
for i := 0; i < 10; i++ {
intChan <- i
}
stringChan := make(chan string, 5)
for i := 0; i < 5; i++ {
stringChan <- "hello" + fmt.Sprintf("%d", i)
}
for {
select {
// 会随机从 intChan 和 stringChan 中取数据,直至没有数据执行 default
// 使用 select 来获取 channel 里面的数据的时候不需要关闭 channel
// 因为 for 是死循环,一定要在 default 中添加 return
case v := <-intChan:
fmt.Printf("从 intChan 读取的数据%d\n", v)
time.Sleep(time.Second)
case v := <-stringChan:
fmt.Printf("从 stringChan 读取的数据%s\n", v)
time.Sleep(time.Second)
default:
fmt.Printf("都取不到了,不玩了, 程序员可以加入逻辑\n")
time.Sleep(time.Second)
return
}
}
注意
使用 select 语句能提高代码的可读性
- 可处理一个或多个 channel 的发送/接收操作
- 如果多个 case 同时满足,select 会随机选择一个
- 对于没有 case 的 select{}会一直等待,可用于阻塞 main 函数
- 处理协程中出现的错误,防止影响程序执行
func sayHello() {
for i := 0; i < 10; i++ {
time.Sleep(time.Second)
fmt.Println("hello,world")
}
}
func test() {
// 这里我们可以使用 defer + recover
defer func() {
// 捕获 test 抛出的 panic
if err := recover(); err != nil {
fmt.Println("test() 发生错误", err)
}
}()
// 定义了一个 map
var myMap map[int]string
myMap[0] = "golang" // error
}
func main() {
go sayHello()
go test()
for i := 0; i < 10; i++ {
fmt.Println("main() ok=", i)
time.Sleep(time.Second)
}
}
# 并发安全和锁
// 以下代码运行时正常
// go build main.go 编译成 main.exe 执行也正常
// go build -race main.go 编译时看看程序有没有竞争关系,发现报错
var wg sync.WaitGroup
var count int = 0
func fn() {
count++
fmt.Println(count)
time.Sleep(1 * time.Second)
wg.Done()
}
func main() {
for i := 0; i < 20; i++ {
wg.Add(1)
go fn()
}
wg.Wait()
}
// 如果要计算 1-60 的各个数的阶乘,并且把各个数的阶乘放入到 map 中
// 只使用 Goroutine 实现,运行的时候可能会出现资源争夺问题 concurrent map writes
- 互斥锁
// 互斥锁是一种常用的控制共享资源访问的方法,它能够保证同时只有一个 goroutine 可以访问共享资源
// Go 语言中使用 sync 包的 Mutex 类型来实现互斥锁
var (
myMap = make(map[int]int)
wg sync.WaitGroup
lock sync.Mutex
)
// test 函数就是计算 n 的阶乘, 让将这个结果放入到 myMap
func test(n int) {
res := 1
for i := 1; i <= n; i++ {
res *= i
}
//加锁
lock.Lock()
myMap[n] = res
//解锁
lock.Unlock()
wg.Done()
}
func main() {
for i := 1; i <= 60; i++ {
wg.Add(1)
go test(i)
}
wg.Wait()
for i, v := range myMap {
fmt.Printf("map[%d]=%d\n", i, v)
}
}
- 读写互斥锁
// 读写锁分为两种:读锁和写锁,写的时候一次只能写一个,读的时候可以并发的读
// 当一个 goroutine 获取读锁之后,其他的 goroutine 如果是读锁会继续获得锁,如果是写锁就会等待
// 当一个 goroutine 获取写锁之后,其他的 goroutine 无论是读锁还是写锁都会等待
// 读写锁在 Go 语言中使用 sync 包中的 RWMutex 类型
var (
x int64
wg sync.WaitGroup
lock sync.Mutex
rwlock sync.RWMutex
)
func write() {
// lock.Lock() // 加互斥锁
rwlock.Lock() // 加写锁
x = x + 1
time.Sleep(10 * time.Millisecond) // 假设读操作耗时 10 毫秒
rwlock.Unlock() // 解写锁
// lock.Unlock() // 解互斥锁
wg.Done()
}
func read() {
// lock.Lock() // 加互斥锁
rwlock.RLock() // 加读锁
time.Sleep(time.Millisecond) // 假设读操作耗时 1 毫秒
rwlock.RUnlock() // 解读锁
// lock.Unlock() // 解互斥锁
wg.Done()
}
func main() {
start := time.Now()
for i := 0; i < 10; i++ {
wg.Add(1)
go write()
}
for i := 0; i < 1000; i++ {
wg.Add(1)
go read()
}
wg.Wait()
end := time.Now()
fmt.Println(end.Sub(start))
}
# 原子操作(atomic包)
# 代码中的加锁操作因为涉及内核态的上下文切换会比较耗时、代价比较高
# 针对基本数据类型可以使用原子操作来保证并发安全,因为原子操作是Go语言提供的方法在用户态就可以完成
# 性能比加锁操作更好。Go语言中原子操作由内置的标准库sync/atomic提供
func main(){
start := time.now()
for i :=0; i < 10000; i++ {
wg.Add(1)
// go add() // 普通版add函数不是并发安全的
// go mutexAdd() //加锁版add函数 是并发安全的,但是加锁性能开销大
go atomicAdd() //原子操作版add函数是并发安全,性能优于加锁版
}
wg.wait()
end := time.Now()
fmt.Println(x)
fmt.Println(end.Sub(start))
}
# 反射 reflect
- 反射是指在程序运行期间对程序本身进行访问和修改的能力
- reflect 包 提供了reflect.TypeOf 和reflect.ValueOf 两个重要函数来获取任意对象的 Type 和 Value
# reflect.TypeOf()获取任意值的类型对象
- reflect.TypeOf()函数可以接受任意类型参数 interface{},获得其类型对象(reflect.Type)
- 程序通过类型对象可以访问任意值的类型信息
func reflectType(x interface{}) {
v := reflect.TypeOf(x)
fmt.Printf("reflect.Type:%v\n", v)
}
// 类型对象:reflect.Type
func main() {
var a float32 = 12.5
reflectType(a) // reflect.Type:float32
var b int64 = 100
reflectType(b) // reflect.Type:int64
}
# type Name 和 type Kind
- 在反射中关于类型还划分为两种:类型(Type)和种类(Kind)
- 因为在Go 语言中我们可以使用 type 关键字构造很多自定义类型,而种类(Kind)就是指底层的类型
- 在反射中,当需要区分指针、结构体等大品种的类型时,就会用到种类(Kind)
- Go 语言的反射中像数组、切片、Map、指针等类型的变量,它们的.Name()都是返回空
func reflectType(x interface{}) {
t := reflect.TypeOf(x)
fmt.Printf("reflect.Type:%v Name:%v Kind:%v\n", t, t.Name(), t.Kind())
}
type myInt int64
type Person struct {
Name string
Age int
}
type Animal struct {
Name string
}
func main() {
var a *float32 // 指针
var b myInt // 自定义类型
var c rune // 类型别名
reflectType(a) // reflect.Type:*float32 Name: Kind:ptr
reflectType(b) // reflect.Type:main.myInt Name:myInt Kind:int64
reflectType(c) // reflect.Type:int32 Name:int32 Kind:int32
var d = Person{
Name: "itying",
Age: 18,
}
var e = Animal{Name: "小花"}
reflectType(d) // reflect.Type:main.Person Name:Person Kind:struct
reflectType(e) // reflect.Type:main.Animal Name:Animal Kind:struct
var f = []int{1, 2, 3, 4, 5}
reflectType(f) // reflect.Type:[]int Name: Kind:slice
// reflect.New(tp) → 创建 *T 指针,如 *dao.Payment
// .Elem() → 解引用得到 T,如 dao.Payment
// .Interface() → 转为 any 接口值
// 返回值类型,如 dao.Payment{}
reflect.New(tp).Elem().Interface()
}
注意
reflect.Pointer 只是 reflect.Ptr 的可读性别名,二者无差别
# reflect.ValueOf()
reflect.ValueOf()返回的是 reflect.Value 类型,其中包含了原始值的值信息
func reflectValue(x interface{}) {
v := reflect.ValueOf(x)
k := v.Kind()
switch k {
case reflect.Int64:
// v.Int()从反射中获取整型的原始值
fmt.Printf("type is int64, value is %d\n", v.Int())
case reflect.Float32:
// v.Float()从反射中获取浮点型的原始值
fmt.Printf("type is float32, value is %f\n", v.Float())
case reflect.Float64:
// v.Float()从反射中获取浮点型的原始值
fmt.Printf("type is float64, value is %f\n", v.Float())
}
}
func main() {
var a float32 = 3.14
var b int64 = 100
reflectValue(a) // type is float32, value is 3.140000
reflectValue(b) // type is int64, value is 100
// 将 int 类型的原始值转换为 reflect.Value 类型
c := reflect.ValueOf(10)
fmt.Printf("type c :%T\n", c) // type c :reflect.Value
}
# 通过反射设置变量的值
- 需要注意函数参数传递的是值拷贝,必须传递变量地址才能修改变量值
- 反射中使用专有的 Elem() 方法获取任何“容器类型”的内部元素类型
func reflectSetValue1(x interface{}) {
v := reflect.ValueOf(x)
if v.Kind() == reflect.Int64 {
v.SetInt(200) // 修改的是副本,reflect 包会引发 panic
}
}
func reflectSetValue2(x interface{}) {
v := reflect.ValueOf(x)
// 反射中使用 Elem()方法获取指针对应的值
if v.Elem().Kind() == reflect.Int64 {
v.Elem().SetInt(200)
}
}
func main() {
var a int64 = 100
// panic: reflect: reflect.Value.SetInt using unaddressable value
// reflectSetValue1(a)
reflectSetValue2(&a)
fmt.Println(a) // 200
// Elem() 方法获取其元素类型
v = reflect.TypeOf([]*dao.Payment{})
v.Kind() = Slice
v.Elem() = *dao.Payment // (剥一层,取切片的元素类型)
v.Elem().Kind() = Pointer // (元素是指针)
v.Elem().Elem() = dao.Payment // (剥一层,取指针指向的类型)
}
- v.Elem() 和 reflect.Indirect(v) 的区别
// 操作的是 reflect.Type(类型的反射),用于获取指针类型指向的元素类型
// 是“强硬”的解引用:它要求 v 必须是指针、接口或容器类型,否则直接 Panic
Type.Elem()
// 如下:
func reflectType(v reflect.Type) reflect.Type {
if v.Kind() == reflect.Pointer {
v = v.Elem() // v 是 reflect.Type,只能用 Elem()
}
return v
}
// 操作的是 reflect.Value(值的反射),用于解引用一个指针值,返回其指向的值
// 是“温和”的解引用:如果 v 是指针,它就解引用;如果 v 不是指针,它就原样返回,绝不 Panic
reflect.Indirect(v Value)
// 如下:
reflect.Indirect(reflect.ValueOf(dest))
# 与结构体相关的方法
任意值通过 reflect.TypeOf() 获得反射对象信息后,如果它的类型是结构体,可以通过反射值对象 reflect.Type 的 NumField() 和 Field() 方法获得结构体成员的详细信息
- StructField 类型:来描述结构体中的一个字段的信息
type StructField struct {
// 参见 http://golang.org/ref/spec#Uniqueness_of_identifiers
Name string // Name 是字段的名字
PkgPath string // PkgPath 是非导出字段的包路径,对导出字段该字段为""
Tag StructTag // 字段的标签
Offset uintptr // 字段在结构体中的字节偏移量
Index []int // 用于 Type.FieldByIndex 时的索引切片
Anonymous bool // 是否匿名字段
}
- 获取结构体属性,获取执行结构体方法
type Student struct {
Name string `json:"name"`
Age int `json:"age"`
Score int `json:"score"`
}
func (s Student) GetInfo() string {
str := fmt.Sprintf("姓名:%v 年龄:%v 成绩:%v", s.Name, s.Age, s.Score)
fmt.Println(str)
return str
}
func (s *Student) SetInfo(name string, age int, score int) {
s.Name = name
s.Age = age
s.Score = score
}
func (s *Student) Print() {
fmt.Println("打印方法...")
}
// 属性
func PrintStructField(s interface{}) {
t := reflect.TypeOf(s)
// v := reflect.ValueOf(s)
// 不是结构体也不是指针类型的结构体
if t.Kind() != reflect.Struct && t.Elem().Kind() != reflect.Struct {
fmt.Println("传入的不是结构体")
return
}
// 1、通过类型变量里面的 Field 可以获取结构体的字段
field0 := t.Field(0)
fmt.Println(field0.Name)
fmt.Println(field0.Type)
fmt.Println(field0.Tag.Get("json"))
// 2、通过类型变量里面的 FieldByName 可以获取结构体的字段
field1, _ := t.FieldByName("Age")
fmt.Println(field1.Name)
fmt.Println(field1.Type)
fmt.Println(field1.Tag.Get("json"))
// 3、获取到该结构体有几个字段
num := t.NumField()
fmt.Println("字段数量:", num)
}
// 方法
func PrintStructFn(s interface{}) {
t := reflect.TypeOf(s)
v := reflect.ValueOf(s)
if t.Kind() != reflect.Struct && t.Elem().Kind() != reflect.Struct {
fmt.Println("传入的不是结构体")
return
}
// 1、通过类型变量里面的 Method 可以获取结构体的方法
var tMethod = t.Method(0) //注意
fmt.Println(tMethod.Name)
fmt.Println(tMethod.Type)
// 2、通过类型变量获取这个结构体有多少个方法
fmt.Println(t.NumMethod())
//3 、执行方法 (注意需要使用值变量,并且要注意参数)
// v.Method(0).Call(nil)
v.MethodByName("Print").Call(nil)
// 4、执行方法传入参数 (注意需要使用值变量,并且要注意参数)
var params []reflect.Value // 声明了 []reflect.Value
params = append(params, reflect.ValueOf("张三"))
params = append(params, reflect.ValueOf(22))
params = append(params, reflect.ValueOf(100))
// 传入的参数是 []reflect.Value, 返回[]reflect.Value
v.MethodByName("SetInfo").Call(params)
// 5、执行方法获取方法的值
info := v.MethodByName("GetInfo").Call(nil)
fmt.Println(info)
}
func main() {
stu1 := Student{
Name: "小明", Age: 15, Score: 98,
}
// PrintStructField(stu1)
PrintStructFn(&stu1)
}
- 修改结构体方法
type Student struct {
Name string `json:"name"`
Age int `json:"age"`
Score int `json:"score"`
}
func (s Student) GetInfo() string {
str := fmt.Sprintf("姓名:%v 年龄:%v 成绩:%v", s.Name, s.Age, s.Score)
return str
}
// 反射修改结构体属性的值
func reflectChangeStruct(s interface{}) {
t := reflect.TypeOf(s)
v := reflect.ValueOf(s)
if t.Elem().Kind() != reflect.Struct {
fmt.Println("传入的不是结构体指针类型")
return
}
name := v.Elem().FieldByName("Name")
name.SetString("李四") // 设置值
age := v.Elem().FieldByName("Age")
age.SetInt(20) // 设置值
}
func main() {
stu1 := Student{
Name: "小明",
Age: 15,
Score: 98,
}
// PrintStructField(stu1)
reflectChangeStruct(&stu1)
fmt.Println(stu1.GetInfo())
}
# 泛型 [T any]
- 泛型解决了函数、方法、结构体和接口的复用性问题
- 并在编译时提供对不特定数据类型的类型安全支持
# 类型参数
使用方括号 [] 声明类型参数:[T any] 声明了一个类型参数 T,any 表示T 可以是任何类型
func getData[T any](value T) T {
return value
}
func main() {
str1 := getData("hello")
fmt.Println(str1) // str1 是 string 类型
num2 := getData(123)
fmt.Println(num2) // num2 是 int 类型
}
# 使用接口定义类型约束
type Number interface {
int | int64 | float64
}
func Add[T Number](a, b T) T {
return a + b
}
func main() {
fmt.Println(Add(1, 2))
fmt.Println(Add(1.1, 2.2))
// fmt.Println(Add("11", "32432")) //错误
}
# 泛型结构体
// 泛型结构体
type Container[T any] struct {
Value T
}
// 泛型方法
func (c *Container[T]) Set(value T) {
c.Value = value
}
func (c *Container[T]) Get() T {
return c.Value
}
func main() {
// 使用 int 类型
intContainer := Container[int]{}
intContainer.Set(42)
fmt.Println("Int value:", intContainer.Get()) // 输出: 42
// 使用 string 类型
strContainer := Container[string]{}
strContainer.Set("Hello, Generics!")
fmt.Println("String value:", strContainer.Get()) // 输出: Hello, Generics!
}
- ~int 匹配底层类型为 int 的所有类型,包括 int 本身、类型别名和自定义类型
// 自定义约束
type Ordered interface {
~int | ~int8 | ~int16 | ~int32 | ~int64 |
~uint | ~uint8 | ~uint16 | ~uint32 | ~uint64 |
~uintptr | ~float32 | ~float64 | ~string
}
// 泛型类
type MinClass[T Ordered] struct {
List []T
}
// 添加方法
func (m *MinClass[T]) Add(list []T) {
m.List = list
}
// 求最小值方法
func (m *MinClass[T]) Min() T {
if len(m.List) == 0 {
var zero T
return zero
}
tempMin := m.List[0]
for i := 1; i < len(m.List); i++ {
if m.List[i] < tempMin {
tempMin = m.List[i]
}
}
return tempMin
}
func main() {
// 字符串类型
obj := &MinClass[string]{}
obj.Add([]string{"1", "2", "3"})
fmt.Println(obj.Min())
// 整数类型示例
objInt := &MinClass[int]{}
objInt.Add([]int{8, 2, 3, 5, 1})
fmt.Println(objInt.Min())
}
# 泛型接口
type Usber[T any] interface {
Start()
Stop()
GetDevice() T // 添加一个获取具体设备的方法
}
type Phone struct {
Name string
}
func (p Phone) Start() {
fmt.Println(p.Name, "开始工作")
}
func (p Phone) Stop() {
fmt.Println("phone 停止")
}
func (p Phone) GetDevice() Phone {
return p
}
type Camera struct {
Brand string
}
func (c Camera) Start() {
fmt.Println(c.Brand, "相机 开始工作")
}
func (c Camera) Stop() {
fmt.Println(c.Brand, "相机 停止工作")
}
func (c Camera) GetDevice() Camera {
return c
}
// 电脑结构体 - 使用泛型
type Computer[T any] struct {
Name string
}
// 电脑的 Work 方法使用泛型接口
func (c Computer[T]) Work(usb Usber[T]) {
usb.Start()
usb.Stop()
// 可以通过 GetDevice 获取具体的设备信息
device := usb.GetDevice()
fmt.Printf("设备信息: %+v\n", device)
}
func main() {
phone := Phone{
Name: "小米手机",
}
camera := Camera{
Brand: "佳能",
}
// 使用泛型电脑
computer := Computer[Phone]{Name: "我的电脑"}
computer.Work(phone)
// 对于不同类型的设备,需要创建对应的电脑实例
computer2 := Computer[Camera]{Name: "我的电脑"}
computer2.Work(camera)
fmt.Println("\n--- 使用通用函数 ---")
}
# 套接字 Socket
常用的Socket类型有两种:
流式Socket # 流式是一种面向连接的Socket,针对于面向连接的TCP服务应用
数据报式Socket # 数据报式Socket是一种无连接的Socket,针对于无连接的UDP服务应用
# TCP编程
一个TCP服务端可以同时连接很多个客户端,因为Go语言中创建多个goroutine实现并发非常方便和高效,所以我们可以每建立一次链接就创建一个goroutine去处理。TCP有粘包的问题。
- 使用Go语言的net包实现的TCP服务端代码如下:
func process(conn net.Conn){
defer conn.Close() // 关闭连接
for {
reader := bufio.NewReader(conn)
var buf [128]byte
n, err := reader.Read(buf[:]) // 读取数据
if err != nil {
fmt.Println("read from client failed, err:",err)
break
}
recvStr := string(buf[:n])
fmt.Println("收到client端发来的的数据:", recvStr)
conn.Write([]byte(recvStr)) // 发送数据
}
}
func main(){
listen, err := net.Listen("tcp","127.0.0.1:20000")
if err != nill {
fmt.Println("listen failed, err:",err)
return
}
for {
conn, err := listen.Accept() // 建立连接
if err != nil {
fmt.Println("accept failed, err:",err)
continue
}
go process(conn) // 启动一个 goroutine 处理连接
}
}
- 使用Go语言的net包实现的TCP客户端代码如下:
func main(){
listen, err := net.Dial("tcp","127.0.0.1:20000")
if err != nill {
fmt.Println("err:",err)
return
}
defer conn.Close() // 关闭连接
inputReader := bufio.NewReader(os.Stdin)
for {
input, _ := inputReader.ReadString('\n') // 读取用户输入
inputInfo := string.Trim(input, "\r\n")
if strings.ToUpper(inputInfo) == "Q" {
return // 输入Q就退出
}
_, err = conn.Write([]byte(inputInfo)) // 发送数据
if err != nil {
return
}
buf := [512]byte{}
n, err := conn.Read(buf[:]) // 建立连接
if err != nil {
fmt.Println("recv failed, err:",err)
return
}
fmt.Println(string(buf[:n]))
}
}
# UDP编程
UDP是一种无连接的传输层协议,不需要建立连接就能直接进行数据发送和接收,属于不可靠的、没有时序的通信,但是UDP协议的实时性比较好,通常用于视频直播相关领域。
- 使用Go语言的net包实现的UDP服务端代码如下:
func main(){
listen, err := net.ListenUDP("udp", &net.UDPAddr{
IP: net,IPv4(0,0,0,0),
Port: 30000,
})
if err != nil {
fmt.Println("listen failed, err:",err)
return
}
defer listen.Close() // 关闭连接
for {
var data [1024]byte
n, addr, err := listen.ReadFromUDP(data[:]) // 接收数据
if err != nil {
fmt.Println("read udp failed, err:",err)
continue
}
fmt.Printf("data:%v addr:%v count:%v\n", string(data[:n]), addr, n)
_ , err = listen.WriteToUDP(data[:n], addr) // 发送数据
if err != nil {
fmt.Println("write to udp failed, err:",err)
continue
}
}
}
- 使用Go语言的net包实现的UDP客户端代码如下:
func main(){
socket, err := net.DialUDP("udp", nil, &net.UDPAddr{
IP: net,IPv4(0,0,0,0),
Port: 30000,
})
if err != nil {
fmt.Println("连接服务端失败, err:",err)
return
}
defer socket.Close()
sendData := []byte("Hello server")
_, err = socket.Write(sendData) // 发送数据
if err != nil {
fmt.Println("发送数据失败, err:",err)
return
}
data := make([]byte, 4096)
n, remoteAddr, err := socket.ReadFromUDP(data) // 接收数据
if err != nil {
fmt.Println("接收数据失败, err:",err)
return
}
fmt.Printf("recv:%v addr :%v count:%v\n", string(data[:n]), remoteAddr, n)
}
# WebSocket编程
WebSocket (opens new window) 是一种在单个TCP连接上进行全双工通信的协议
# WebSocket使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据
# 浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输
# 需要安装第三方包:
go get -u -v github.com/gorilla/websocket
# 上下文 context
# 一个请求从 handler 进来,service 要传 ctx,repo 要传 ctx,RPC client 要传 ctx
# 连中间那些根本不关心超时和取消的函数,也要机械地把 ctx 往下递
显式传给每个函数,通常作为第一个参数,命名为 ctx,context.Context 接口摊开看,只有四个方法:
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key any) any
}
# context.Background()
context.Background() 是一个空的根 Context,它通常被用作整个 Context 树的顶层节点
- 不会被取消(没有 cancel 函数)
- 没有携带任何值
- 也没有截止时间(Deadline)
func main() {
ctx1 := context.Background() // 0x55a3e0
ctx2 := context.Background() // 0x55a3e0
fmt.Printf("%p\n%p\n", ctx1, ctx2) // 两次打印地址相同
}
# context.Background() 在项目任何地方调用,返回的都是同一个单例对象
# 从这个根派生出来的子Context(如WithCancel的返回值)则是不同的实例,每个请求/任务有自己的生命周期
# 不同派生出来的子 Context 关闭时互不影响
# context.WithCancel(context.Background())
创建一个可以随时通过调用返回的 cancel 函数来取消的 Context 树根节点
context.Background()
# 返回一个空的根 Context(通常用于主函数、初始化或测试中,作为顶层 Context)
context.WithCancel(parent)
# 接收一个父 Context,返回:一个派生出来的 Context、一个取消函数 cancel
# 被调用者拿到 ctx,只能通过 Done()、Err() 观察取消
# 创建派生 context 的调用者拿到 cancel,负责结束这个生命周期
# 如果 Cancel() 是 Context 接口上的方法,任何下游函数只要拿到 ctx,都能取消它
# 子操作就有机会取消父操作。调用树会乱
// 创建一个可取消的 Context
ctx, cancel := context.WithCancel(context.Background())
defer cancel() // 确保函数退出时释放资源
// 启动一个 goroutine,传入 ctx
go func(ctx context.Context) {
for {
select {
case <-ctx.Done(): // 返回一个只读 channel
fmt.Println("收到取消信号,退出")
return
default:
// 模拟工作
}
}
}(ctx)
// 当需要取消时(例如用户主动停止或超时)
time.AfterFunc(3*time.Second, cancel) // 3秒后自动取消
注意
必须调用 cancel # 否则子 Context 及其关联的 goroutine 可能一直存在,造成内存泄漏
多次调用 cancel 是安全的 # 只有第一次调用会生效,后续调用无影响
cancel() 不是强杀,只是通知
# 只是发出取消信号、关闭 Done、记录错误原因、释放关联资源
# goroutine 退不退出,取决于代码有没有协作式检查 ctx.Done()
# context.WithValue(parent, key, val)
- context values 只用于跨 API 和进程边界传递 request-scoped data,不用于给函数传可选参数
- 每个 HTTP 请求都有独立的 context 链,context.WithValue 创建的是新上下文,不会影响其他请求
ctx = context.WithValue(ctx, requestIDKey{}, "req-123") // 设置值
requestID, _ := ctx.Value(requestIDKey{}).(string) // 深层函数可以取
# 其他
context.Background() // 根 Context,不可取消 顶层 Context,如 main()、测试
context.TODO() // 占位符,不可取消 不确定用哪个 Context 时
context.WithTimeout(parent, d) // 超时自动取消 设置请求/操作的最长等待时间
context.WithDeadline(parent, t) // 指定时间点取消 精确到时间点的取消
常用的包 →